
Transformer 기반 시계열 예측 모델의 문제점
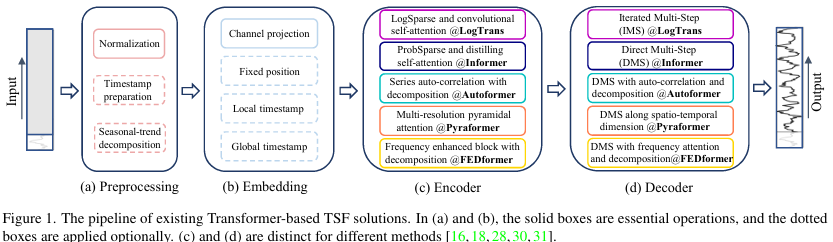
LTSF(Long-term Time Series Forecasting) 분야에서 Transformer 구조를 적용한 모델이 큰 주목을 받으면서 해당 논문 저자들은 다음과 같은 가설들로 "Transformer는 정말 시계열 예측 문제에서 효과적일까?" 하는 근본적인 의문을 가졌습니다. 그리고 여러 실험을 통해 Transformer 기반 모델들의 성능이 다소 과장되었다고 판단했습니다.
1. 순서 정보의 상실
LTSF에서 시간의 순서 정보는 예측에 있어 매우 중요합니다. Transformer는 이 순서 정보를 보존하기 위해 포지셔널 인코딩(Position Encoding) 같은 기법이 있지만, Self-Attention과정에서 순서 불변(permutation-invariant) 특성으로 인해 결국 순서 정보 손실은 불가피합니다. NLP의 경우, 문장 순서가 달라져도 문장의 의미는 대부분 유지 되기 때문에 크게 문제가 되지 않지만, TSF에서는 큰 영향을 미칩니다.
2. 복잡한 모델 구조
Transformer 기반 모델(Informer, Autoformer, FEDformer 등)은 복잡한 구조로 인해 계산량과 메모리 사용량이 많고, 종종 과적합 문제에 직면합니다.
3. 장기 예측 한계
기존 Transformer 기반 시계열 모델들이 실제로는 시계열의 근본적 특징(추세, 주기성)을 제대로 학습하지 못하고, 오히려 잡음(노이즈)에 과적합되어 있습니다. 실제로 Look-back window sizes를 증가시켜도 loss가 감소하지 않는 현상을 관찰할 수 있습니다.
LTSF-Linear
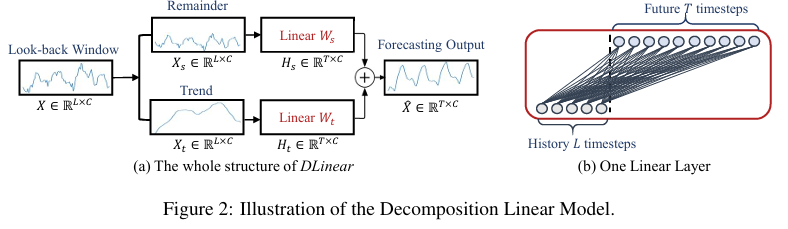
시계열 예측 방법은 다단계(Multi-Step) 예측을 위해 단일 단계 예측기를 학습하고 반복적으로 적용하는 IMS(Iterated Multi-Step) 방법과, 한 번에 다단계 예측을 수행하는 DMS(Diret Multi-Step) 예측 방법이 있습니다.
LSTF-Linear는 가장 간단한 DMS 모델로, 기본적인 구조는 간단한 one-layer linear 구조를 사용하여 시계열에 대한 회귀를 수행 후 미래를 예측합니다.
LSTF-Linear는 시계열을 처리하기 위해 Decomposition, Normalization 전처리 방법을 도입한 DLinear, Nlinear 모델을 제안합니다.
DLinear [Code]
데이터에서 추세(Trend)와 계절성(Seasonality)를 분해(Decomposition)하여 각각 간단한 선형 모델로 예측한 후 합하는 방법. Autoformer와 FEDformer에서 사용된 방법.
[블로그]에서 DLinear 과정을 잘 설명해두었다.
NLinear [Code]
데이터의 마지막 값을 기준으로 간단한 정규화(Normalization)를 진행한 후 예측하는 방법.
실험 결과
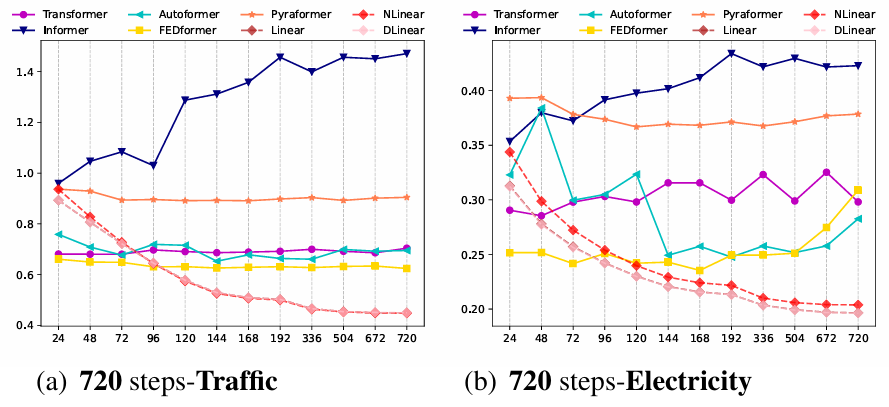
복잡한 Transformer 기반 모델보다 LTSF-Linear가 다양한 데이터셋에서 대부분 좋은 성능을 보였습니다.
