
잘못된 부분이 있다면 언제든지 알려주시면 감사하겠습니다 !
NOTION 정리
[AlexNet] ImageNet Classification with Deep Convolutional Nerual Networks
AlexNet은 ILSVRC의 2012년 대회에서 Top 5 test error 15.4%를 기록하여 1위를 차지한 네트워크이다.
repeated-canvas-49b.notion.site
AlexNet
ImageNet Classification with Deep Convolutional Nerual Networks
AlexNet은 ILSVRC의 2012년 대회에서 Top 5 test error 15.4%를 기록하여 1위를 차지한 네트워크이다.
Abstract
- AlexNet은 60 million 파라미터와 650,000개의 뉴런으로 구성되어 있고, 구성으로 5개의 CNN 레이어와 3개의 Fully connected 레이어로 되어 있음.
- 빠른 학습을 위해 activation function으로 ReLU를 적용하였음.
- Overfitting을 방지 하기 위해 Fully connected Layer에 Dropout 기법을 적용하였음
Introduction
- AlexNet은 성능을 높이기 위해 큰 Dataset인 ImageNet을 사용하였다.
- Convolutional neural networks(CNNs)은 넓이나 깊이를 통해 모델의 크기를 조절할 수 있고,
- 이미지의 특성(이미지를 구성하는 특징들은 이미지 전체가 아닌 일부 지역에 근접한 픽셀들로만 구성되고, 근접한 픽셀들끼리만의 특성을 가지는 특징) 이라는 이미지의 특성을 잘 살릴 수 있다. 또한, Feed-Forward 신경망에 비해 CNN은 연결과 매개변수가 훨씬 적어서 훈련하기가 더욱 쉽지만, 이론적으로 성능은 약간 떨어질 수 있다.
- GPU는 매우 큰 CNN의 훈련을 용이하게 할 수 있어 2D Convolution에 최적화 되어 있다.
- AlexNet은 성능을 향상시키고 훈련 시간을 단축하는 많은 새롭고 특이한 기능을 설명한다.
- AlexNet은 심각한 과적합 문제를 만들어 이를 방지하기 위한 몇 가지 효과적인 기술을 설명한다.
- 최종 네트워크에는 5개의 Convolutional Layer와 3개의 Fully connected Layer가 포함되어 있으며, 이 depth들은 매우 중요한 것으로 보인다
The Dataset
- ImageNet은 15만장의 Label된 고해상도 이미지와 2만2천개의 카테고리로 구성된 거대한 데이터 셋입니다.
- ILSVRC 대회는 ImageNet 데이터에서 각 카테고리당 약 천장의 이미지를 갖는 천개의 label에 대해서 Classification을 하는 task에 대해 경쟁하는 대회입니다.
- ImageNet에서는 각 class에 대한 confidence score를 sort 했을 때 가장 높은 score를 가진 1개의 class가 정답이 아닌 경우의 비율(top-1)과 상위 score에 대한 5개의 class들 중 정답이 아닌 경우의 비율(top-5)를 이용해 구분합니다.
- ImageNet은 다양한 resolution을 갖는 이미지들이 있지만, AlexNet에서는 256*256 으로 down sampling을 진행하여 이미지를 사용했습니다.
- 직사각형 형태의 이미지는 짧은 쪽에 대해 256으로 맞추고 중앙을 기준으로 crop 하여 256*256으로 변환
- 픽셀 값에 대해 평균값을 픽셀에 대해 빼주는 연산을 제외하고 다른 preprocessing을 하지 않았음
The Architecture

CONV1 → MAX POOL1 → NORM1 → CONV2 → MAX POOL2 → NORM2 → CONV3 → CONV4 → CONV5 → MAX POOL3 → FC6 → FC7 → FC8
- 위 아래로 filter들이 절반씩 나눠서 2개의 GPU로 병렬연산을 수행할 수 있다.
- 5개의 Convolutional Layer와 3개의 Fully connected Layer로 총 8개의 Layer를 포함합니다.
