
이 논문은 장기 시계열 예측(Long-term Time Series Forecasting, LTSF)을 위한 효율적이고 해석 가능한 DiPE-Linear(Disentangled interpretable-Parameter-Efficient Linear network)를 제안합니다.
Introduction
딥러닝 모델들은 높은 정확도를 제공하지만, 블랙박스(Black Box) 특성으로 인해 사용자 신뢰를 떨어뜨립니다.
또한, 기존의 시계열 예측 방법(또는 기법)들은 다음과 같은 한계점을 가지고 있습니다.
- RNN : 병렬화가 어렵습니다.
- CNN : 높은 계산 비용을 요구합니다.
- Transformer : 여러 개선에도 불구하고 많은 수의 파라미터를 가지, 긴 입력 시퀀스에 쉽게 과적합됩니다.
- FC(Fully Connected) : 이차 복잡도(Quadratic Complexity)로 인한 파라미터 중복 ? 복제 ?(Parameter Redundancy) 문제가 있습니다.
※ 이차 복잡도 (Quadratic Complexity) [참고]
입력 데이터 크기를 \(L\)이라고 할 때, 계산량이나 메모리 사용량이 \(L^2\)에 비례하여 증가하는 현상.
※ 파라미터 중복 (Parameter Redundancy) [GPT 답변]
모델이 필요 이상으로 많은 파라미터를 가지면서 실제로 유의미하지 않거나 중복된 정보를 학습하는 현상.
\(\rightarrow\) LTSF의 경우, 긴 시퀀스을 예측해야 하기 때문에 입력 데이터 긴 시퀀스를 필요로 함. FC는 모든 입력마다 모든 출력으로 연결을 유지하므로 파라미터 수가 제곱에 비례함. 따라서, 과도하게 많은 파라미터가 존재하고 이는 비용 증가, 과적합 문제 등이 발생과 동시에 많은 파라미터들 중 중복된 파라미터들로 인해 모델 성능 향상에 기여하지 않으면서 계산 비용만 증가시키고, 최적점을 찾아가는데 방해됨.
DiPE-Linear
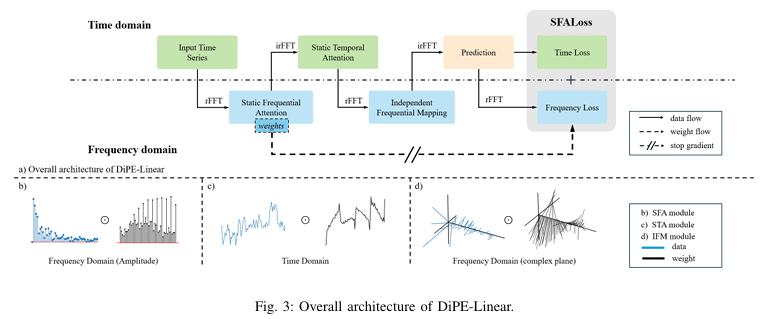
DiPE-Linear 모델은 다음 세 가지 모듈로 구성됩니다.
1. Static Frequential Attention (SFA)
- 실수 푸리에 변환(Real Fast Fourier Transform, rFFT)을 통해 시간 도메인 데이터를 주파수 도메인 데이터로 변환 후 이 영역에서 학습된 필터 중 중요한 신호만 선택적으로 증폭하거나 억제.
- 역 실수 푸리에 변환(inverse rFFT)을 사용하여 필터링된 데이터를 다시 시간 영역으로 변환
- 필터는 시계열의 시간적 구조를 보존하고, 이어지는 시간적 특징 추출에 영향을 주지 않기 위해 zero-phase filter로 제한
- 주파수 분석을 통해 잡음(noise)을 줄이고 유의미한 정보를 더 강조
※ zero-phase filter
신호의 진폭(amplitude)만을 수정하며 원본의 위상(phase) 정보는 유지
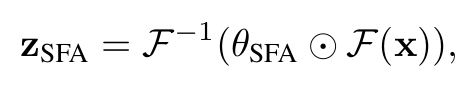
\(x\)는 입력 단변량 시계열(univariate series), \(F\)는 rFFT를, \(\theta_{SFA}\)는 학습 가능한 정적 주파수 어텐션 맵, \(\odot\)는 원소 단위 곱셈(element-wise multiplication)를 의미합니다.
2. Static Temporal Attention (STA)
- 시간 영역에서 중요한 시점만을 선별하여 중요한 시점에 높은 가중치를 부여하는 모듈
- 최근 데이터가 더 중요하다는 사실 등 시간적 중요도를 반영해 학습 효율성을 높임
- 입력 시계열에 대해 학습된 시간 어텐션 맵(temporal attention map)과 입력 데이터(\(Z_{SFA}\)의 원소 단위 곱셈(element-wise multiplication)을 수행하여 관련된 과거 시간 포인트에 적절한 중요도를 할당하여 시간적 의존성을 잘 반영

\(\theta_{STA}\)는 학습 가능한 시간 영역 어텐션 맵을 의미합니다.
