
YOLO v2
YOLO v1은 1 stage object detector로 빠른 처리 속도를 가지지만, 2 stage object detector 보다 성능이 떨어진다는 한계가 존재했습니다. SSD는 이미지의 크기를 300x300으로 학습 시켰을 경우 처리 속도가 빠르지만 정확도가 낮으며 512x512로 학습시켰을 경우 정확도가 높가지만 처리 속도가 느린 trade off 관계를 가집니다. YOLO v2는 이를 개선하여 성능이 좋으면서 속도도 빠르도록 다양한 아이디어를 도입했습니다. 또한, Object Detection 데이터셋과 Classification 데이터셋을 합쳐 9000개 이상의 클래스를 탐지할 수 있는 YOLO 9000 모델도 제안합니다.
본 논문은 다음과 같이 3개의 파트로 구성되어 있습니다.
- Better : 정확도를 높이기 위한 방법
- Faster : detection 속도를 향상시키기 위한 방법
- Stronger : 더 많은 범위의 class를 예측하기 위한 방법
Better
논문의 저자가 한 고민과 실험을 순서대로 살펴봅니다.
1. Batch Normalization
Batch Normalization의 장점은 다음과 같습니다.
- 정규화된 입력으로 인해 학습 과정을 안정화 시키고, 더 빠른 학습 속도를 가지는 데 도움을 줍니다.
- 약간의 규제(Regularization) 효과를 제공하여 과적합(Overfitting)을 줄이면서 Dropout을 제거할 수 있습니다.
이를 통해 mAP 값이 2% 정도 향상되었습니다.
2. High Resolution Classifier
YOLO v1은 224x224 크기의 이미지로 ImageNet 데이터셋으로 pre-train 시키고, detection task를 위해 448x448 크기로 fine-tuning 시켰습니다. 이는 모델 입장에서 생각해 보면 높은 해상도의 이미지에 적응하는 것과 object detection task를 동시에 학습해야 한다는 말이 됩니다. 이러면 모델 입장에서 당연히 더 어렵게 느껴지게 됩니다. 따라서, 논문 저자들을 처음부터 448x448 사이즈의 이미지로 ImagNet 데이터셋을 10 epoch 학습합니다. 그리고 동일한 사이즈로 detection task를 학습합니다.
이를 통해 mAP 값이 3.7% 정도 향상되었습니다.
3. Convolutional with Anchor Boxes
YOLO v1은 anchor box 방법을 도입하지 않고, 모든 feature 마다 bounding box의 모양과 위치를 예측하도록 했습니다.
반면 Faster R-CNN은 사전에 9개의 anchor box를 정의한 후 bounding box regression을 통해 x, y 좌표와 aspect ratio(offset)을 조정하는 과정을 거칩니다. 좌표 대신 offset을 예측하는 문제가 보다 단순하고 네트워크가 학습하기 쉽다는 장점이 있습니다.
anchor box 방식을 도입으로 mAP 성능이 0.3% 하락한 모습을 확인할 수 있었습니다. 하지만, recall은 더 증가하였기 때문에 anchor box 방식을 도입하되 조금 더 개선하면 성능이 향상될 여지가 있음을 나타냅니다.
Object Detection task에서 recall 값이 높다는 것은 모델이 실제 객체의 위치를 예측한 비율이 높음을 의미합니다. YOLO v1이 recall 값이 낮은 이유는 region proposal 기반의 모델에 비해 이미지 당 상대적으로 적은 수의 bounding box를 예측하기 때문입니다. 하지만 YOLO v2에서 anchor box의 도입으로 인해 더 많은 bounding box를 예측하면서, 실제 객체의 위치를 보다 잘 포착하고 이로 인해 recall 값이 상승하게 됩니다.
