
WBF (Weighted Boxes Fusion)
Object Detection Task에서 학습된 모델의 결과를 Ensemble 하여 성능을 끌어올리기 위해서는 BBox들을 Ensemble하는 NMS, Soft-NMS 같은 알고리즘을 사용해야 합니다.
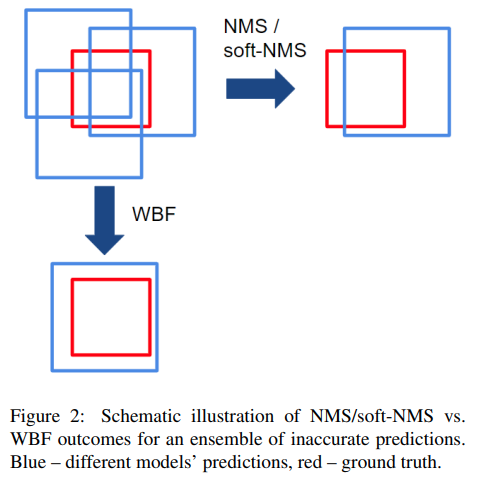
기존의 NMS나 Soft-NMS 같은 방법은 기존의 BBox에서 불필요한 BBox를 제거하는 방식으로 동작하였습니다.
WBF는 기존의 이러한 방식과는 다르게 모든 BBox를 사용하여 더 나은 BBox를 만들게 됩니다. 이 방법은 연산 속도를 추가적으로 필요하기 때문에 Real Time보다는 Kaggle, Dacon 같은 경진대회에서 주로 사용하는 편입니다.
WBF 알고리즘 과정
- \(B\) : 한 이미지에 대한 모든 BBox의 정보를 Score 기준으로 정렬한 List 생성
- \(L\) : BBox 를 모을 빈 List & \(F\) : \(L\)에 존재하는 BBox를 Fusion한 Fused Box를 저장할 빈 List 생성
- \(B\)의 첫 번째(Score가 가장 높은) BBox와 \(F\)에 존재하는 Fused Box와 Fusion될 수 있는지 IoU를 통해 확인
- \(IoU_{F&B_i} > THR\) \(\rightarrow\) 논문에서는 THR 값이 0.55일 때 최적이였다고 합니다.
- 위 조건을 만족하는지 여부에 따라 다음과정 수행
- 융합될 수 없는 경우 : 해당 BBox를 \(B\)에서 꺼내 \(L\)의 끝과 \(F\)에 넣는다.
- 융합될 수 있는 경우 : 해당 BBox를 \(B\)에서 꺼내 \(L\)에 넣고 \(F\)와 Match하고 다음 과정 수행
- \(F[Pos].append(L_i)\)
- \(F[Pos]\)와 연결된 \(L\)에 존재하는 T개의 BBox를 모아 다음 수식을 통해 \(F\)의 위치와 Score 조정
- \(C=\frac{\sum_{i=1}^{T} C_i}{T}\)
- \(X_{1,2}=\frac{\sum_{i=1}^{T} C_i * X_{1_i, 2_i}}{\sum_{i=1}^{T} C_i}\)
- \(Y_{1,2}=\frac{\sum_{i=1}^{T} C_i * Y_{1_i, 2_i}}{\sum_{i=1}^{T} C_i}\)
- 모든 계산이 끝난 후 \(N\)이 Ensemble한 모델의 수라고 할 때, \(F\)에 존재하는 BBox들의 Score를 다음 두 식 중 하나를 통해 조절한다.
- \(C = C * \frac{min(T, N)}{N}\)
- \(C = C * \frac{T}{N}\)
- \(T < N\)일 경우 BBox를 예착한 Model의 수가 적다는 뜻 이므로, Score를 낮춰줘야 하기 때문이다.