3. Idependent Frequential Mapping (IFM)
- FITS에 사용된 2차원 스펙트럼 행렬은 대각선만 중요한 가중치를 가지며, 이는 시계열의 서로 다른 주파수 간의 독립성이 상대적으로 강하다는 것을 시사합니다. 이러한 배경에서 각 주파수를 독립적으로 처리하기 위한 IFM 모듈을 제안합니다.
- 구체적으로 입력 시계열(STA와 SFA를 통해 처리된)이 주파수 영역으로 변환된 후, 독립적 주파수 매핑을 사용하여 각 주파수 성분을 직접 대응되는 출력 주파수 성분으로 매핑합니다.
- 독립적인 주파수별 가중치를 사용하여 효율적인 예측 수행 후, 최종 출력을 시간 영역으로 다시 변환(inverse rFFT)
정리
- SFA는 주파수 영역에서 중요한 신호를 선택적으로 강조하여 노이즈를 감소
- STA는 시간 영역에서 중요한 입력 시점의 가중치를 높어 시간적 의존성을 효과적으로 학습
- SFA와 STA는 FC의 파라미터 중복(Parameter Redundancy) 문제를 해결하는 과정중 하나
- IFM는 각 주파수를 독립적으로 매핑하여 효율성과 해석 가능성을 동시에 높임
Low-Rank Weight Sharing
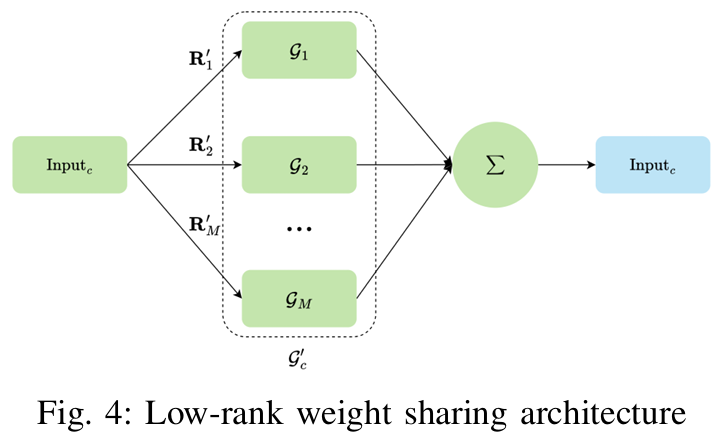
설명한 SFA, STA, IFM는 단변량(Uni Variate)를 초점으로 설계한 모듈이고, 다변량(Multi Variate)를 위해서 Low-Rank Weight Sharing을 모듈을 제안합니다.
해당 모듈은 다변량 시계열에서 각 변수 간의 상관성을 효율적으로 모델링하기 위해 사용되며, 변수들을 의미 있게 클러스터링하여 파라미터를 공유하고, 모델 복잡성을 크게 줄입니다.
구체적으로, 가중치 행렬을 저랭크(Low-Rank) 행렬로 표현하여 변수 간의 공통적인 정보(shared patterns)과 변수 고유의 특성(individual-specific patterns)을 동시에 모델링하여, 모델의 파라미터 수를 현저히 줄입니다.
SFALoss
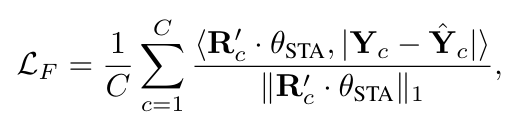
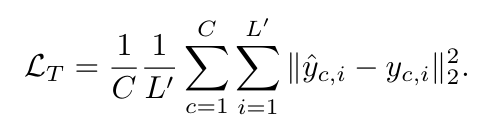
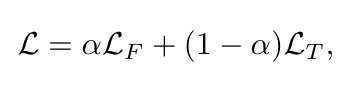
기존의 LTSF 모델들은 시간 영역에서만 손실 함수를 정의하고 사용합니다. 시간 영역 손실만으로는 주파수 영역에서의 중요한 신호 패턴을 충분히 반영하지 못할 수 있습니다. 이러한 문제를 해결하기 위해 본 논문은 시간 영역 손실과 주파수 영역 손실을 동시에 고려하는 새로운 손실 함수인 SFALoss를 제안합니다.
\(L_{T}\)는 시간 영역에서의 표준 손실 함수(ex. MSE)를 의미하며, \(L_{F}\)는 SFA모듈에서 학습된 주파수 어텐션 맵(\(\theta_{SFA}\))을 사용하여 학습된 가중치의 주파수 영역의 손실입니다. 이 손실 \(L\)은 중요한 주파수 성분에 더 많은 가중치를 부여하여 주파수 영역을 더욱 집중적으로 학습하도록 유도합니다.