4. New Network
YOLO v2는 기존의 네트워크 구성에 살짝 변형을 주었습니다. 우선 output이 더 높은 resolution을 가지도록 pooling layer를 제거합니다. 또한, 입력 이미지를 448x448이 아닌 416x416으로 변경합니다. 이는 최종 output feature map의 크기가 홀수(13x13)가 되도록하여, feature map 내의 하나의 중심 cell (single center cell)이 존재할 수 있도록 하기 위함입니다. 보통 object detection 데이터셋은 이미지의 정중앙에 위치하는 물체들이 많습니다 .따라서 이미지의 정중앙에서 box를 예측하는 것이 유리할 것이고, 이를 위해서는 최종 feature map의 사이즈가 홀수가 되어야 합니다.
이를 통해 mAP 값이 0.4% 정도 향상되었습니다.
5. Dimension Cluster
anchor box를 도입할 때는 꼭 고려해야 하는 사항이 있습니다.
바로 사람이 지정해줘야 하는(hand-picked) anchor box의 모양과 사이즈입니다. 이렇게 지정해주는 anchor box의 모양과 사이즈에 따라 모델의 성능이 크게 차이나기 때문입니다.
하지만, 논문 저자들은 "학습 데이터셋의 bounding box의 ground truth를 사용해서 최적의 anchor box 모양과 사이즈를 찾을 수 없을까 ?"를 생각하여 다음과 같은 아이디어를 떠올립니다.
바로 k-means clustering을 사용하는 것 입니다. 일반적인 k-means clustering은 유클리드 거리를 사용하여 k개의 클러스터를 찾는 방식입니다. 유클리드 방식은 큰 bounding box는 작은 box에 비해 큰 error를 발생시키는 문제가 있습니다. 따라서, 측정 metric을 유클리드에서 IoU 관련 식으로 변경합니다. 그 metric은 다음과 같습니다.
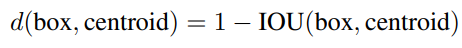
이는 box와 centroid의 IoU 값이 클수록 겹치는 영역이 크기 때문에 거리가 가깝다는 점을 나타냅니다.
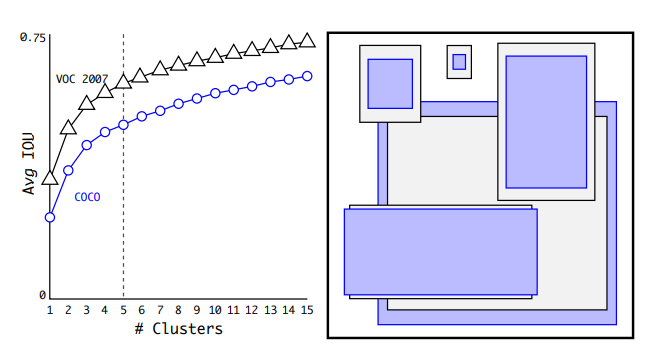
위 그림의 왼쪽은 cluster 개수에 따른 성능을 측정한 그래프입니다.
cluster의 개수가 많아질수록 다양한 모양과 사이즈의 anchor box를 사용한다는 의미이니 성능이 좋아지는 모습을 확인할 수 있습니다. 하지만, anchor box를 많이 사용할수록 모델은 계산량이 많아져 복잡하고 느리게 됩니다. 따라서 YOLO v2에서는 성능과 복잡도 사이의 trade off 지점으로 5개의 anchor box를 선택합니다.
위 그림의 오른쪽은 이렇게 찾은 VOC와 COCO 데이터셋에서의 anchor box 모양입니다.
기존에 사용하던 anchor box의 모양과는 달리 얇고 길쭉한 모양의 anchor box들이 많은 모습을 볼 수 있습니다.
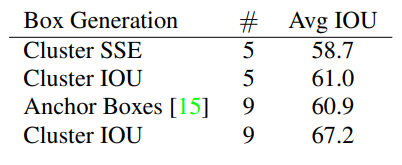
위 그림은 cluster 방식으로 찾은 anchor box를 사용했을 때와 기존처럼 사람이 지정해 주는 방식으로 찾은 anchor box를 사용했을 때의 성능 비교 표 입니다.