Pytorch 사용 예제
Github 라이브러리 사용
GitHub - ZFTurbo/Weighted-Boxes-Fusion: Set of methods to ensemble boxes from different object detection models, including imple
Set of methods to ensemble boxes from different object detection models, including implementation of "Weighted boxes fusion (WBF)" method. - GitHub - ZFTurbo/Weighted-Boxes-Fusion: Set of...
github.com
Import
# https://github.com/ZFTurbo/Weighted-Boxes-Fusion
# pip install ensemble_boxes
from ensemble_boxes import *Check Models for Ensemble
ensemble_models 폴더 안에 각 모델들의 추론 결과(.csv) 파일의 name, 개수를 확인합니다.
나의 ensemble1.csv 예시
PredictionString image_id
[Label] [Score] [BBox] [Image Dir]
0 0.9492 10.3424 20.3421 50.4443 70.9901 ... ../data/test/0001.jpg
ensemble_models_output_dir = '../inference/ensemble_models'
ensemble_models_output_list = os.listdir(ensemble_models_output_dir)
print(ensemble_models_output_list)Check Null Value
Null 값이 들어 있으면 Error가 출력되기 때문에 실행 전 확인합니다.
ensemble_pd_list = []
for idx, output in enumerate(ensemble_models_output_list):
with open(os.path.join(ensemble_models_output, output), 'rb') as f:
data = pd.read_csv(f)
print('Null Index : ', data[data['PredictionString'].isnull()].index)
ensemble_pd_list.append(data)Config Set
Github Repo에 있는 Default 값을 사용합니다.
Normalize를 위해 img_size를 설정합니다.
iou_thr = 0.5
skip_box_thr = 0.0001
sigma = 0.1
weights = [1] * len(ensemble_models_output_list)
img_size = 1024. # Float 형식으로 지정Run
csv_predictions = []
for image_id in ensemble_pd_list[0]['image_id']:
labels_list, scores_list, bboxes_list = [], [], []
for ensemble_pd in ensemble_pd_list:
labels, scores, bboxes = [], [], []
predict = list(ensemble_pd[ensemble_pd['image_id']==image_id]['PredictionString'])[0]
predict = predict.strip().split(' ')
predict_list = [list(map(float, predict[i:i+6])) for i in range(0, len(predict), 6)] # 6개 단위로 묶기
for predict_ in predict_list: # 한 이미지 내 label, score, bbox
label = predict_[0]
score = predict_[1]
bbox = [predict_[2]/img_size, predict_[3]/img_size, predict_[4]/img_size, predict_[5]/img_size]
labels.append(label)
scores.append(score)
bboxes.append(bbox)
labels_list.append(labels)
scores_list.append(scores)
bboxes_list.append(bboxes)
# nms, soft-nms, weighted_boxes_fusion
# bboxes, scores, labels = nms(bboxes_list, scores_list, labels_list, weights=weights, iou_thr=iou_thr)
# bboxes, scores, labels = soft_nms(bboxes_list, scores_list, labels_list, weights=weights, iou_thr=iou_thr, sigma=sigma, thresh=skip_box_thr)
# bboxes, scores, labels = non_maximum_weighted(bboxes_list, scores_list, labels_list, weights=weights, iou_thr=iou_thr, skip_box_thr=skip_box_thr)
bboxes, scores, labels = weighted_boxes_fusion(bboxes_list, scores_list, labels_list, weights=weights, iou_thr=iou_thr, skip_box_thr=skip_box_thr)
predict = ''
for infos in zip(labels, scores, bboxes):
infos = list(infos)
predict += str(int(infos[0])) + ' '
predict += str(infos[1]) + ' '
bbox = infos[2].tolist()
predict += str(bbox[0]*img_size) + ' ' + str(bbox[1]*img_size) + ' ' + str(bbox[2]*img_size) + ' ' + str(bbox[3]*img_size) + ' '
csv_predictions.append(predict)
'ML & DL > Deep Learning' 카테고리의 다른 글
| [Time Series Forecasting] LSTM, GRU, CNN, ... PyTorch 구현 (0) | 2024.10.10 |
|---|---|
| IoU, Precision, Recall, mAP 정리 (0) | 2023.05.19 |
| NMS, Soft-NMS 정리 및 구현 (0) | 2023.05.19 |
| Mixup 정리 및 구현 (0) | 2023.04.27 |
| CNN Architectures (0) | 2023.03.28 |
WBF (Weighted Boxes Fusion)
Object Detection Task에서 학습된 모델의 결과를 Ensemble 하여 성능을 끌어올리기 위해서는 BBox들을 Ensemble하는 NMS, Soft-NMS 같은 알고리즘을 사용해야 합니다.