Results
FCs (완전 연결 모델들)과의 비교

FCs가 아닌 모델들과의 비교

다양한 데이터셋들과의 비교

Code
[Github]
num_experts
모델의 가중치를 몇 개의 전문가(experts)로 나누어 관리할지 결정하는 변수
각 전문가는 시계열 데이터를 서로 다른 방식(독립적)으로 처리하며, 전체적인 예측은 이 전문가들의 조합으로 도출
rank_experts
각 전문가(experts)들의 상대적 중요도를 결정하는 변수
이 값들로 전문가들의 출력을 가중 평균하여 최종 결과를 도출
STA(Static Temporal Attention)
학습 가능한 시간 어텐션 맵(self.weight)을 통해 각 시간 포인트의 중요도를 반영
\(\rightarrow\) 입력 데이터에 원소 단위 곱(element-wise multiplication)을 수행하여 중요 시점에 높은 가중치를 부여
class StaticTimeWeight(nn.Module):
def __init__(self, input_len, num_experts):
super().__init__()
self.input_len = input_len
self.num_experts = num_experts
self.weight = nn.Parameter(
torch.ones(1, self.num_experts, 1, self.input_len))
def forward(self, x, rank_experts=None):
# x: N, 1, c, input_len
# if rank_experts provided, output is N, 1, c, input_len//2+1
# if not, output is N, num_experts, c, input_len//2+1
if rank_experts is not None:
weight = self.weight * rank_experts # 1, num_experts, c, input_len//2+1
weight = weight.sum(dim=1, keepdim=True) # 1, 1, c, input_len//2+1
else:
weight = self.weight
x = x * weight
return x
SFW(Static Frequential Attention)
입력 데이터를 주파수 영역으로 변환하여 주파수 어텐션 맵(self.weight)를 적용
\(\rightarrow\) 중요한 주파수를 학습하여 선택적으로 강조하거나 불필요한 주파수를 억제하여 노이즈를 줄임
이후, 다시 시간 영역으로 역변환하여 주파수 어텐션이 반영된 데이터 출력
class StaticFreqWeight(nn.Module):
# we do not use window function since it is a linear operation
def __init__(self, input_len, num_experts):
super().__init__()
self.input_len = input_len
self.num_experts = num_experts
self.weight = nn.Parameter(
torch.ones(1, self.num_experts, 1, self.input_len // 2 + 1))
def get_weight_channel(self, rank_experts):
if rank_experts is not None:
weight = self.weight * rank_experts # 1, num_experts, c, input_len//2+1
weight = weight.sum(dim=1, keepdim=True) # 1, 1, c, input_len//2+1
else:
weight = self.weight
return weight
def forward(self, x, rank_experts=None, windowing=False):
# x: N, 1, c, input_len
# if rank_experts provided, output is N, 1, c, input_len//2+1
# if not, output is N, num_experts, c, input_len//2+1
weight = self.get_weight_channel(rank_experts)
# x = F.pad(x, [self.input_len // 2, self.input_len // 2])
if windowing:
window = torch.hamming_window(self.input_len,
dtype=x.dtype,
device=x.device)
x = x * window
x = torch.fft.rfft(x)
x = x * weight
x = torch.fft.irfft(x, n=self.input_len)
if windowing:
x = x / window
# x = x[:, :, :, self.input_len // 2:-self.input_len // 2]
return x
IFM(Independent Frequential Mapping)
입력 데이터( 주파수 어텐션이 반영된 시간 데이터 )를 패딩하여 주파수 영역으로 변환
주파수 영역에서 각 주파수 성분을 독립적으로 처리
class FFTExpandBigConv1d(nn.Module):
# 专为小输入大卷积核设计
# 输入:N, 1, l_in
# 输出:N, num_experts, l_out
def __init__(
self,
num_experts: int,
input_len: int,
output_len: int,
):
super().__init__()
