Data Parallel (DP)
사용법
...
model = resnet18().to(device)
model = torch.nn.DataParallel(model)
...장점
- 위 예시처럼 매우 간단하게 사용이 가능하다
단점
- 메모리 사용량 증가 : 각 GPU에서 모델의 복사본을 만들어 메모리를 사용하기 떄문에 GPU의 수가 증가할 수록 메모리 사용량이 증가
- 통신 병목 현상 : 각 GPU에서 연산을 수행하고 연산 결과를 하나의 GPU로 모은 후에 모델을 업데이트 하기 때문에 GPU간 데이터를 복사하고 통신하는 데 시간이 소요된다. 또한, 하나의 GPU로 연산 결과를 모으기 때문에 GPU 수가 증가할 수록 하나의 GPU의 메모리 사용량이 증가해 효율적인 사용이 불가능하다.
참고
- train 할 때 DP를 사용했다면, inference할 때, 전이 학습 할 때에도 DP를 사용하여 모델을 불러와야 한다.
- 또는 train 후 모델을 저장할 때 model의 module을 저장한다.
- torch.save(model.module.state_dict(), save_path)
- 또는 train 후 모델을 저장할 때 model의 module을 저장한다.
- 2개 이상의 GPU를 사용하고 있지만 DP를 사용했을 때 하나의 GPU에서만 동작한다면 다음을 시도해본다.
- device_ids를 정확히 명시해보기
- os.environ["CUDA_VISIBLE_DEVICES"] = "0, 1"
- input가 하나의 tensor로 구성되어 있는지 확인하기 [참고]
- device_ids를 정확히 명시해보기
- GPU 연산 결과를 기본적으로 0번 device에 모으는데, 이를 변경할 수 있다.
- model = torch.nn.DataParallel(model, output_device=1)
Distributed Data Parallel (DDP)
분산 학습으로, 여러 컴퓨터(서버, 머신)의 여러 GPU를 사용하여 모델을 학습합니다.
하나의 컴퓨터의 여러 GPU를 분산 학습 할 수도 있으며, DP의 단점을 해결한 대신 코드 세팅이 복잡하다는 단점이 있습니다.
사용 전 용어 정리
1. torch.distributed.init_process_group
# init_process_group
torch.distributed.init_process_group(backend='nccl',
init_method='tcp://127.0.0.1:12355',
world_size=args.ngpus_per_node,
rank=args.rank)분산 학습을 위한 초기화 함수로, 각 프로세스마다 호출되어야 하고, 분산 학습을 위해 필요한 설정이 완료된 후에만 다음 단계로 진행할 수 있습니다.
- backend : 사용할 분산 처리 backend
- GPU traning : 'nccl'
- CPU training : 'gloo'
- init_method : 초기화 방법으로 'nccl' backend에 단일 머신 다중 GPU 학습 시 'tcp://localhost:[사용할 port]'로 지정
- world_size : 전체 프로세스 개수 (단일 머신의 경우 GPU 개수)
- rank : 현재 프로세스 id, 0부터 world_size - 1 까지의 값을 가진다.
2. DistributedSampler
train_sampler = DistributedSampler(dataset=train_dataset, shuffle=True)
batch_sampler_train = torch.utils.data.BatchSampler(train_sampler, opts.batch_size, drop_last=True)
train_loader = DataLoader(train_dataset, batch_sampler=batch_sampler_train, num_workers=opts.num_workers)- DistributedSampler는 분산 데이터 병렬학습(distributed data parallel training)시 각 프로세스가 미니배치를 나누어 학습할 데이터 샘플을 결정하는 역할
- 일반적으로 각 프로세스는 전체 데이터셋을 고루 나누어 학습하지만, 이렇게 나누어 학습하는 경우 다른 프로세스에서 학습하는 데이터 샘플과 중복되는 경우가 발생할 수 있음