기존의 NMS나 Soft-NMS 같은 방법은 기존의 BBox에서 불필요한 BBox를 제거하는 방식으로 동작하였습니다.
WBF는 기존의 이러한 방식과는 다르게 모든 BBox를 사용하여 더 나은 BBox를 만들게 됩니다. 이 방법은 연산 속도를 추가적으로 필요하기 때문에 Real Time보다는 Kaggle, Dacon 같은 경진대회에서 주로 사용하는 편입니다.
WBF 알고리즘 과정
- \(B\) : 한 이미지에 대한 모든 BBox의 정보를 Score 기준으로 정렬한 List 생성
- \(L\) : BBox 를 모을 빈 List & \(F\) : \(L\)에 존재하는 BBox를 Fusion한 Fused Box를 저장할 빈 List 생성
- \(B\)의 첫 번째(Score가 가장 높은) BBox와 \(F\)에 존재하는 Fused Box와 Fusion될 수 있는지 IoU를 통해 확인
- \(IoU_{F&B_i} > THR\) \(\rightarrow\) 논문에서는 THR 값이 0.55일 때 최적이였다고 합니다.
- 위 조건을 만족하는지 여부에 따라 다음과정 수행
- 융합될 수 없는 경우 : 해당 BBox를 \(B\)에서 꺼내 \(L\)의 끝과 \(F\)에 넣는다.
- 융합될 수 있는 경우 : 해당 BBox를 \(B\)에서 꺼내 \(L\)에 넣고 \(F\)와 Match하고 다음 과정 수행
- \(F[Pos].append(L_i)\)
- \(F[Pos]\)와 연결된 \(L\)에 존재하는 T개의 BBox를 모아 다음 수식을 통해 \(F\)의 위치와 Score 조정
- \(C=\frac{\sum_{i=1}^{T} C_i}{T}\)
- \(X_{1,2}=\frac{\sum_{i=1}^{T} C_i * X_{1_i, 2_i}}{\sum_{i=1}^{T} C_i}\)
- \(Y_{1,2}=\frac{\sum_{i=1}^{T} C_i * Y_{1_i, 2_i}}{\sum_{i=1}^{T} C_i}\)
- 모든 계산이 끝난 후 \(N\)이 Ensemble한 모델의 수라고 할 때, \(F\)에 존재하는 BBox들의 Score를 다음 두 식 중 하나를 통해 조절한다.
- \(C = C * \frac{min(T, N)}{N}\)
- \(C = C * \frac{T}{N}\)
- \(T < N\)일 경우 BBox를 예착한 Model의 수가 적다는 뜻 이므로, Score를 낮춰줘야 하기 때문이다.
Pytorch 사용 예제
Github 라이브러리 사용
GitHub - ZFTurbo/Weighted-Boxes-Fusion: Set of methods to ensemble boxes from different object detection models, including imple
Set of methods to ensemble boxes from different object detection models, including implementation of "Weighted boxes fusion (WBF)" method. - GitHub - ZFTurbo/Weighted-Boxes-Fusion: Set of...
github.com
Import
# https://github.com/ZFTurbo/Weighted-Boxes-Fusion
# pip install ensemble_boxes
from ensemble_boxes import *
Check Models for Ensemble
ensemble_models 폴더 안에 각 모델들의 추론 결과(.csv) 파일의 name, 개수를 확인합니다.