self.num_experts = num_experts
self.input_len = input_len
self.output_len = output_len
# we pad x 1% of length on each end... for bizzare reasons..
self.pad_len = math.floor((self.input_len + self.output_len - 1) / 100)
self.pad_len = max(self.pad_len, 1)
self.time_len = self.input_len + self.output_len - 1 + 2 * self.pad_len
self.freq_len = self.time_len // 2 + 1
# Initialized as Average filter
self.weight = nn.Parameter(
torch.zeros((1, self.num_experts, 1, self.freq_len),
dtype=torch.cfloat))
self.weight.data[..., 0] = 1
self.bias = nn.Parameter(
torch.zeros(1,
self.num_experts,
1,
self.freq_len,
dtype=torch.cfloat))
def forward(self, x: torch.Tensor, rank_experts=None):
if rank_experts is not None:
weight = self.weight * rank_experts # 1, num_experts, input_len//2+1
weight = weight.sum(dim=1, keepdim=True) # 1, 1, input_len//2+1
bias = self.bias * rank_experts
bias = bias.sum(dim=1, keepdim=True)
else:
weight = self.weight
bias = self.bias
# input: N, 1, l_in
# depth-wise convolution
# pad x to match kernel
x = F.pad(x, [self.pad_len, self.output_len - 1 + self.pad_len])
# calculate FFT
x = torch.fft.rfft(x)
# weight = torch.fft.rfft(weight)
# frequency production
x = x * weight
# bias
x = x + bias
# invert FFT
x = torch.fft.irfft(x, n=self.time_len)
x = x[..., -self.output_len - self.pad_len:-self.pad_len]
# output: N, experts, l_out if rank is None else N, 1, l_out
return x
Identity
특정 기능(모듈)을 비활성화하여 입력 데이터를 그대로 출
class Identity(nn.Module):
def __init__(self, *args: Any, **kwargs: Any) -> None:
super().__init__()
def forward(self, x: Tensor, *args: Any, **kwargs: Any) -> Tensor:
return x
DiPE
시간 모듈 (self.time_w) : STA 모듈
주파수 모듈 (self.freq_w) : SFA 모듈
주파수 매핑 모듈 (self.expert) : IFM 모듈
low-rank weight sharing (self.route) : 전체 가중치를 독립적으로 구성하는 것이 아니라, 소수의 전문가(num_experts)를 정의하여, 각 변수(features)가 이 전문가의 가중치를 공유함
Reversible Instance Normalization (RevIN) 방식의 전처리를 통해 입력 데이터를 정규화하고 예측 값을 다시 원래 척도로 변환
class DiPE(nn.Module):
def __init__(
self,
input_len: int,
output_len: int,
input_features: int,
output_features: int,
individual_f: bool = False,
individual_t: bool = False,
individual_c: bool = False,
num_experts: int = 1,
use_revin: bool = True,
use_time_w: bool = True,
use_freq_w: bool = True,
loss_alpha: float = 0.,
t_loss: Literal['mse', 'mae'] = 'mse',
):
super().__init__()
self.input_len = input_len
self.output_len = output_len
self.num_features = input_features
self.individual_f = individual_f
self.individual_t = individual_t
self.individual_c = individual_c
self.num_experts = num_experts
assert input_features == output_features
self.use_revin = use_revin
self.use_time_w = use_time_w
self.use_freq_w = use_freq_w
self.loss_alpha = loss_alpha
self.t_loss = t_loss
self.example_input_array = torch.Tensor(32, input_len, input_features)
if self.num_experts > 1:
self.route = nn.Parameter(
torch.randn(1, num_experts, self.num_features, 1))
self.temperature = 114514
self.temperature = float('nan')
self.router_softmax = nn.Softmax(dim=1)
# self.static_route = torch.eye(self.num_experts).unsqueeze(0).unsqueeze(-1)
self.static_route = torch.eye(
self.num_features).unsqueeze(0).unsqueeze(-1)
if self.use_time_w:
if self.individual_t:
self.time_w = StaticTimeWeight(self.input_len,
self.num_features)
else:
self.time_w = StaticTimeWeight(self.input_len, self.num_experts)
else:
self.time_w = Identity()
if self.use_freq_w:
if self.individual_f:
self.freq_w = StaticFreqWeight(self.input_len,
self.num_features)
else:
self.freq_w = StaticFreqWeight(self.input_len, self.num_experts)
else:
self.freq_w = Identity()
if self.individual_c:
self.expert = FFTExpandBigConv1d(self.num_features, self.input_len,
self.output_len)
else:
self.expert = FFTExpandBigConv1d(self.num_experts, self.input_len,
self.output_len)
self.dropout = nn.Dropout(0.1)
def forward(self, x):
batch_size = x.shape[0]
x = rearrange(x, 'n l c -> n 1 c l')
if self.use_revin:
x_mean = x.mean(dim=-1, keepdim=True).detach()
x_std = x.std(dim=-1, keepdim=True).detach().clamp(min=1e-7)
x = (x - x_mean) / x_std
if self.num_experts > 1:
rank_experts = self.router_softmax(self.route /
self.temperature) # 1, h, c, 1
else:
rank_experts = None
if self.individual_f:
x = self.freq_w(x, self.static_route.to(x.device))
else:
x = self.freq_w(x, rank_experts)
x = self.dropout(x)
if self.individual_t:
x = self.time_w(x, self.static_route.to(x.device))
else:
x = self.time_w(x, rank_experts)
if self.individual_c:
x = self.expert(x, self.static_route.to(x.device))
else:
x = self.expert(x, rank_experts)
if self.use_revin:
x = x * x_std
x = x + x_mean
x = rearrange(x, 'n 1 c l -> n l c')
return x
...
SFALoss
논문에서 제안된 SFALoss
시간 영역 손실(time_loss) : MSE 또는 MAE를 사용
주파수 영역 손실(freq_loss) : 주파수 영역에서 SFA 모듈의 주파수 어텐션 가중치를 이용하여 중요한 주파수 손실 강조
두 손실의 가중 합으로 최종 손실을 계산하며, 이로 인해 주파수 성분을 더 집중적으로 학습
class DiPE(nn.Module):
...