- DistributedSampler는 데이터셋의 각 샘플에 대한 인덱스를 분산처리에 맞게 새로운 순서로 만들어주고, 해당 인덱스를 이용하여 프로세스들 간의 중복 없는 데이터 분배 가능
3. DistributedDataParallel

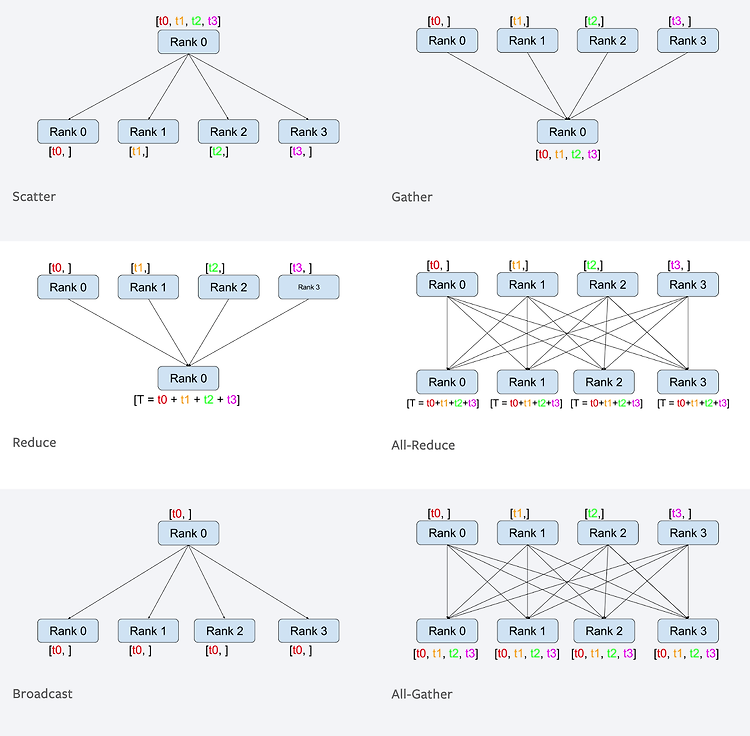
model = DistributedDataParallel(module=model, device_ids=[local_gpu_id])- 각각의 GPU에 데이터와 모델을 분배
- 각각의 GPU에서 계산된 Gradient들이 전체적으로 동기화되어 합쳐짐
- 이를 통해 각 GPU에서 계산된 Gradient가 Master GPU에서 처리되어 업데이트
4. torch.multiprocessing.spawn
def train(rank, world_size):
# 분산 학습 코드 작성
pass
if __name__ == '__main__':
args.ngpus_per_node = torch.cuda.device_count()
args.gpu_ids = list(range(args.ngpus_per_node))
args.num_workers = 16
torch.multiprocessing.spawn(train,
args=(args,),
nprocs=args.ngpus_per_node,
join=True)분산 학습을 위한 프로세스 그룹을 생성하는 함수로, 분산 학습을 위해 여러 프로세스를 실행하는 데 사용
- fn (train) : 실행 할 함수. 함수의 첫 번째 파라미터는 rank
- args : 함수에 전달할 인자
- nprocs : 실행할 프로세스 개수
전체 코드 요약
import os
import time
import math
from argparse import ArgumentParser
import torch
from torch import cuda
from torch.utils.data import DataLoader
from torch.optim import lr_scheduler
from tqdm import tqdm
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel
from torch.utils.data.distributed import DistributedSampler
def parse_args():
parser = ArgumentParser()
# Conventional args
...
args = parser.parse_args()
return args
def train(rank, args):
init_distributed(rank, args)
local_gpu_id = args.gpu
dataset = CustomtDataset(...)
# sampler
sampler = DistributedSampler(dataset, shuffle=True)
batch_sampler = torch.utils.data.BatchSampler(sampler, args.batch_size, drop_last=True)
train_loader = DataLoader(
dataset,
batch_size=args.batch_size,
shuffle=False,
num_workers=args.num_workers,
pin_memory=True,
batch_sampler=batch_sampler # sampler
)
model = MyModel()
model.cuda(local_gpu_id)
model = DistributedDataParallel(model, device_ids=[local_gpu_id])
optimizer = torch.optim.Adam(model.parameters(), lr=args.learning_rate)
scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[args.max_epoch // 2], gamma=0.1)
...
model.train()
for epoch in range(args.max_epoch):
# ddp sampler set epoch
sampler.set_epoch(epoch)
...
