
YOLO v3
YOLO v3는 기존의 YOLO에서 최신 기법들을 적용하여 성능을 개선한 모델입니다. 세부적으로, Loss 측정 방법, Feature 추출 방법 등에서의 차이를 중점적으로 다룹니다. YOLO v3는 IoU threshold 50%를 기준으로 측정했을 때 기존 SOTA들보다 성능이 우수하고 작은 객체에 대한 성능이 개선되었습니다. 하지만, 높은 IoU와 큰 물체에서 성능이 떨어지는 한계를 가지기도 합니다.
YOLO와 YOLO v3의 차이
Bounding Box Prediction
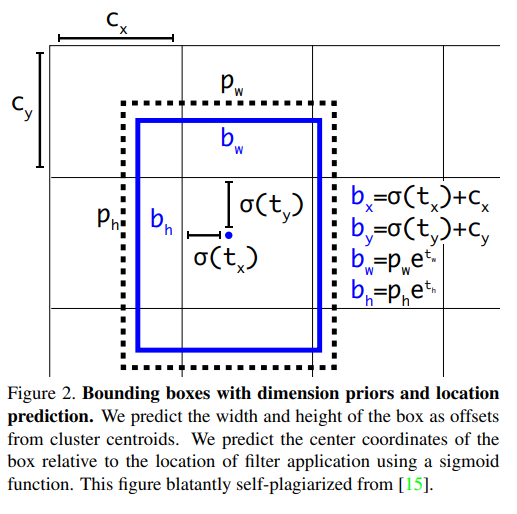
YOLO v2에서는 예측한 bounding box \(t\)값 \(t_x, t_y, t_w, t_h\)를 구하고, 적절한 수식을 통해 \(b\)값 \(b_x, b_y, b_w, b_h\)으로 변경한 후 L2 Loss를 통해 학습시켰습니다. 하지만 YOLO v3는 다음 공식을 거쳐 \(t_*\)로 변형시킨 후 \(t_x\)와 Loss계산을 통해 학습 시키는 방식을 선택합니다.
$$ b_* = \sigma (t_*) + c_x $$
$$ \sigma (t_*) = b_* - c_* $$
$$ t_* = log(b_* - c_*) $$
즉, \(b\)값을 사용하지 않고, \(t\)값을 사용하여 localization loss를 계산해 줍니다. 모델에서 예측한 \(t\)값들과 Ground Truth 정보를 통해 역산한 \(t_*\)값들이 서로 같아지도록 localization loss를 구성하는 것이죠.
Class Prediction
기존의 YOLO는 softmax와 cross entropy를 사용하여 class를 구분했습니다. 여기서 softmax를 사용하여 class를 예측하는 경우 모든 클래스의 확률 합이 1이 되도록 가제하며, 한 객체가 하나의 클래스에만 속한다고 가정합니다. 예를 들어, 한 객체가 "여성" 이면서 "운동선수"일 경우 각각의 확률이 높더라도, softmax를 사용하면 이 두 클래스의 확률 합이 1을 넘을 수 없습니다. 이러한 제한적인 성격 때문에 YOLO 3에서는 binary cross-entropy를 사용합니다.
binary cross entropy는 각 클래스를 독립적으로 처리하여, 한 객체가 여러 클래스에 동시에 속할 수 있도록 합니다. 즉, 각각의 bounding box는 multi-label classification을 수행합니다. 이러한 접근 방식은 특히 복잡한 데이터셋이나 클래스 간 상관관계가 있는 경우에 성능을 향상시킵니다.
Loss Function
기본적으로 YOLO는 3가지의 loss로 구성되어 있습니다.