def loss(self, y, y_hat):
y = rearrange(y, 'n l c -> n c l')
y_hat = rearrange(y_hat, 'n l c -> n c l')
if self.t_loss == 'mse':
time_loss = F.mse_loss(y, y_hat)
else:
time_loss = F.l1_loss(y, y_hat)
if self.use_freq_w:
if self.num_experts > 1:
rank_experts = self.router_softmax(
self.route / self.temperature) # 1, h, c, 1
else:
rank_experts = None
if self.individual_f:
rank_experts = self.static_route.to(y.device)
freq_w = self.freq_w.get_weight_channel(rank_experts)
freq_w = freq_w.detach()
freq_w = freq_w / freq_w.mean(dim=-1, keepdim=True)
if freq_w.shape[-1] != y.shape[-1] // 2 + 1:
with torch.no_grad():
freq_w = torch.fft.irfft(freq_w, n=y.shape[-1])
freq_w = torch.fft.rfft(freq_w)
else:
freq_w = 1
fft_y = torch.fft.rfft(y, norm='ortho')
fft_y_hat = torch.fft.rfft(y_hat, norm='ortho')
freq_loss = F.l1_loss(fft_y * freq_w, fft_y_hat * freq_w)
return (1 - self.loss_alpha) * time_loss + self.loss_alpha * freq_loss
'Paper Review' 카테고리의 다른 글
| [LTSF-Linear] / [DLinear, NLinear] Are Transformers Effective for Time Series Forecasting ? (0) | 2025.03.24 |
|---|---|
| [DETR] End-to-End Object Detection with Transformers (0) | 2024.07.29 |
| [YOLO v3] An Imcremental Improvement (0) | 2024.07.24 |
| [YOLO v2] YOLO9000: Better, Faster, Stronger (0) | 2024.07.19 |
| [SSD] Single Shot MultiBox Detector (0) | 2024.07.16 |
이 논문은 장기 시계열 예측(Long-term Time Series Forecasting, LTSF)을 위한 효율적이고 해석 가능한 DiPE-Linear(Disentangled interpretable-Parameter-Efficient Linear network)를 제안합니다.
Introduction
딥러닝 모델들은 높은 정확도를 제공하지만, 블랙박스(Black Box) 특성으로 인해 사용자 신뢰를 떨어뜨립니다.
또한, 기존의 시계열 예측 방법(또는 기법)들은 다음과 같은 한계점을 가지고 있습니다.
- RNN : 병렬화가 어렵습니다.
- CNN : 높은 계산 비용을 요구합니다.
- Transformer : 여러 개선에도 불구하고 많은 수의 파라미터를 가지, 긴 입력 시퀀스에 쉽게 과적합됩니다.
- FC(Fully Connected) : 이차 복잡도(Quadratic Complexity)로 인한 파라미터 중복 ? 복제 ?(Parameter Redundancy) 문제가 있습니다.
※ 이차 복잡도 (Quadratic Complexity) [참고]
입력 데이터 크기를 \(L\)이라고 할 때, 계산량이나 메모리 사용량이 \(L^2\)에 비례하여 증가하는 현상.
※ 파라미터 중복 (Parameter Redundancy) [GPT 답변]
모델이 필요 이상으로 많은 파라미터를 가지면서 실제로 유의미하지 않거나 중복된 정보를 학습하는 현상.
\(\rightarrow\) LTSF의 경우, 긴 시퀀스을 예측해야 하기 때문에 입력 데이터 긴 시퀀스를 필요로 함. FC는 모든 입력마다 모든 출력으로 연결을 유지하므로 파라미터 수가 제곱에 비례함. 따라서, 과도하게 많은 파라미터가 존재하고 이는 비용 증가, 과적합 문제 등이 발생과 동시에 많은 파라미터들 중 중복된 파라미터들로 인해 모델 성능 향상에 기여하지 않으면서 계산 비용만 증가시키고, 최적점을 찾아가는데 방해됨.
DiPE-Linear
DiPE-Linear 모델은 다음 세 가지 모듈로 구성됩니다.
1. Static Frequential Attention (SFA)
- 실수 푸리에 변환(Real Fast Fourier Transform, rFFT)을 통해 시간 도메인 데이터를 주파수 도메인 데이터로 변환 후 이 영역에서 학습된 필터 중 중요한 신호만 선택적으로 증폭하거나 억제.
- 역 실수 푸리에 변환(inverse rFFT)을 사용하여 필터링된 데이터를 다시 시간 영역으로 변환
- 필터는 시계열의 시간적 구조를 보존하고, 이어지는 시간적 특징 추출에 영향을 주지 않기 위해 zero-phase filter로 제한
- 주파수 분석을 통해 잡음(noise)을 줄이고 유의미한 정보를 더 강조
※ zero-phase filter
신호의 진폭(amplitude)만을 수정하며 원본의 위상(phase) 정보는 유지
\(x\)는 입력 단변량 시계열(univariate series), \(F\)는 rFFT를, \(\theta_{SFA}\)는 학습 가능한 정적 주파수 어텐션 맵, \(\odot\)는 원소 단위 곱셈(element-wise multiplication)를 의미합니다.
2. Static Temporal Attention (STA)
- 시간 영역에서 중요한 시점만을 선별하여 중요한 시점에 높은 가중치를 부여하는 모듈
- 최근 데이터가 더 중요하다는 사실 등 시간적 중요도를 반영해 학습 효율성을 높임
- 입력 시계열에 대해 학습된 시간 어텐션 맵(temporal attention map)과 입력 데이터(\(Z_{SFA}\)의 원소 단위 곱셈(element-wise multiplication)을 수행하여 관련된 과거 시간 포인트에 적절한 중요도를 할당하여 시간적 의존성을 잘 반영
\(\theta_{STA}\)는 학습 가능한 시간 영역 어텐션 맵을 의미합니다.