주목할 점으로, Transfomer 기반 모델들은 입력 구간(look back window) 또는 예측 구간이 길어질수록 성능이 급격히 나빠지거나 불안정해지지만, LTSF-Linear 모델은 비교적 안정적인 성능을 유지합니다.
'Paper Review' 카테고리의 다른 글
| [DiPE-Linear] Disentangled Interpretable Representation for Efficient Long-term Time Series Forecasting (0) | 2025.03.24 |
|---|---|
| [DETR] End-to-End Object Detection with Transformers (0) | 2024.07.29 |
| [YOLO v3] An Imcremental Improvement (0) | 2024.07.24 |
| [YOLO v2] YOLO9000: Better, Faster, Stronger (0) | 2024.07.19 |
| [SSD] Single Shot MultiBox Detector (0) | 2024.07.16 |
Transformer 기반 시계열 예측 모델의 문제점
LTSF(Long-term Time Series Forecasting) 분야에서 Transformer 구조를 적용한 모델이 큰 주목을 받으면서 해당 논문 저자들은 다음과 같은 가설들로 "Transformer는 정말 시계열 예측 문제에서 효과적일까?" 하는 근본적인 의문을 가졌습니다. 그리고 여러 실험을 통해 Transformer 기반 모델들의 성능이 다소 과장되었다고 판단했습니다.
1. 순서 정보의 상실
LTSF에서 시간의 순서 정보는 예측에 있어 매우 중요합니다. Transformer는 이 순서 정보를 보존하기 위해 포지셔널 인코딩(Position Encoding) 같은 기법이 있지만, Self-Attention과정에서 순서 불변(permutation-invariant) 특성으로 인해 결국 순서 정보 손실은 불가피합니다. NLP의 경우, 문장 순서가 달라져도 문장의 의미는 대부분 유지 되기 때문에 크게 문제가 되지 않지만, TSF에서는 큰 영향을 미칩니다.
2. 복잡한 모델 구조
Transformer 기반 모델(Informer, Autoformer, FEDformer 등)은 복잡한 구조로 인해 계산량과 메모리 사용량이 많고, 종종 과적합 문제에 직면합니다.
3. 장기 예측 한계
기존 Transformer 기반 시계열 모델들이 실제로는 시계열의 근본적 특징(추세, 주기성)을 제대로 학습하지 못하고, 오히려 잡음(노이즈)에 과적합되어 있습니다. 실제로 Look-back window sizes를 증가시켜도 loss가 감소하지 않는 현상을 관찰할 수 있습니다.
LTSF-Linear
시계열 예측 방법은 다단계(Multi-Step) 예측을 위해 단일 단계 예측기를 학습하고 반복적으로 적용하는 IMS(Iterated Multi-Step) 방법과, 한 번에 다단계 예측을 수행하는 DMS(Diret Multi-Step) 예측 방법이 있습니다.
LSTF-Linear는 가장 간단한 DMS 모델로, 기본적인 구조는 간단한 one-layer linear 구조를 사용하여 시계열에 대한 회귀를 수행 후 미래를 예측합니다.
LSTF-Linear는 시계열을 처리하기 위해 Decomposition, Normalization 전처리 방법을 도입한 DLinear, Nlinear 모델을 제안합니다.
DLinear [Code]
데이터에서 추세(Trend)와 계절성(Seasonality)를 분해(Decomposition)하여 각각 간단한 선형 모델로 예측한 후 합하는 방법. Autoformer와 FEDformer에서 사용된 방법.
[블로그]에서 DLinear 과정을 잘 설명해두었다.
NLinear [Code]
데이터의 마지막 값을 기준으로 간단한 정규화(Normalization)를 진행한 후 예측하는 방법.
실험 결과
복잡한 Transformer 기반 모델보다 LTSF-Linear가 다양한 데이터셋에서 대부분 좋은 성능을 보였습니다.
주목할 점으로, Transfomer 기반 모델들은 입력 구간(look back window) 또는 예측 구간이 길어질수록 성능이 급격히 나빠지거나 불안정해지지만, LTSF-Linear 모델은 비교적 안정적인 성능을 유지합니다.
'Paper Review' 카테고리의 다른 글
| [DiPE-Linear] Disentangled Interpretable Representation for Efficient Long-term Time Series Forecasting (0) | 2025.03.24 |
|---|---|
| [DETR] End-to-End Object Detection with Transformers (0) | 2024.07.29 |
| [YOLO v3] An Imcremental Improvement (0) | 2024.07.24 |
| [YOLO v2] YOLO9000: Better, Faster, Stronger (0) | 2024.07.19 |
| [SSD] Single Shot MultiBox Detector (0) | 2024.07.16 |