1. Localization Loss : 예측한 bounding box의 위치를 더 정확하게 맞추는 역할
2. Objectness Loss : 해당 feature에서 예측한 bounding box에 물체가 있는지, 없는지를 예측하는 역할
3. Classification Loss : 해당 bounding box에 물체가 있다면, 물체의 클래스가 무엇인지 맞추는 역할
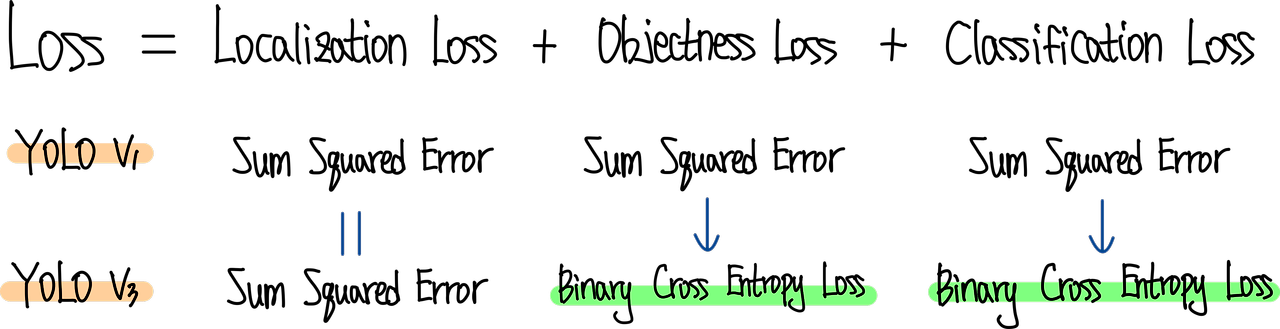
위 그림은 YOLO v1과 YOLO v3의 Loss의 상세 구성을 비교한 그림입니다. YOLO v3에서는 Objectness Loss와 Classification Loss는 Binary Corss Entropy Loss를 사용했습니다.
Prediction Across Scales
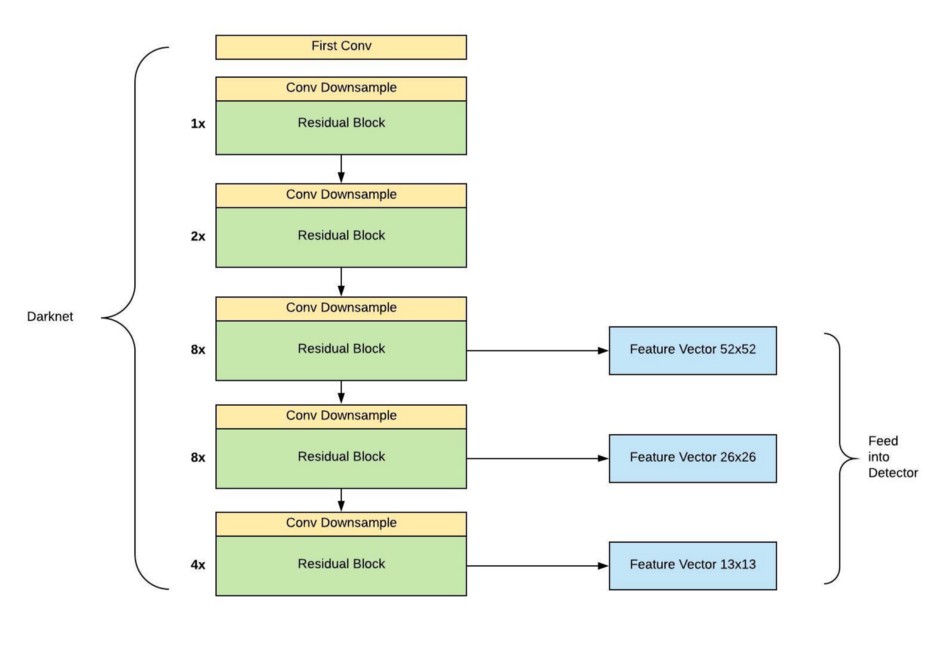
YOLO v3는 서로 다른 3개의 scale을 사용하여 최종 결과를 예측합니다. 여기서 multi-scale feature map을 얻는 방법은 FPN과 유사합니다. 먼저 416x416 크기의 이미지를 네트워크에 입력하여 feature map의 크기가 52x52, 26x26, 13x13이 되는 layer에서 feature map을 추출합니다.