3. Idependent Frequential Mapping (IFM)
- FITS에 사용된 2차원 스펙트럼 행렬은 대각선만 중요한 가중치를 가지며, 이는 시계열의 서로 다른 주파수 간의 독립성이 상대적으로 강하다는 것을 시사합니다. 이러한 배경에서 각 주파수를 독립적으로 처리하기 위한 IFM 모듈을 제안합니다.
- 구체적으로 입력 시계열(STA와 SFA를 통해 처리된)이 주파수 영역으로 변환된 후, 독립적 주파수 매핑을 사용하여 각 주파수 성분을 직접 대응되는 출력 주파수 성분으로 매핑합니다.
- 독립적인 주파수별 가중치를 사용하여 효율적인 예측 수행 후, 최종 출력을 시간 영역으로 다시 변환(inverse rFFT)
정리
- SFA는 주파수 영역에서 중요한 신호를 선택적으로 강조하여 노이즈를 감소
- STA는 시간 영역에서 중요한 입력 시점의 가중치를 높어 시간적 의존성을 효과적으로 학습
- SFA와 STA는 FC의 파라미터 중복(Parameter Redundancy) 문제를 해결하는 과정중 하나
- IFM는 각 주파수를 독립적으로 매핑하여 효율성과 해석 가능성을 동시에 높임
Low-Rank Weight Sharing
설명한 SFA, STA, IFM는 단변량(Uni Variate)를 초점으로 설계한 모듈이고, 다변량(Multi Variate)를 위해서 Low-Rank Weight Sharing을 모듈을 제안합니다.
해당 모듈은 다변량 시계열에서 각 변수 간의 상관성을 효율적으로 모델링하기 위해 사용되며, 변수들을 의미 있게 클러스터링하여 파라미터를 공유하고, 모델 복잡성을 크게 줄입니다.
구체적으로, 가중치 행렬을 저랭크(Low-Rank) 행렬로 표현하여 변수 간의 공통적인 정보(shared patterns)과 변수 고유의 특성(individual-specific patterns)을 동시에 모델링하여, 모델의 파라미터 수를 현저히 줄입니다.
SFALoss
기존의 LTSF 모델들은 시간 영역에서만 손실 함수를 정의하고 사용합니다. 시간 영역 손실만으로는 주파수 영역에서의 중요한 신호 패턴을 충분히 반영하지 못할 수 있습니다. 이러한 문제를 해결하기 위해 본 논문은 시간 영역 손실과 주파수 영역 손실을 동시에 고려하는 새로운 손실 함수인 SFALoss를 제안합니다.
\(L_{T}\)는 시간 영역에서의 표준 손실 함수(ex. MSE)를 의미하며, \(L_{F}\)는 SFA모듈에서 학습된 주파수 어텐션 맵(\(\theta_{SFA}\))을 사용하여 학습된 가중치의 주파수 영역의 손실입니다. 이 손실 \(L\)은 중요한 주파수 성분에 더 많은 가중치를 부여하여 주파수 영역을 더욱 집중적으로 학습하도록 유도합니다.
Results
FCs (완전 연결 모델들)과의 비교
FCs가 아닌 모델들과의 비교
다양한 데이터셋들과의 비교
Code
[Github]
num_experts
모델의 가중치를 몇 개의 전문가(experts)로 나누어 관리할지 결정하는 변수
각 전문가는 시계열 데이터를 서로 다른 방식(독립적)으로 처리하며, 전체적인 예측은 이 전문가들의 조합으로 도출
rank_experts
각 전문가(experts)들의 상대적 중요도를 결정하는 변수
이 값들로 전문가들의 출력을 가중 평균하여 최종 결과를 도출
STA(Static Temporal Attention)
학습 가능한 시간 어텐션 맵(self.weight)을 통해 각 시간 포인트의 중요도를 반영
\(\rightarrow\) 입력 데이터에 원소 단위 곱(element-wise multiplication)을 수행하여 중요 시점에 높은 가중치를 부여
class StaticTimeWeight(nn.Module):
def __init__(self, input_len, num_experts):
super().__init__()
self.input_len = input_len
self.num_experts = num_experts
self.weight = nn.Parameter(
torch.ones(1, self.num_experts, 1, self.input_len))
def forward(self, x, rank_experts=None):
# x: N, 1, c, input_len
# if rank_experts provided, output is N, 1, c, input_len//2+1
# if not, output is N, num_experts, c, input_len//2+1
if rank_experts is not None:
weight = self.weight * rank_experts # 1, num_experts, c, input_len//2+1
weight = weight.sum(dim=1, keepdim=True) # 1, 1, c, input_len//2+1
else:
weight = self.weight
x = x * weight
return x
SFW(Static Frequential Attention)
입력 데이터를 주파수 영역으로 변환하여 주파수 어텐션 맵(self.weight)를 적용
\(\rightarrow\) 중요한 주파수를 학습하여 선택적으로 강조하거나 불필요한 주파수를 억제하여 노이즈를 줄임
이후, 다시 시간 영역으로 역변환하여 주파수 어텐션이 반영된 데이터 출력
class StaticFreqWeight(nn.Module):
# we do not use window function since it is a linear operation
def __init__(self, input_len, num_experts):
super().__init__()
self.input_len = input_len
self.num_experts = num_experts
self.weight = nn.Parameter(
torch.ones(1, self.num_experts, 1, self.input_len // 2 + 1))
def get_weight_channel(self, rank_experts):
if rank_experts is not None:
weight = self.weight * rank_experts # 1, num_experts, c, input_len//2+1
weight = weight.sum(dim=1, keepdim=True) # 1, 1, c, input_len//2+1
else:
weight = self.weight
return weight
def forward(self, x, rank_experts=None, windowing=False):
# x: N, 1, c, input_len
# if rank_experts provided, output is N, 1, c, input_len//2+1
# if not, output is N, num_experts, c, input_len//2+1
weight = self.get_weight_channel(rank_experts)