- 기본적으로 Conv → Pool → Normalization 구조가 두번 반복되며, 마지막에는 3개의 Fully connected로 구성
컨볼루션 5개와 와전연결계층 3개로 구성된다. 8개 층에 290400-186624-64896-64896-43264-4096-4096-1000개의 뉴런이 배치되어 있어, 당시에는 놀라울 정도로 복잡한 신경망이었다. 입력은 244*244 크기의 RGB 3채널 영상(3*244*244) 텐서이다. 첫 번째 컨볼루션층은 96개의 3*11*11 마스크를 적용한다. 따라서 (3*244*244 + 1) = 34,944개의 매개변수가 있다. 1~5번째 층까지의 매개변수는 총 2백만개이고, 6~8번째 층까지의 매개변수는 6500만개로 완전연결층의 매개변수가 30배 정도 많다. 앞으로 CNN은 이 완전연결층의 매개변수 수를 줄이는 방향으로 발전한다.
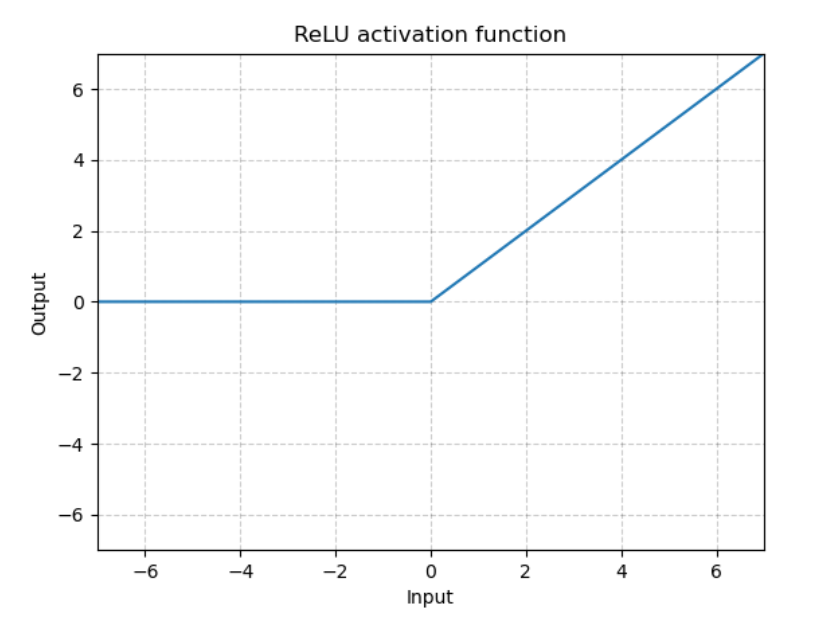
ReLU
AlexNet에서는 Activation function을 ReLU를 적용하였다.
그 이유는, 기존의 tanh, sigmoid의 경우 고질적으로 Gradient vanishing의 문제가 있기 때문이다.
이러한 문제를 ReLU를 사용함으로써 해결하고, 학습 속도도 훨씬 빠르다는 장점을 가진다.
ReLU는 sigmoid나 tanh와 달리 수렴하지 않는다. 즉, x>0일 때, 기울기가 0에 가까워지는 일이 없다는 뜻이다. 또한, 충분한 기울기의 전달이 가능하기 때문에 더 빠르게 수렴한다.
0보다 작은 값을 무시하는 이유는 무의미한 연결을 끊어 모델의 sparse한 연결을 위하는 것 때문이다.
Training on Multiple GPUs
GPU를 2개 사용하였다. 각각의 GPU는 특정 분야에 특화 되어 있다.
예를 들어 첫 번째 GPU는 color-agnostic적인 면을 처리할 수 있고, 두 번째 GPU는 color-spectific한 면을 처리할 수도 있다.
Local Response Normalization (LRN)
LRN은 generalization(일반화)을 목적으로 한다. [참조]

ReLU는 non-saturating nonlinearity 함수(어떤 입력 x가 무한대로 갈때 함수의 값이 무한대로 가는 것) 이기 때문에 saturation을 예방하기 위한 입력 normalization이 필요하지 않는다.
ReLU는 \(max(a,0)\)과 같은 형태인데, 양수 방향의 값은 그대로 사용하기 때문에 특정 activation map의 한 pixel 값이 엄청나게 크다면 주변의 pixel도 영향을 받게 된다.
이러한 문제를 해결하기 위해 activation map의 같은 위치에 있는 pixel끼리 normalization 하는 방식인 LRN을 사용한다.