나의 ensemble1.csv 예시
PredictionString image_id
[Label] [Score] [BBox] [Image Dir]
0 0.9492 10.3424 20.3421 50.4443 70.9901 ... ../data/test/0001.jpg
ensemble_models_output_dir = '../inference/ensemble_models'
ensemble_models_output_list = os.listdir(ensemble_models_output_dir)
print(ensemble_models_output_list)Check Null Value
Null 값이 들어 있으면 Error가 출력되기 때문에 실행 전 확인합니다.
ensemble_pd_list = []
for idx, output in enumerate(ensemble_models_output_list):
with open(os.path.join(ensemble_models_output, output), 'rb') as f:
data = pd.read_csv(f)
print('Null Index : ', data[data['PredictionString'].isnull()].index)
ensemble_pd_list.append(data)Config Set
Github Repo에 있는 Default 값을 사용합니다.
Normalize를 위해 img_size를 설정합니다.
iou_thr = 0.5
skip_box_thr = 0.0001
sigma = 0.1
weights = [1] * len(ensemble_models_output_list)
img_size = 1024. # Float 형식으로 지정Run
csv_predictions = []
for image_id in ensemble_pd_list[0]['image_id']:
labels_list, scores_list, bboxes_list = [], [], []
for ensemble_pd in ensemble_pd_list:
labels, scores, bboxes = [], [], []
predict = list(ensemble_pd[ensemble_pd['image_id']==image_id]['PredictionString'])[0]
predict = predict.strip().split(' ')
predict_list = [list(map(float, predict[i:i+6])) for i in range(0, len(predict), 6)] # 6개 단위로 묶기
for predict_ in predict_list: # 한 이미지 내 label, score, bbox
label = predict_[0]
score = predict_[1]
bbox = [predict_[2]/img_size, predict_[3]/img_size, predict_[4]/img_size, predict_[5]/img_size]
labels.append(label)
scores.append(score)
bboxes.append(bbox)
labels_list.append(labels)
scores_list.append(scores)
bboxes_list.append(bboxes)
# nms, soft-nms, weighted_boxes_fusion
# bboxes, scores, labels = nms(bboxes_list, scores_list, labels_list, weights=weights, iou_thr=iou_thr)
# bboxes, scores, labels = soft_nms(bboxes_list, scores_list, labels_list, weights=weights, iou_thr=iou_thr, sigma=sigma, thresh=skip_box_thr)
# bboxes, scores, labels = non_maximum_weighted(bboxes_list, scores_list, labels_list, weights=weights, iou_thr=iou_thr, skip_box_thr=skip_box_thr)
bboxes, scores, labels = weighted_boxes_fusion(bboxes_list, scores_list, labels_list, weights=weights, iou_thr=iou_thr, skip_box_thr=skip_box_thr)
predict = ''
for infos in zip(labels, scores, bboxes):
infos = list(infos)
predict += str(int(infos[0])) + ' '
predict += str(infos[1]) + ' '
bbox = infos[2].tolist()
predict += str(bbox[0]*img_size) + ' ' + str(bbox[1]*img_size) + ' ' + str(bbox[2]*img_size) + ' ' + str(bbox[3]*img_size) + ' '
csv_predictions.append(predict)
'ML & DL > Deep Learning' 카테고리의 다른 글
| [Time Series Forecasting] LSTM, GRU, CNN, ... PyTorch 구현 (0) | 2024.10.10 |
|---|---|
| IoU, Precision, Recall, mAP 정리 (0) | 2023.05.19 |
| NMS, Soft-NMS 정리 및 구현 (0) | 2023.05.19 |
| Mixup 정리 및 구현 (0) | 2023.04.27 |
| CNN Architectures (0) | 2023.03.28 |