# x = F.pad(x, [self.input_len // 2, self.input_len // 2])
if windowing:
window = torch.hamming_window(self.input_len,
dtype=x.dtype,
device=x.device)
x = x * window
x = torch.fft.rfft(x)
x = x * weight
x = torch.fft.irfft(x, n=self.input_len)
if windowing:
x = x / window
# x = x[:, :, :, self.input_len // 2:-self.input_len // 2]
return x
IFM(Independent Frequential Mapping)
입력 데이터( 주파수 어텐션이 반영된 시간 데이터 )를 패딩하여 주파수 영역으로 변환
주파수 영역에서 각 주파수 성분을 독립적으로 처리
class FFTExpandBigConv1d(nn.Module):
# 专为小输入大卷积核设计
# 输入:N, 1, l_in
# 输出:N, num_experts, l_out
def __init__(
self,
num_experts: int,
input_len: int,
output_len: int,
):
super().__init__()
self.num_experts = num_experts
self.input_len = input_len
self.output_len = output_len
# we pad x 1% of length on each end... for bizzare reasons..
self.pad_len = math.floor((self.input_len + self.output_len - 1) / 100)
self.pad_len = max(self.pad_len, 1)
self.time_len = self.input_len + self.output_len - 1 + 2 * self.pad_len
self.freq_len = self.time_len // 2 + 1
# Initialized as Average filter
self.weight = nn.Parameter(
torch.zeros((1, self.num_experts, 1, self.freq_len),
dtype=torch.cfloat))
self.weight.data[..., 0] = 1
self.bias = nn.Parameter(
torch.zeros(1,
self.num_experts,
1,
self.freq_len,
dtype=torch.cfloat))
def forward(self, x: torch.Tensor, rank_experts=None):
if rank_experts is not None:
weight = self.weight * rank_experts # 1, num_experts, input_len//2+1
weight = weight.sum(dim=1, keepdim=True) # 1, 1, input_len//2+1
bias = self.bias * rank_experts
bias = bias.sum(dim=1, keepdim=True)
else:
weight = self.weight
bias = self.bias
# input: N, 1, l_in
# depth-wise convolution
# pad x to match kernel
x = F.pad(x, [self.pad_len, self.output_len - 1 + self.pad_len])
# calculate FFT
x = torch.fft.rfft(x)
# weight = torch.fft.rfft(weight)
# frequency production
x = x * weight
# bias
x = x + bias
# invert FFT
x = torch.fft.irfft(x, n=self.time_len)
x = x[..., -self.output_len - self.pad_len:-self.pad_len]
# output: N, experts, l_out if rank is None else N, 1, l_out
return x
Identity
특정 기능(모듈)을 비활성화하여 입력 데이터를 그대로 출
class Identity(nn.Module):
def __init__(self, *args: Any, **kwargs: Any) -> None:
super().__init__()
def forward(self, x: Tensor, *args: Any, **kwargs: Any) -> Tensor:
return x
DiPE
시간 모듈 (self.time_w) : STA 모듈
주파수 모듈 (self.freq_w) : SFA 모듈
주파수 매핑 모듈 (self.expert) : IFM 모듈
low-rank weight sharing (self.route) : 전체 가중치를 독립적으로 구성하는 것이 아니라, 소수의 전문가(num_experts)를 정의하여, 각 변수(features)가 이 전문가의 가중치를 공유함
Reversible Instance Normalization (RevIN) 방식의 전처리를 통해 입력 데이터를 정규화하고 예측 값을 다시 원래 척도로 변환
class DiPE(nn.Module):
def __init__(
self,
input_len: int,
output_len: int,
input_features: int,
output_features: int,
individual_f: bool = False,
individual_t: bool = False,
individual_c: bool = False,
num_experts: int = 1,
use_revin: bool = True,
use_time_w: bool = True,
use_freq_w: bool = True,
loss_alpha: float = 0.,
t_loss: Literal['mse', 'mae'] = 'mse',
):
super().__init__()
self.input_len = input_len
self.output_len = output_len
self.num_features = input_features
self.individual_f = individual_f
self.individual_t = individual_t
self.individual_c = individual_c
self.num_experts = num_experts
assert input_features == output_features
self.use_revin = use_revin
self.use_time_w = use_time_w
self.use_freq_w = use_freq_w
self.loss_alpha = loss_alpha
self.t_loss = t_loss
self.example_input_array = torch.Tensor(32, input_len, input_features)
