
Mixup
모델을 학습할 때 Overfitting을 방지하기 위해 다양한 규제(Regularization) 기법이 존재합니다.
Mixup은 그 중 데이터 증강(Data Augmentation)과 관련된 기술 중 하나로, 학습 데이터에서 두 개의 샘플 데이터를 혼합(Mix)하여 새로운 학습 데이터를 만드는 기술입니다.
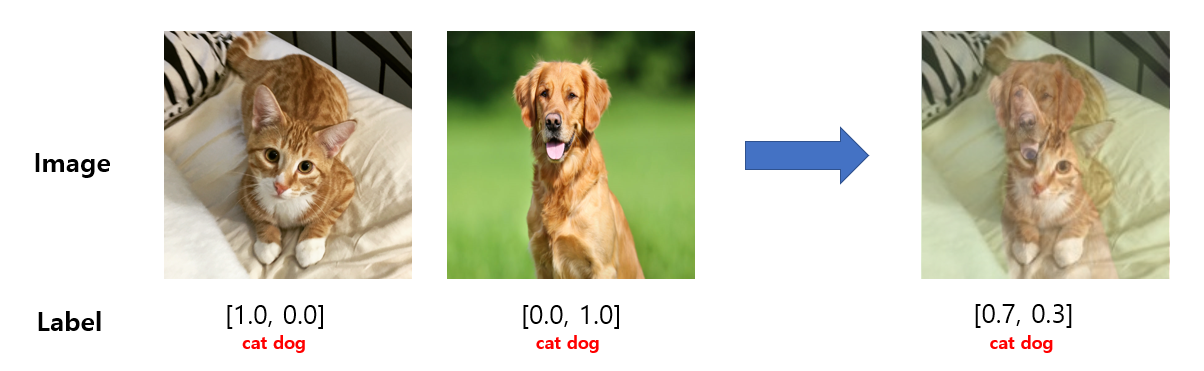
위 그림처럼 개와 고양이 이미지 데이터를 mixup 한 뒤, image 데이터 뿐만 아니라 label 데이터 또한 mixup 합니다.
mixup은 간단하게 수식으로 표현할 수 있습니다.
$$ \hat{x} = \lambda x_i + (1-\lambda) x_j $$
$$ \hat{y} = \lambda y_i + (1-\lambda) y_j $$
\(x\) : image 데이터 (\(x_i\)는 고양이, \(x_j\)는 개)
\(y\) : label 데이터 (\(x_i\)는 고양이, \(x_j\)는 개)
\(\lambda\) : 2개의 이미지를 어떤 비율로 섞는지에 대한 값으로, 베타 분포(Beta Distribution)를 통해 값을 구하며 0~1 사이의 값을 출력하게 됩니다.
이렇게 학습하여 Overfitting을 방지하면서 일반화 성능을 더 높일 수 있게 됩니다.
Pytorch 구현
Mixup Input & Label Data
def MixUp(input, target, alpha=1.0):
if CFG['ALPHA'] > 0:
lambda_ = np.random.beta(alpha, alpha)
else:
lambda_ = 1
batch_size = input.size(0)
index = torch.randperm(batch_size)
mixed_input = lambda_ * input + (1 - lambda_) * input[index, :]
labels_a, labels_b = target, target[index]
return mixed_input, labels_a, labels_b, lambda_Mixup Loss
def MixUpLoss(criterion, pred, labels_a, labels_b, lambda_):
return lambda_ * criterion(pred, labels_a) + (1 - lambda_) * criterion(pred, labels_b)Train 예시
Mixup을 사용한다면, Batch 3번째 마다 Mixup을 적용하여 preds 값을 예측 후 Mixup Loss를 구합니다.