그 다음 가장 높은 level, 즉 해상도가 가장 낮은 feature map을 1x1, 3x3 Conv Layer로 구성된 작은 FCN(Fully Convolutional Network)에 입력합니다. 이후 FCN의 output channel이 512가 되는 지점에서 feature map을 추출한 뒤 2배로 up-sampling을 수행합니다. 이후 바로 아래 level에 있는 즉 해상도가 2배인 feature map과 concatenate합니다. 이렇게 merged된 feature map은 다시 다음 level에 있는 feature map 에서도 똑같이 수햅합니다. 이를 통해 3개의 scale을 가진 feature map을 얻을 수 있습니다.
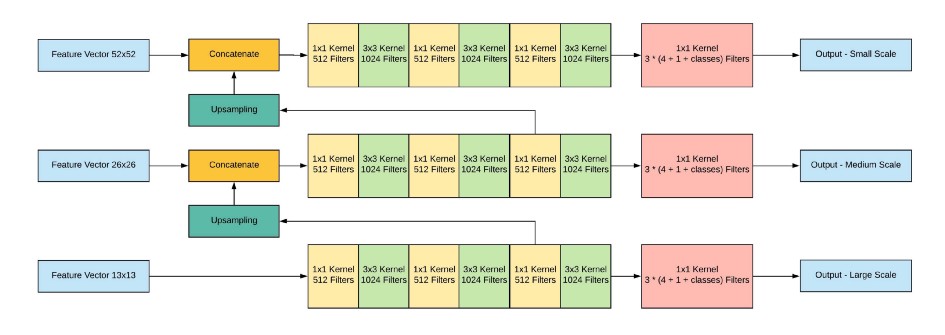
이 때 각 scale에 해당하는 feature map의 output channel 수가 (3 x (4 + 1 + 80) = 255)가 되도록 마지막 1x1 Conv Layer의 channel 수를 조정합니다. 여기서 3은 각 gride cell이 예측하는 anchor box의 수를, 4는 bounding box offset, 1은 objectness score, 80은 COCO 데이터셋의 클래스 수 입니다. 즉, 최종적으로 52x52x255, 26x26x255, 13x13x255 크기의 feature map을 얻을 수 있습니다.
이를 통해 더 높은 level의 feature map으로부터 fine-grained 정보를 얻을 수 있으며, 더 낮은 level의 feature map으로부터 더 유용한 semantic 정보를 얻을 수 있습니다.
Feature Extractor
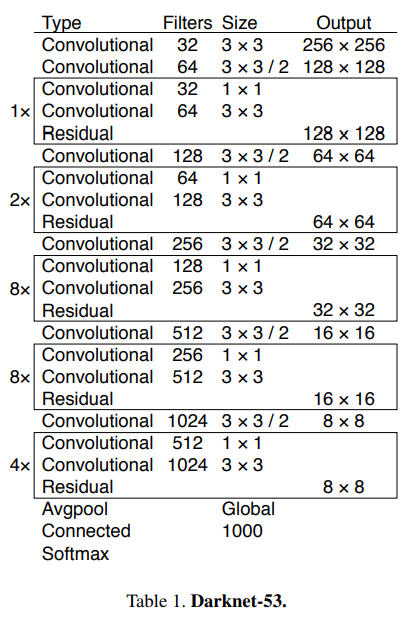
YOLO v3에서는 shortcut connection이 추가되어 53개의 layer를 가지는 Darknet-53을 backbone network로 사용합니다.
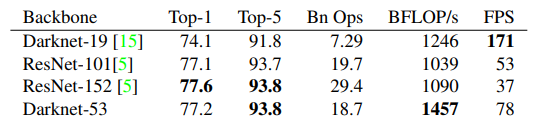
Darknet-53은 Darknet-19보다 더 높은 성능을 내며, ResNet-152와는 비슷한 성능에서 2배 이상의 빠르기를, ResNet-101보다는 높은 성능과 더 빠른속도를 내는 모습을 확인할 수 있습니다.