이 논문에서는 LRN을 측면 억제(later inhibition)의 형태로 구현된다고 나와 있다. 측면 억제는 강한 자극이 주변의 약한 자극을 전달하는 것을 막는 효과를 말한다.
\(\rightarrow\) AlexNet 이후 현대의 CNN에서는 이러한 방법 대신 Batch Normalization을 주로 사용한다.
Overlapping Pooling
일반적인 Pooling Layer에서는 겹치지 않게 구성되는 반면, AlexNet의 Pooling Layer에서 stride보다 더 큰 Filter를 사용하여 겹치게 구성한다.

Reducing Overfitting
Data Augmentation
Image data에서 Overfitting을 줄이는 가장 쉽고 일반적인 방법은 dataset을 인위적으로 늘려주는 것이다.
이 논문에서는
- 256*256의 원본 이미지에서 224*224의 patch가 되도록 무작위로 추출하고 그것을 좌우반전한 patch를 추출한다.
- ImageNet training set 이미지의 RGB pixel 값에 대하여 PCA 수행 (기존 이미지에다가 고유값*평균 0, 표준편차 0.1 크기 가지는 임의의 변수를 더한다.) \(\rightarrow\)이미지의 밝기나 특정 색의 강도가 인식에 미치는 영향을 제거합니다.
하는 방법을 이용하여 Data Augmentation을 시행하며 이 방법들은 적은 연산으로 구현이 가능하여 disk에 저장될 필요 없이 이전 image batch가 gpu에서 train되는 동안, cpu에서 그 다음 image batch의 Augmentation이 진행된다.
Dropout
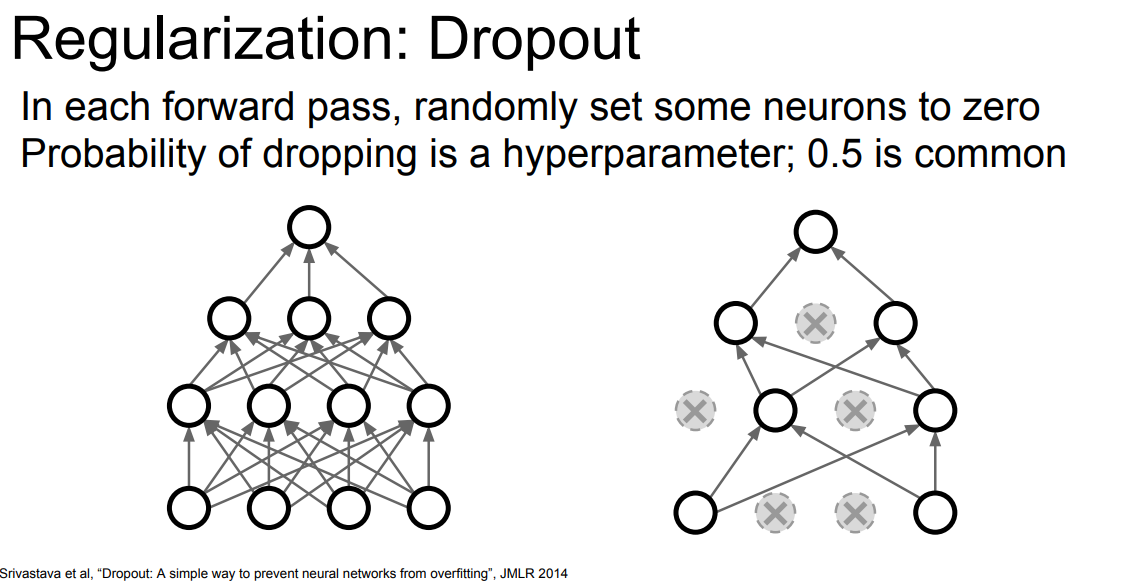
hidden Layer의 일부 Neuron Output 값을 p(0.5)의 확률로 0으로 변경하는 것입니다.
Dropout으로 인해 0으로 변경된 Neuron은 순전파 및 역전파에서 사용되지 않습니다.
일부 Neuron을 강제로 0으로 변경하면서 Neuron 간의 복잡한 상호 의존을 감소합니다.
dropout은 훈련시에 적용되고 테스트시에는 모든 뉴런을 사용합니다.
