[Pytroch] Multi GPU Training
·
ML & DL/PyTorch
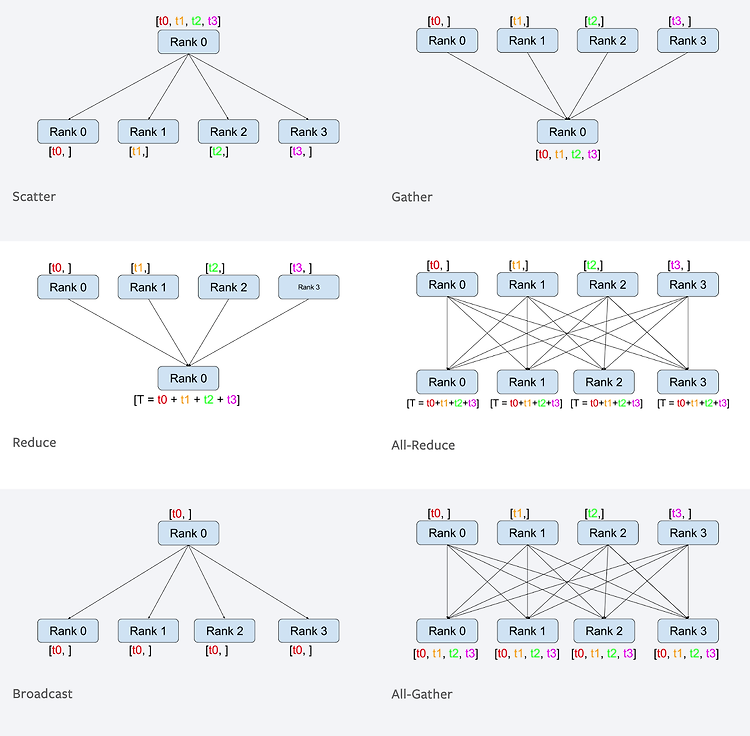
Data Parallel (DP) 사용법 ... model = resnet18().to(device) model = torch.nn.DataParallel(model) ... 장점 위 예시처럼 매우 간단하게 사용이 가능하다 단점 메모리 사용량 증가 : 각 GPU에서 모델의 복사본을 만들어 메모리를 사용하기 떄문에 GPU의 수가 증가할 수록 메모리 사용량이 증가 통신 병목 현상 : 각 GPU에서 연산을 수행하고 연산 결과를 하나의 GPU로 모은 후에 모델을 업데이트 하기 때문에 GPU간 데이터를 복사하고 통신하는 데 시간이 소요된다. 또한, 하나의 GPU로 연산 결과를 모으기 때문에 GPU 수가 증가할 수록 하나의 GPU의 메모리 사용량이 증가해 효율적인 사용이 불가능하다. 참고 train 할 때 DP를 ..