Conclusion
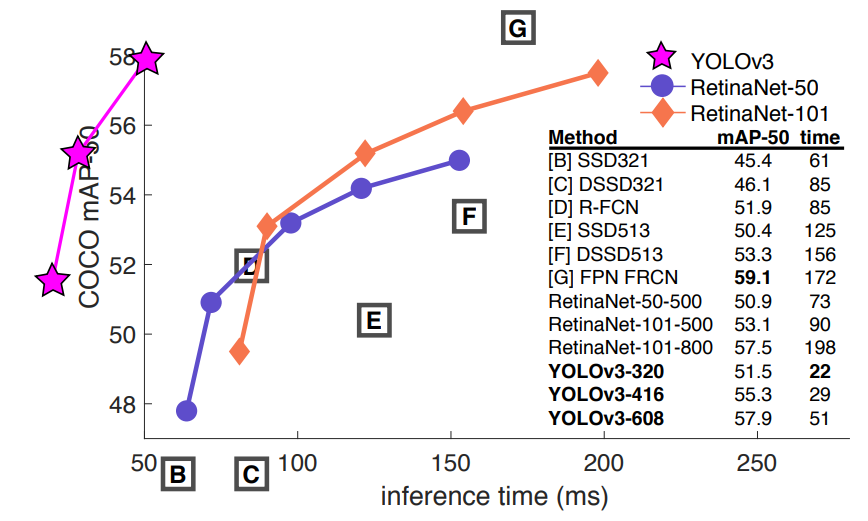
YOLO v3는 RetinaNet에 비해서는 다소 낮은 성능을 보이고, SSD와 성능이 비슷하지만 3배 이상 빠른 속도를 보였습니다. 위의 그래프에서 볼 수 있듯이 inference 속도 면에서 혁신적인 성과를 보였습니다.
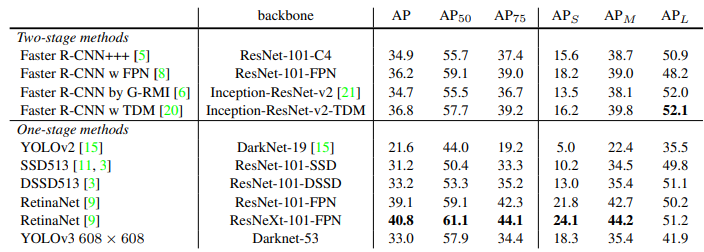
위 표는 다양한 IoU threshold와 다양한 사이즈의 물체에 대한 성능을 비교한 표 입니다.
YOLO v2는 작은 물체에서는 성능이 매우 낮았지만, YOLO v3에서는 많이 개선된 모습을 볼 수 있습니다. 반면, 중간 사이즈와 큰 물체에 대해서는 상대적으로 낮은 성능을 보입니다. 또한, IoU threshold가 50일 때만 성능이 좋고 다른 threshold에서는 성능이 떨어지는 모습을 볼 수 있습니다. 특히 threshold가 올라가면 성능이 크게 떨어지는 모습을 보입니다. 이는 YOLO v3가 완벽하게 Localization을 하는 능력이 떨어진다고 이해할 수 있습니다.
'Paper Review' 카테고리의 다른 글
| [DETR] End-to-End Object Detection with Transformers (0) | 2024.07.29 |
|---|---|
| [YOLO v2] YOLO9000: Better, Faster, Stronger (0) | 2024.07.19 |
| [SSD] Single Shot MultiBox Detector (0) | 2024.07.16 |
| [YOLO v1] You Only Look Once: Unified, Real-Time Object Detection (0) | 2024.07.15 |
| [ViT] Vision Transformer, AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (0) | 2024.07.12 |