참조 사이트
AlexNet
☞ 문서의 내용은 가장 하단 참고문헌 및 사이트를 참고하여 필자가 보기 쉽도록 정리한 내용입니다. ☞ 틀린 내용 및 저작권 관련 문의가 있는 경우 문의하시면 수정 및 삭제 조치하겠습
ctkim.tistory.com
https://seobway.tistory.com/entry/alexnet
[논문리뷰] Alexnet, ImageNet Classification with Deep ConvolutionalNeural Networks
개인적으로 읽고 쓰는 공부용 리뷰입니다. 틀린 점이 있을 수도 있으니 감안하고 읽어주세요. 피드백은 댓글로 부탁드립니다. paper overview http://www.cs.toronto.edu/~hinton/absps/imagenet.pdf Alex Krizhe..
seobway.tistory.com
[논문리뷰][AlexNet] ImageNet Classification with Deep Convolutional Neural Networks
이 글은 'AlexNet', 'ImageNet Classification with Deep Convolutional Neural Networks' 논문리뷰 입니다. 저도 아직 공부하는 학생이라 부족한 부분이 많을수 있다는 점 유의하여 읽어주시면 감사하겠습..
zl-zon.tistory.com
LRN(Local Response Normalization) 이란 무엇인가?(feat. AlexNet)
LRN(Local Response Normalization) LRN(Local Response Normalization)은 현재는 많이 사용되지 않습니다. 그러나 Image Net에서 최초의 CNN우승 모델인 AlexNet에서 사용했으며 작동방식에 대해 알아보도록 하겠..
taeguu.tistory.com
'Paper Review' 카테고리의 다른 글
| [FCN] Fully Convolutional Networks for Semantic Segmentation (0) | 2023.03.31 |
|---|---|
| [Transformer] Attention Is All You Need (2) (0) | 2023.03.24 |
| [Transformer] Attention Is All You Need (1) (0) | 2023.03.23 |
| [R-CNN] Rich feature hierarchies for accurate object detection and semantic segmentation 정리 (2) | 2023.03.16 |
| [ResNet] Deep Residual Learning for Image Recongnition (0) | 2022.08.03 |
잘못된 부분이 있다면 언제든지 알려주시면 감사하겠습니다 !
NOTION 정리
[AlexNet] ImageNet Classification with Deep Convolutional Nerual Networks
AlexNet은 ILSVRC의 2012년 대회에서 Top 5 test error 15.4%를 기록하여 1위를 차지한 네트워크이다.
repeated-canvas-49b.notion.site
AlexNet
ImageNet Classification with Deep Convolutional Nerual Networks
AlexNet은 ILSVRC의 2012년 대회에서 Top 5 test error 15.4%를 기록하여 1위를 차지한 네트워크이다.
Abstract
- AlexNet은 60 million 파라미터와 650,000개의 뉴런으로 구성되어 있고, 구성으로 5개의 CNN 레이어와 3개의 Fully connected 레이어로 되어 있음.
- 빠른 학습을 위해 activation function으로 ReLU를 적용하였음.
- Overfitting을 방지 하기 위해 Fully connected Layer에 Dropout 기법을 적용하였음
Introduction
- AlexNet은 성능을 높이기 위해 큰 Dataset인 ImageNet을 사용하였다.
- Convolutional neural networks(CNNs)은 넓이나 깊이를 통해 모델의 크기를 조절할 수 있고,
- 이미지의 특성(이미지를 구성하는 특징들은 이미지 전체가 아닌 일부 지역에 근접한 픽셀들로만 구성되고, 근접한 픽셀들끼리만의 특성을 가지는 특징) 이라는 이미지의 특성을 잘 살릴 수 있다. 또한, Feed-Forward 신경망에 비해 CNN은 연결과 매개변수가 훨씬 적어서 훈련하기가 더욱 쉽지만, 이론적으로 성능은 약간 떨어질 수 있다.
- GPU는 매우 큰 CNN의 훈련을 용이하게 할 수 있어 2D Convolution에 최적화 되어 있다.
- AlexNet은 성능을 향상시키고 훈련 시간을 단축하는 많은 새롭고 특이한 기능을 설명한다.
- AlexNet은 심각한 과적합 문제를 만들어 이를 방지하기 위한 몇 가지 효과적인 기술을 설명한다.