def init_distributed(rank, args):
# 1. setting for distributed training
args.rank = rank
args.gpu = args.rank % torch.cuda.device_count()
local_gpu_id = int(args.gpu_ids[args.rank])
torch.cuda.set_device(local_gpu_id)
if args.rank is not None:
print("Use GPU: {} for training".format(local_gpu_id))
# 2. init_process_group
torch.distributed.init_process_group(backend='nccl',
init_method='tcp://127.0.0.1:12355',
world_size=args.ngpus_per_node,
rank=args.rank)
# if put this function, the all processes block at all.
# ? : https://stackoverflow.com/questions/59760328/how-does-torch-distributed-barrier-work
torch.distributed.barrier()
if __name__ == '__main__':
args = parse_args()
args.ngpus_per_node = torch.cuda.device_count()
args.gpu_ids = list(range(args.ngpus_per_node))
args.num_workers = 16
torch.multiprocessing.spawn(train,
args=(args,),
nprocs=args.ngpus_per_node,
join=True)
'ML & DL > PyTorch' 카테고리의 다른 글
| [PyTorch] torchvision & transform (0) | 2023.03.15 |
|---|---|
| [PyTorch] Dataset & DataLoader (0) | 2023.03.15 |
| [PyTorch] nn.Module (0) | 2023.03.15 |
| [PyTorch] torch.nn (0) | 2023.03.15 |
| [PyTorch] Optimization, 최적화 (0) | 2023.03.13 |
Data Parallel (DP)
사용법
... model = resnet18().to(device) model = torch.nn.DataParallel(model) ...
장점
- 위 예시처럼 매우 간단하게 사용이 가능하다
단점
- 메모리 사용량 증가 : 각 GPU에서 모델의 복사본을 만들어 메모리를 사용하기 떄문에 GPU의 수가 증가할 수록 메모리 사용량이 증가
- 통신 병목 현상 : 각 GPU에서 연산을 수행하고 연산 결과를 하나의 GPU로 모은 후에 모델을 업데이트 하기 때문에 GPU간 데이터를 복사하고 통신하는 데 시간이 소요된다. 또한, 하나의 GPU로 연산 결과를 모으기 때문에 GPU 수가 증가할 수록 하나의 GPU의 메모리 사용량이 증가해 효율적인 사용이 불가능하다.
참고
- train 할 때 DP를 사용했다면, inference할 때, 전이 학습 할 때에도 DP를 사용하여 모델을 불러와야 한다.
- 또는 train 후 모델을 저장할 때 model의 module을 저장한다.
- torch.save(model.module.state_dict(), save_path)
- 또는 train 후 모델을 저장할 때 model의 module을 저장한다.
- 2개 이상의 GPU를 사용하고 있지만 DP를 사용했을 때 하나의 GPU에서만 동작한다면 다음을 시도해본다.
- device_ids를 정확히 명시해보기
- os.environ["CUDA_VISIBLE_DEVICES"] = "0, 1"
- input가 하나의 tensor로 구성되어 있는지 확인하기 [참고]
- device_ids를 정확히 명시해보기
- GPU 연산 결과를 기본적으로 0번 device에 모으는데, 이를 변경할 수 있다.
- model = torch.nn.DataParallel(model, output_device=1)
Distributed Data Parallel (DDP)
분산 학습으로, 여러 컴퓨터(서버, 머신)의 여러 GPU를 사용하여 모델을 학습합니다.
하나의 컴퓨터의 여러 GPU를 분산 학습 할 수도 있으며, DP의 단점을 해결한 대신 코드 세팅이 복잡하다는 단점이 있습니다.
사용 전 용어 정리
1. torch.distributed.init_process_group
# init_process_group
torch.distributed.init_process_group(backend='nccl',
init_method='tcp://127.0.0.1:12355',
world_size=args.ngpus_per_node,
rank=args.rank)
분산 학습을 위한 초기화 함수로, 각 프로세스마다 호출되어야 하고, 분산 학습을 위해 필요한 설정이 완료된 후에만 다음 단계로 진행할 수 있습니다.
- backend : 사용할 분산 처리 backend
- GPU traning : 'nccl'
- CPU training : 'gloo'
- init_method : 초기화 방법으로 'nccl' backend에 단일 머신 다중 GPU 학습 시 'tcp://localhost:[사용할 port]'로 지정
- world_size : 전체 프로세스 개수 (단일 머신의 경우 GPU 개수)
- rank : 현재 프로세스 id, 0부터 world_size - 1 까지의 값을 가진다.