if self.num_experts > 1:
self.route = nn.Parameter(
torch.randn(1, num_experts, self.num_features, 1))
self.temperature = 114514
self.temperature = float('nan')
self.router_softmax = nn.Softmax(dim=1)
# self.static_route = torch.eye(self.num_experts).unsqueeze(0).unsqueeze(-1)
self.static_route = torch.eye(
self.num_features).unsqueeze(0).unsqueeze(-1)
if self.use_time_w:
if self.individual_t:
self.time_w = StaticTimeWeight(self.input_len,
self.num_features)
else:
self.time_w = StaticTimeWeight(self.input_len, self.num_experts)
else:
self.time_w = Identity()
if self.use_freq_w:
if self.individual_f:
self.freq_w = StaticFreqWeight(self.input_len,
self.num_features)
else:
self.freq_w = StaticFreqWeight(self.input_len, self.num_experts)
else:
self.freq_w = Identity()
if self.individual_c:
self.expert = FFTExpandBigConv1d(self.num_features, self.input_len,
self.output_len)
else:
self.expert = FFTExpandBigConv1d(self.num_experts, self.input_len,
self.output_len)
self.dropout = nn.Dropout(0.1)
def forward(self, x):
batch_size = x.shape[0]
x = rearrange(x, 'n l c -> n 1 c l')
if self.use_revin:
x_mean = x.mean(dim=-1, keepdim=True).detach()
x_std = x.std(dim=-1, keepdim=True).detach().clamp(min=1e-7)
x = (x - x_mean) / x_std
if self.num_experts > 1:
rank_experts = self.router_softmax(self.route /
self.temperature) # 1, h, c, 1
else:
rank_experts = None
if self.individual_f:
x = self.freq_w(x, self.static_route.to(x.device))
else:
x = self.freq_w(x, rank_experts)
x = self.dropout(x)
if self.individual_t:
x = self.time_w(x, self.static_route.to(x.device))
else:
x = self.time_w(x, rank_experts)
if self.individual_c:
x = self.expert(x, self.static_route.to(x.device))
else:
x = self.expert(x, rank_experts)
if self.use_revin:
x = x * x_std
x = x + x_mean
x = rearrange(x, 'n 1 c l -> n l c')
return x
...
SFALoss
논문에서 제안된 SFALoss
시간 영역 손실(time_loss) : MSE 또는 MAE를 사용
주파수 영역 손실(freq_loss) : 주파수 영역에서 SFA 모듈의 주파수 어텐션 가중치를 이용하여 중요한 주파수 손실 강조
두 손실의 가중 합으로 최종 손실을 계산하며, 이로 인해 주파수 성분을 더 집중적으로 학습
class DiPE(nn.Module):
...
def loss(self, y, y_hat):
y = rearrange(y, 'n l c -> n c l')
y_hat = rearrange(y_hat, 'n l c -> n c l')
if self.t_loss == 'mse':
time_loss = F.mse_loss(y, y_hat)
else:
time_loss = F.l1_loss(y, y_hat)
if self.use_freq_w:
if self.num_experts > 1:
rank_experts = self.router_softmax(
self.route / self.temperature) # 1, h, c, 1
else:
rank_experts = None
if self.individual_f:
rank_experts = self.static_route.to(y.device)
freq_w = self.freq_w.get_weight_channel(rank_experts)
freq_w = freq_w.detach()
freq_w = freq_w / freq_w.mean(dim=-1, keepdim=True)
if freq_w.shape[-1] != y.shape[-1] // 2 + 1:
with torch.no_grad():
freq_w = torch.fft.irfft(freq_w, n=y.shape[-1])
freq_w = torch.fft.rfft(freq_w)
else:
freq_w = 1
fft_y = torch.fft.rfft(y, norm='ortho')
fft_y_hat = torch.fft.rfft(y_hat, norm='ortho')
freq_loss = F.l1_loss(fft_y * freq_w, fft_y_hat * freq_w)
return (1 - self.loss_alpha) * time_loss + self.loss_alpha * freq_loss
'Paper Review' 카테고리의 다른 글
| [LTSF-Linear] / [DLinear, NLinear] Are Transformers Effective for Time Series Forecasting ? (0) | 2025.03.24 |
|---|---|
| [DETR] End-to-End Object Detection with Transformers (0) | 2024.07.29 |
| [YOLO v3] An Imcremental Improvement (0) | 2024.07.24 |
| [YOLO v2] YOLO9000: Better, Faster, Stronger (0) | 2024.07.19 |
| [SSD] Single Shot MultiBox Detector (0) | 2024.07.16 |