Anchor Boxes가 기존 방식을 의미하는데, 9개의 anchor box를 사용하여 60.9 IoU의 성능을 내는 모습을 확인할 수 있습니다. 반면, Cluster 방식은 anchorbox를 5개만 사용해도 61.0 IoU 를 달성했고, 9개 까지 늘린다면 67.2 IoU 까지 성능이 대폭 향상하는 모습을 확인할 수 있습니다.
6. Direct Location Prediction
하지만 아직도 anchor box를 도입했을 때의 문제점은 남아있습니다.
anchor box 방식을 사용하면 학습 초기에 모델이 불안정한 모습을 보인다는 것 입니다. anchor box는 bounding box regressor 계수(coefficient)를 통해 다음 공식과 같이 bounding box의 위치를 조정합니다.
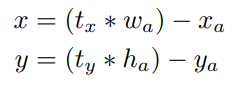
모델은 \(t_x\), \(t_y\)를 예측하고 가중치를 곱해서 계산해주는 방법입니다. 하지만, \(t_x\), \(t_y\)와 같은 계수는 제한된 범위가 없기 때문에 anchor box는 이미지 내의 임의의 지점에 위치할 수 있다는 문제가 있습니다. 따라서 모델 입장에서는 모든 범위에 대한 계산을 해야 하기 때문에 학습 초기에 어려움을 겪는 것이죠.
그래서 x, y, w, h를 예착하는 방법은 YOLO v1에서 사용했던 방식을 도입합니다. Grid Cell (Feature) 안에서의 상대 위치를 예측하는 방법입니다. 이는 예측하는 bounding box의 좌표는 0 ~ 1 사이의 값으로 제한해서 모델에게 너무 넓은 범위를 예측해야 하는 부담을 주지 않는 것 입니다.
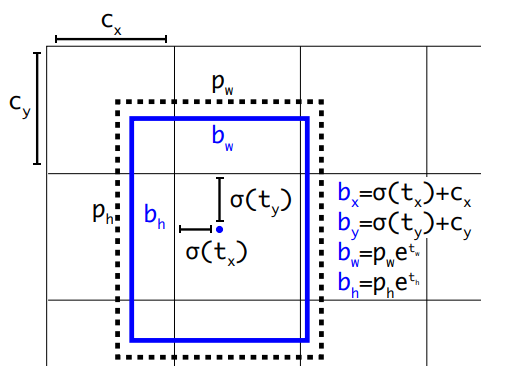
위 그림은 YOLO v2의 anchor box location 계산 방법을 도식화한 그림입니다.
- \(p\) : 미리 정해준 anchor box 값 (prior)
- \(t\) : 모델이 예측한 값
- \(\sigma\) : Logistic regression (output을 0~1 사이의 값으로)
- \(b\) : 최종 계산된 bounding box location
- \(c\) : cell 에서의 offset
기존과 달리 모델의 예측값에 logistic regression 함수가 더해진 모습을 볼 수 있습니다. 따라서 output을 0~1로 제한하여 모델이 더 편하게 학습할 수 있도록 만들었습니다.
이를 통해 mAP 값이 4.8% 정도 향상되었습니다.