...
criterion = nn.CrossEntropyLoss().to(device)
...
for epoch in range(1, epochs+1):
self.model.train()
train_loss = []
for idx, (imgs, labels) in enumerate(tqdm(iter(train_dataloader))):
imgs = imgs.float().to(device)
labels = labels.to(device)
self.optimizer.zero_grad()
if CFG['MIXUP'] and (idx + 1) % 3 == 0:
imgs, labels_a, labels_b, lambda_ = MixUp(imgs, labels)
output = model(imgs)
loss = MixUpLoss(criterion, pred=output, labels_a_a=labels_a, labels_b=labels_b, lambda_=lambda_)
else:
output = model(imgs)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
train_loss.append(loss.item())
_val_loss, _val_acc = self.validation()
_train_loss = np.mean(train_loss)
'ML & DL > Deep Learning' 카테고리의 다른 글
| WBF, Ensemble for Object Detection 정리 (0) | 2023.05.19 |
|---|---|
| NMS, Soft-NMS 정리 및 구현 (0) | 2023.05.19 |
| CNN Architectures (0) | 2023.03.28 |
| 1 x 1 Convolution ? (0) | 2023.03.22 |
| Albumentations 사용법 및 예시 (0) | 2022.05.23 |
Mixup
모델을 학습할 때 Overfitting을 방지하기 위해 다양한 규제(Regularization) 기법이 존재합니다.
Mixup은 그 중 데이터 증강(Data Augmentation)과 관련된 기술 중 하나로, 학습 데이터에서 두 개의 샘플 데이터를 혼합(Mix)하여 새로운 학습 데이터를 만드는 기술입니다.
위 그림처럼 개와 고양이 이미지 데이터를 mixup 한 뒤, image 데이터 뿐만 아니라 label 데이터 또한 mixup 합니다.
mixup은 간단하게 수식으로 표현할 수 있습니다.
$$ \hat{x} = \lambda x_i + (1-\lambda) x_j $$
$$ \hat{y} = \lambda y_i + (1-\lambda) y_j $$
\(x\) : image 데이터 (\(x_i\)는 고양이, \(x_j\)는 개)
\(y\) : label 데이터 (\(x_i\)는 고양이, \(x_j\)는 개)
\(\lambda\) : 2개의 이미지를 어떤 비율로 섞는지에 대한 값으로, 베타 분포(Beta Distribution)를 통해 값을 구하며 0~1 사이의 값을 출력하게 됩니다.
이렇게 학습하여 Overfitting을 방지하면서 일반화 성능을 더 높일 수 있게 됩니다.
Pytorch 구현
Mixup Input & Label Data
def MixUp(input, target, alpha=1.0):
if CFG['ALPHA'] > 0:
lambda_ = np.random.beta(alpha, alpha)
else:
lambda_ = 1
batch_size = input.size(0)
index = torch.randperm(batch_size)
mixed_input = lambda_ * input + (1 - lambda_) * input[index, :]
labels_a, labels_b = target, target[index]
return mixed_input, labels_a, labels_b, lambda_
Mixup Loss
def MixUpLoss(criterion, pred, labels_a, labels_b, lambda_):
return lambda_ * criterion(pred, labels_a) + (1 - lambda_) * criterion(pred, labels_b)Train 예시
Mixup을 사용한다면, Batch 3번째 마다 Mixup을 적용하여 preds 값을 예측 후 Mixup Loss를 구합니다.
...
criterion = nn.CrossEntropyLoss().to(device)
...
for epoch in range(1, epochs+1):
self.model.train()
train_loss = []
for idx, (imgs, labels) in enumerate(tqdm(iter(train_dataloader))):
imgs = imgs.float().to(device)
labels = labels.to(device)
self.optimizer.zero_grad()
if CFG['MIXUP'] and (idx + 1) % 3 == 0:
imgs, labels_a, labels_b, lambda_ = MixUp(imgs, labels)
output = model(imgs)
loss = MixUpLoss(criterion, pred=output, labels_a_a=labels_a, labels_b=labels_b, lambda_=lambda_)
else:
output = model(imgs)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
train_loss.append(loss.item())
_val_loss, _val_acc = self.validation()
_train_loss = np.mean(train_loss)
'ML & DL > Deep Learning' 카테고리의 다른 글
| WBF, Ensemble for Object Detection 정리 (0) | 2023.05.19 |
|---|---|
| NMS, Soft-NMS 정리 및 구현 (0) | 2023.05.19 |
| CNN Architectures (0) | 2023.03.28 |
| 1 x 1 Convolution ? (0) | 2023.03.22 |
| Albumentations 사용법 및 예시 (0) | 2022.05.23 |