- 최종 네트워크에는 5개의 Convolutional Layer와 3개의 Fully connected Layer가 포함되어 있으며, 이 depth들은 매우 중요한 것으로 보인다
The Dataset
- ImageNet은 15만장의 Label된 고해상도 이미지와 2만2천개의 카테고리로 구성된 거대한 데이터 셋입니다.
- ILSVRC 대회는 ImageNet 데이터에서 각 카테고리당 약 천장의 이미지를 갖는 천개의 label에 대해서 Classification을 하는 task에 대해 경쟁하는 대회입니다.
- ImageNet에서는 각 class에 대한 confidence score를 sort 했을 때 가장 높은 score를 가진 1개의 class가 정답이 아닌 경우의 비율(top-1)과 상위 score에 대한 5개의 class들 중 정답이 아닌 경우의 비율(top-5)를 이용해 구분합니다.
- ImageNet은 다양한 resolution을 갖는 이미지들이 있지만, AlexNet에서는 256*256 으로 down sampling을 진행하여 이미지를 사용했습니다.
- 직사각형 형태의 이미지는 짧은 쪽에 대해 256으로 맞추고 중앙을 기준으로 crop 하여 256*256으로 변환
- 픽셀 값에 대해 평균값을 픽셀에 대해 빼주는 연산을 제외하고 다른 preprocessing을 하지 않았음
The Architecture
CONV1 → MAX POOL1 → NORM1 → CONV2 → MAX POOL2 → NORM2 → CONV3 → CONV4 → CONV5 → MAX POOL3 → FC6 → FC7 → FC8
- 위 아래로 filter들이 절반씩 나눠서 2개의 GPU로 병렬연산을 수행할 수 있다.
- 5개의 Convolutional Layer와 3개의 Fully connected Layer로 총 8개의 Layer를 포함합니다.
- 기본적으로 Conv → Pool → Normalization 구조가 두번 반복되며, 마지막에는 3개의 Fully connected로 구성
컨볼루션 5개와 와전연결계층 3개로 구성된다. 8개 층에 290400-186624-64896-64896-43264-4096-4096-1000개의 뉴런이 배치되어 있어, 당시에는 놀라울 정도로 복잡한 신경망이었다. 입력은 244*244 크기의 RGB 3채널 영상(3*244*244) 텐서이다. 첫 번째 컨볼루션층은 96개의 3*11*11 마스크를 적용한다. 따라서 (3*244*244 + 1) = 34,944개의 매개변수가 있다. 1~5번째 층까지의 매개변수는 총 2백만개이고, 6~8번째 층까지의 매개변수는 6500만개로 완전연결층의 매개변수가 30배 정도 많다. 앞으로 CNN은 이 완전연결층의 매개변수 수를 줄이는 방향으로 발전한다.
ReLU
AlexNet에서는 Activation function을 ReLU를 적용하였다.
그 이유는, 기존의 tanh, sigmoid의 경우 고질적으로 Gradient vanishing의 문제가 있기 때문이다.
이러한 문제를 ReLU를 사용함으로써 해결하고, 학습 속도도 훨씬 빠르다는 장점을 가진다.
ReLU는 sigmoid나 tanh와 달리 수렴하지 않는다. 즉, x>0일 때, 기울기가 0에 가까워지는 일이 없다는 뜻이다. 또한, 충분한 기울기의 전달이 가능하기 때문에 더 빠르게 수렴한다.
0보다 작은 값을 무시하는 이유는 무의미한 연결을 끊어 모델의 sparse한 연결을 위하는 것 때문이다.
Training on Multiple GPUs
GPU를 2개 사용하였다. 각각의 GPU는 특정 분야에 특화 되어 있다.
예를 들어 첫 번째 GPU는 color-agnostic적인 면을 처리할 수 있고, 두 번째 GPU는 color-spectific한 면을 처리할 수도 있다.
Local Response Normalization (LRN)
LRN은 generalization(일반화)을 목적으로 한다. [참조]
ReLU는 non-saturating nonlinearity 함수(어떤 입력 x가 무한대로 갈때 함수의 값이 무한대로 가는 것) 이기 때문에 saturation을 예방하기 위한 입력 normalization이 필요하지 않는다.