7. Fine-Grained Features
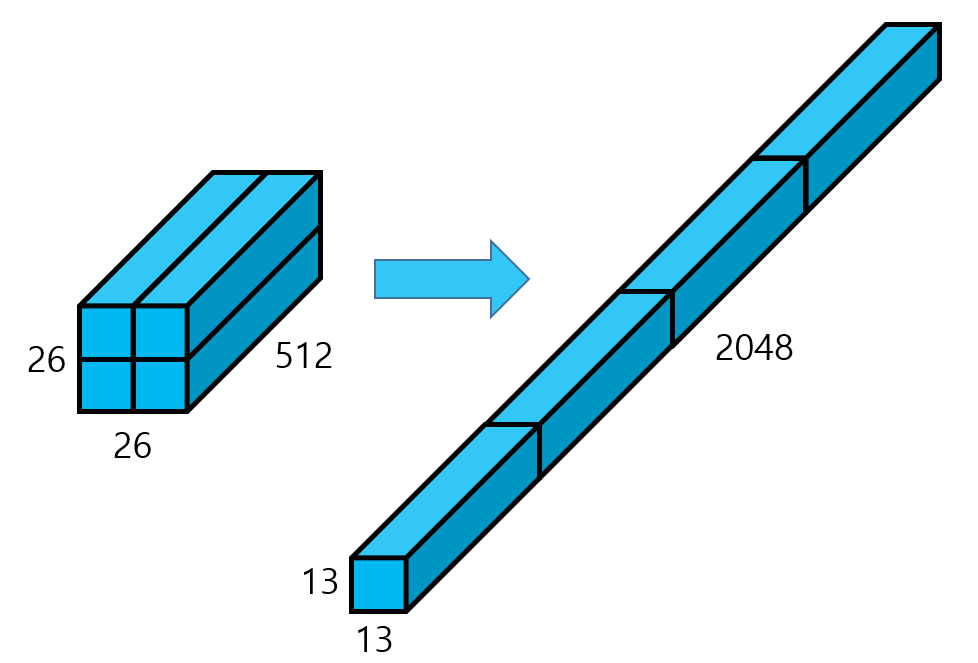
다양한 level의 feature를 사용하면 object detection 성능에 유리합니다. 특히 작은 물체들을 찾기 위해 보다 해상도가 높은 feature를 사용하면 유리합니다. 그래서 SSD 처럼 다양한 level의 feature를 같이 사용할 수 있는 방법들이 제안되었습니다.
YOLO v2의 경우는 최종적으로 13x13 크기의 feature map를 출력합니다. 그리고 직전의 26x26의 크기를 가진 feature map을 얻어 위 그림과 같이 channel을 유지하면서 4개로 분할한 후 결합(concat)하여 13x13x2048 크기의 feature map을 얻습니다. 이러한 feature map은 보다 작은 객체에 대한 정보를 압축하고 있습니다. 이를 13x13x1024 feature map에 추가하여 총 13x13x3072 크기의 feature map을 얻습니다. 즉 이 feature map은 작은 객체에 대한 정보(fine-grained)를 함축하고 있습니다.
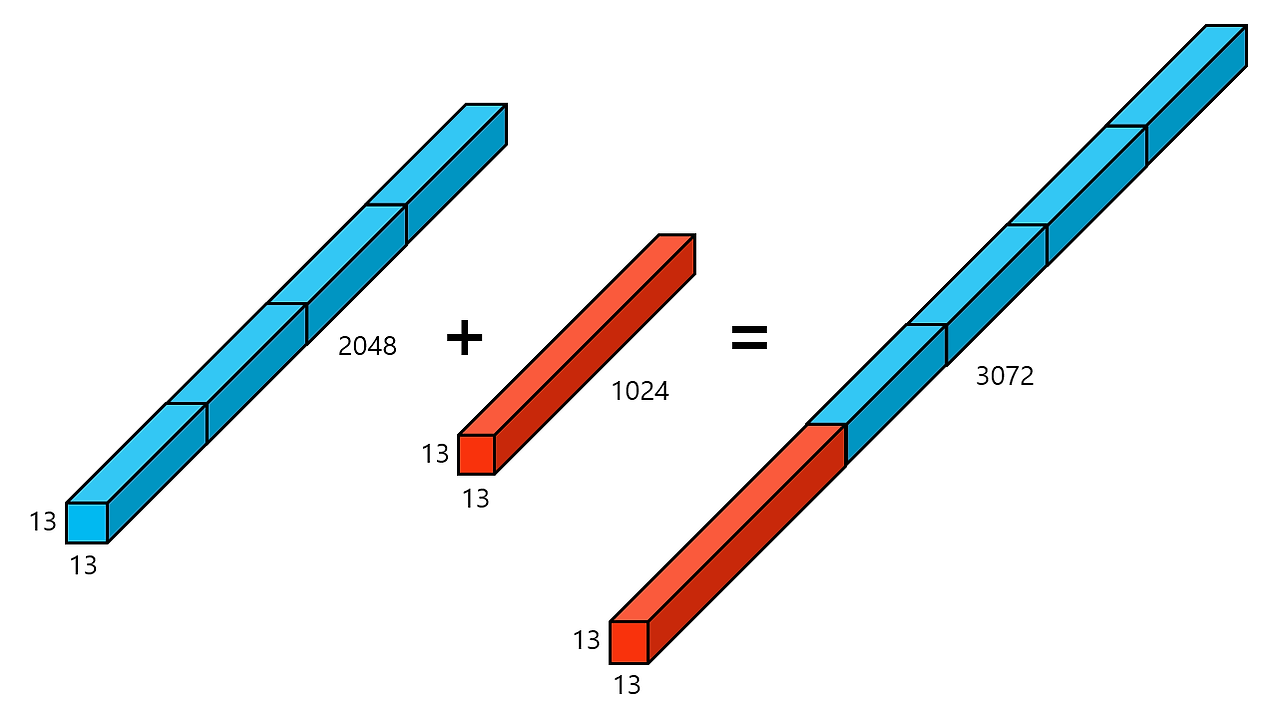
최종적으로 3x3 Conv와 1x1 Conv를 적용하여 13x13x125 크기의 feature map을 얻습니다. channel 수가 125인 이유는 각 grid cell 별로 5개의 bounding box가 20개의 class와 score (confidence , x, y, w, h)를 예측하기 때문입니다. (5 x (20 + 5))
이를 통해 mAP 값이 1% 정도 향상되었습니다.