2. DistributedSampler
train_sampler = DistributedSampler(dataset=train_dataset, shuffle=True)
batch_sampler_train = torch.utils.data.BatchSampler(train_sampler, opts.batch_size, drop_last=True)
train_loader = DataLoader(train_dataset, batch_sampler=batch_sampler_train, num_workers=opts.num_workers)- DistributedSampler는 분산 데이터 병렬학습(distributed data parallel training)시 각 프로세스가 미니배치를 나누어 학습할 데이터 샘플을 결정하는 역할
- 일반적으로 각 프로세스는 전체 데이터셋을 고루 나누어 학습하지만, 이렇게 나누어 학습하는 경우 다른 프로세스에서 학습하는 데이터 샘플과 중복되는 경우가 발생할 수 있음
- DistributedSampler는 데이터셋의 각 샘플에 대한 인덱스를 분산처리에 맞게 새로운 순서로 만들어주고, 해당 인덱스를 이용하여 프로세스들 간의 중복 없는 데이터 분배 가능
3. DistributedDataParallel
model = DistributedDataParallel(module=model, device_ids=[local_gpu_id])
- 각각의 GPU에 데이터와 모델을 분배
- 각각의 GPU에서 계산된 Gradient들이 전체적으로 동기화되어 합쳐짐
- 이를 통해 각 GPU에서 계산된 Gradient가 Master GPU에서 처리되어 업데이트
4. torch.multiprocessing.spawn
def train(rank, world_size):
# 분산 학습 코드 작성
pass
if __name__ == '__main__':
args.ngpus_per_node = torch.cuda.device_count()
args.gpu_ids = list(range(args.ngpus_per_node))
args.num_workers = 16
torch.multiprocessing.spawn(train,
args=(args,),
nprocs=args.ngpus_per_node,
join=True)분산 학습을 위한 프로세스 그룹을 생성하는 함수로, 분산 학습을 위해 여러 프로세스를 실행하는 데 사용
- fn (train) : 실행 할 함수. 함수의 첫 번째 파라미터는 rank
- args : 함수에 전달할 인자
- nprocs : 실행할 프로세스 개수
전체 코드 요약
import os
import time
import math
from argparse import ArgumentParser
import torch
from torch import cuda
from torch.utils.data import DataLoader
from torch.optim import lr_scheduler
from tqdm import tqdm
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel
from torch.utils.data.distributed import DistributedSampler
def parse_args():
parser = ArgumentParser()
# Conventional args
...
args = parser.parse_args()
return args
def train(rank, args):
init_distributed(rank, args)
local_gpu_id = args.gpu
dataset = CustomtDataset(...)
# sampler
sampler = DistributedSampler(dataset, shuffle=True)
batch_sampler = torch.utils.data.BatchSampler(sampler, args.batch_size, drop_last=True)
train_loader = DataLoader(
dataset,
batch_size=args.batch_size,
shuffle=False,
num_workers=args.num_workers,
pin_memory=True,
batch_sampler=batch_sampler # sampler
)
model = MyModel()
model.cuda(local_gpu_id)
model = DistributedDataParallel(model, device_ids=[local_gpu_id])
optimizer = torch.optim.Adam(model.parameters(), lr=args.learning_rate)
scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[args.max_epoch // 2], gamma=0.1)
...
model.train()
for epoch in range(args.max_epoch):
# ddp sampler set epoch
sampler.set_epoch(epoch)
...
def init_distributed(rank, args):
# 1. setting for distributed training
args.rank = rank
args.gpu = args.rank % torch.cuda.device_count()
local_gpu_id = int(args.gpu_ids[args.rank])
torch.cuda.set_device(local_gpu_id)
if args.rank is not None:
print("Use GPU: {} for training".format(local_gpu_id))
# 2. init_process_group
torch.distributed.init_process_group(backend='nccl',
init_method='tcp://127.0.0.1:12355',
world_size=args.ngpus_per_node,
rank=args.rank)
# if put this function, the all processes block at all.
# ? : https://stackoverflow.com/questions/59760328/how-does-torch-distributed-barrier-work
torch.distributed.barrier()
if __name__ == '__main__':
args = parse_args()
args.ngpus_per_node = torch.cuda.device_count()
args.gpu_ids = list(range(args.ngpus_per_node))
args.num_workers = 16
torch.multiprocessing.spawn(train,
args=(args,),
nprocs=args.ngpus_per_node,
join=True)
'ML & DL > PyTorch' 카테고리의 다른 글
| [PyTorch] torchvision & transform (0) | 2023.03.15 |
|---|---|
| [PyTorch] Dataset & DataLoader (0) | 2023.03.15 |
| [PyTorch] nn.Module (0) | 2023.03.15 |
| [PyTorch] torch.nn (0) | 2023.03.15 |
| [PyTorch] Optimization, 최적화 (0) | 2023.03.13 |