8. Multi Scale Training
보통은 고정된 입력 사이즈로 모델을 학습합니다. 따라서 학습 데이터와 다른 사이즈의 이미지에 대해서는 성능이 대폭 하락하곤 합니다.
이에 YOLO v2는 multi scale training 방법을 사용합니다. 말 그대로 입력 이미지의 크기를 계속해서 바꿔주는 것 입니다.
10 batch 마다 입력 크기를 변경햊주었습니다. 이때 모델은 입력 이미지를 32배로 downsampling 하여 최종 output feature를 만들기 때문에, 입력 이미지 사이즈도 32 배수에 맞추어 조정해 주었습니다. 가장 작은 사이즈는 320x320이고, 가장 큰 사이즈는 608x608 입니다.
이를 통해 mAP 값이 1.4% 정도 향상되었습니다.
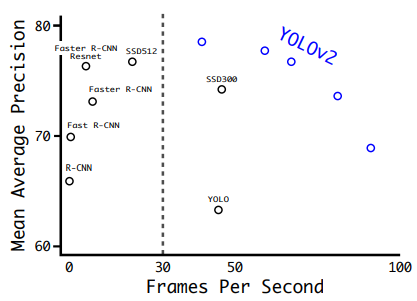
위 그림은 다양한 사이즈에 대한 YOLO v2와 다른 방법들의 성능을 비교한 그림입니다.
YOLO v2가 가장 낮은 속도일 때 (가장 큰 입력 이미지를 받을 때)의 성능은 기존 SOTA 모델들보다 높은 모습을 볼 수 있습니다. 그럼에도 속도는 훨씬 빠른 모습을 보입니다. YOLO v2의 속도를 높이면 (입력 이미지 사이즈를 줄이면) 성능은 조금씩 떨어지지만 기존 방법들에 필적하는 성능을 보이며, 속도는 비교도 안되게 빠른 모습을 볼 수 있습니다.
이렇게 다양한 방법을 사용하여 기존 YOLO v1의 성능을 개선한 모델을 YOLO v2라고 부릅니다.
Faster
YOLO v2는 Darknet-19라는 독자적인 Classification 모델을 backbone network로 사용합니다.
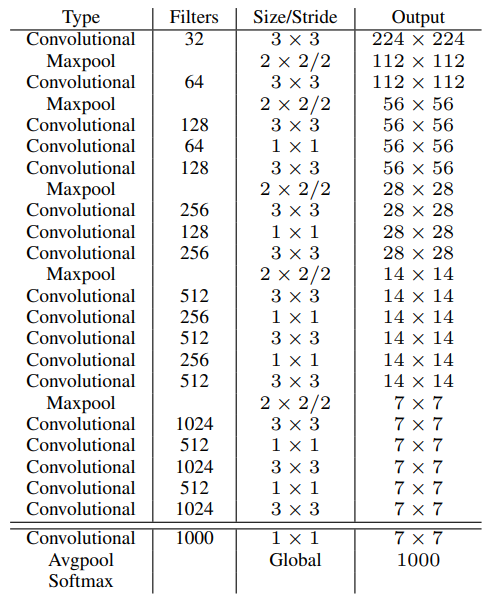
YOLO v1은 네트워크 마지막에 fc layer를 통해 예측을 수행합니다. 하지만 fc layer로 인해 파라미터 수가 증가하고 detection 속도가 느려진다는 단점을 가지고 있습니다. YOLO v2의 Darknet-19는 마지막 layer에 global average pooling을 사용하여 fc layer를 제거하였고, 그 결과 파라미터 수를 감소시키고 detection 속도를 향상시켰습니다.
Training for Classification
Darknet-19는 class의 수가 1000개인 ImageNet 데이터셋을 통해 학습시킵니다. 위의 Darknet-19 에서 output 수가 1000개인 이유입니다. 학습 결과 top-1 정확도는 76.5%, top-5 정확도는 93.3%의 성능을 보였습니다.
Training for Detection
Darknet-19를 detection task로 사용하기 위해 마지막 conv layer를 제거한 후 3x3x1024 conv layer로 대체하고, 이후 1x1 conv layer를 추가합니다. 이 때 1x1 conv layer의 채널 수는 예측할 때 필요한 수로 125개로 지정합니다. ( 5 (bounding box) x (20 (PASCAL VOC 데이터셋 클래스 수) + 5 (confidence score, x, y, w, h))
Stronger
Stronger이 의미하는 것은 더 많은 종류의 객체를 탐지하는 능력을 의미합니다. 논문에서는 YOLO v2를 classification 데이터와 detection 데이터를 함께 사용하여 학습시킴으로써 보다 많은 class(약 9000개)를 예측하는 YOLO 9000을 소개합니다.
Object Detction과 Classification 데이터셋은 서로 다른 장단점을 가지고 있습니다. Object Detection 데이터셋에는 bounding box에 해당하는 location 정보가 있지만 적은 종류의 class를 가지고 있습니다. 반면, Classification 데이터셋은 location 정보는 없지만 매우 다양한 class를 가지고 있습니다. 그래서 자연스럽게 Object Detection 모델에서도 Classification 데이터셋을 활용할 수 없을까? 하는 생각에, 저자들은 단순히 따로 학습하는 방법을 넘어 두 데이터셋을 통합하여 한번에 학습하는 방법을 고민합니다.
가장 쉽게 떠올릴 수 있는 아이디어는, Classification 데이터셋 에서는 classification loss 만을 받아서 학습하고, Detection 데이터셋에서는 location loss, classification loss 을 학습하는 것 입니다. 하지만 두 데이터셋은 클래스가 서로 다르다는 큰 문제점이 있습니다. 예를 들어 Detection 데이터셋은 모든 개 이미지를 "개"라는 하나의 클래스로 분류하는 반면, Classification 데이터셋은 "불독", "치와와" 등 개 의 종류를 세부적으로 분류할 수 있는 클래스로 분류합니다.
Hierarchical Classification
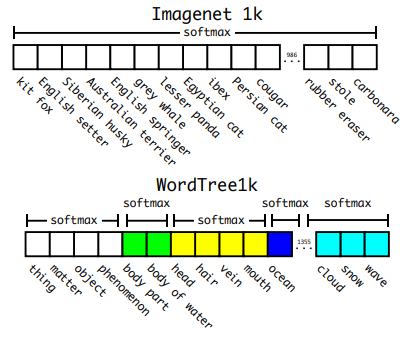
이러한 문제를 해결하기 위해 ImageNet label로 부터 계층적인 트리(Hierarchical tree)인 WordTree를 구성하는 방법을 논문에서 제안합니다. WordTree에서 각 노드는 범주를 의미하고 하위 범주는 자식 노드가 되는 구조를 가지고 있습니다. 예를 들어 "Yorkshierterrier"라는 범주 혹은 노드는 "root(물리적 객체, physical object) - 동물 - 포유류 - 사냥개 - 테리어" 노드를 거쳐 도달할 수 있습니다. 이러한 트리에서 특정 범주에 속할 확률은 루트 노드로부터 해당 범주까지의 조건부 확률의 곱으로 표현할 수 있습니다.

Dataset Combination with WordTree
이와 같이 계측적 구조 방법을 사용해 ImageNet 데이터와 COCO 데이터를 합쳐 WordTree를 구성할 수 있습니다.
Joint Classification and Detection
논문에서는 COCO 데이터셋과 ImageNet 데이터셋을 합쳐 9418개의 범주를 가지는 WordTree를 구성합니다. 이 때 ImageNet과 COCO 데이터셋의 비율이 4 : 1 이 되도록 조정합니다.
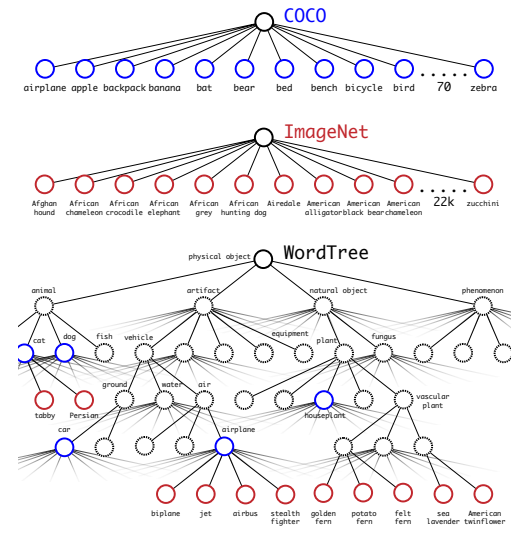
detection loss는 평소와 같이 loss를 backward pass하며, classification loss의 경우에는 특정 범주와 상위 범주에 대해서만 loss를 계산합니다. 예를 들어, "개"라는 범주에 대해서 detection 데이터셋은 하위 범주를 포함하고 있지 않기 때문에, "물리적 객체 - 동물 - 포유류 - 개"에 대한 조건부 확률을 사용해서 loss를 구합니다.
만약 네트워크가 classification 데이터셋의 이미지를 보면 오직 classification loss에 대하여 backward pass를 수행합니다. 이 때 ground truth box와의 IoU 값이 0.3 이상인 경우에만 역전파를 수행합니다.
이와 같은 Joint Training 방식을 통해 YOLO 9000 모델은 COCO 데이터셋을 활용하여 이미지 내에서 객체를 찾는 detection task와 ImageNet 데이터셋을 통해 보다 넓은 범주의 개체를 분류할 수 있도록 학습됩니다.
Conclusion
YOLO v2는 다야한 기법과 구조의 변형 덕분에 mAP가 78.6% 로 크게 향상되었음에도불구하고, 실기간 처리 속도 또한 매우 높았습니다. 하지만, 여전히 큰 객체에 비해 작은 객체 감지 성능이 낮았고, 많은 객체가 밀집된 복잡한 장면에서는 여전히 어려움을 겪습니다.
참고
[1] https://arxiv.org/pdf/1612.08242
[2] https://ffighting.net/deep-learning-paper-review/object-detection/yolo-v2/
'Paper Review' 카테고리의 다른 글
| [DETR] End-to-End Object Detection with Transformers (0) | 2024.07.29 |
|---|---|
| [YOLO v3] An Imcremental Improvement (0) | 2024.07.24 |
| [SSD] Single Shot MultiBox Detector (0) | 2024.07.16 |
| [YOLO v1] You Only Look Once: Unified, Real-Time Object Detection (0) | 2024.07.15 |
| [ViT] Vision Transformer, AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (0) | 2024.07.12 |