ReLU는 \(max(a,0)\)과 같은 형태인데, 양수 방향의 값은 그대로 사용하기 때문에 특정 activation map의 한 pixel 값이 엄청나게 크다면 주변의 pixel도 영향을 받게 된다.
이러한 문제를 해결하기 위해 activation map의 같은 위치에 있는 pixel끼리 normalization 하는 방식인 LRN을 사용한다.
이 논문에서는 LRN을 측면 억제(later inhibition)의 형태로 구현된다고 나와 있다. 측면 억제는 강한 자극이 주변의 약한 자극을 전달하는 것을 막는 효과를 말한다.
\(\rightarrow\) AlexNet 이후 현대의 CNN에서는 이러한 방법 대신 Batch Normalization을 주로 사용한다.
Overlapping Pooling
일반적인 Pooling Layer에서는 겹치지 않게 구성되는 반면, AlexNet의 Pooling Layer에서 stride보다 더 큰 Filter를 사용하여 겹치게 구성한다.
Reducing Overfitting
Data Augmentation
Image data에서 Overfitting을 줄이는 가장 쉽고 일반적인 방법은 dataset을 인위적으로 늘려주는 것이다.
이 논문에서는
- 256*256의 원본 이미지에서 224*224의 patch가 되도록 무작위로 추출하고 그것을 좌우반전한 patch를 추출한다.
- ImageNet training set 이미지의 RGB pixel 값에 대하여 PCA 수행 (기존 이미지에다가 고유값*평균 0, 표준편차 0.1 크기 가지는 임의의 변수를 더한다.) \(\rightarrow\)이미지의 밝기나 특정 색의 강도가 인식에 미치는 영향을 제거합니다.
하는 방법을 이용하여 Data Augmentation을 시행하며 이 방법들은 적은 연산으로 구현이 가능하여 disk에 저장될 필요 없이 이전 image batch가 gpu에서 train되는 동안, cpu에서 그 다음 image batch의 Augmentation이 진행된다.
Dropout
hidden Layer의 일부 Neuron Output 값을 p(0.5)의 확률로 0으로 변경하는 것입니다.
Dropout으로 인해 0으로 변경된 Neuron은 순전파 및 역전파에서 사용되지 않습니다.
일부 Neuron을 강제로 0으로 변경하면서 Neuron 간의 복잡한 상호 의존을 감소합니다.
dropout은 훈련시에 적용되고 테스트시에는 모든 뉴런을 사용합니다.
참조 사이트
AlexNet
☞ 문서의 내용은 가장 하단 참고문헌 및 사이트를 참고하여 필자가 보기 쉽도록 정리한 내용입니다. ☞ 틀린 내용 및 저작권 관련 문의가 있는 경우 문의하시면 수정 및 삭제 조치하겠습
ctkim.tistory.com
https://seobway.tistory.com/entry/alexnet
[논문리뷰] Alexnet, ImageNet Classification with Deep ConvolutionalNeural Networks
개인적으로 읽고 쓰는 공부용 리뷰입니다. 틀린 점이 있을 수도 있으니 감안하고 읽어주세요. 피드백은 댓글로 부탁드립니다. paper overview http://www.cs.toronto.edu/~hinton/absps/imagenet.pdf Alex Krizhe..
seobway.tistory.com
[논문리뷰][AlexNet] ImageNet Classification with Deep Convolutional Neural Networks
이 글은 'AlexNet', 'ImageNet Classification with Deep Convolutional Neural Networks' 논문리뷰 입니다. 저도 아직 공부하는 학생이라 부족한 부분이 많을수 있다는 점 유의하여 읽어주시면 감사하겠습..
zl-zon.tistory.com
LRN(Local Response Normalization) 이란 무엇인가?(feat. AlexNet)
LRN(Local Response Normalization) LRN(Local Response Normalization)은 현재는 많이 사용되지 않습니다. 그러나 Image Net에서 최초의 CNN우승 모델인 AlexNet에서 사용했으며 작동방식에 대해 알아보도록 하겠..
taeguu.tistory.com
'Paper Review' 카테고리의 다른 글
| [FCN] Fully Convolutional Networks for Semantic Segmentation (0) | 2023.03.31 |
|---|---|
| [Transformer] Attention Is All You Need (2) (0) | 2023.03.24 |
| [Transformer] Attention Is All You Need (1) (0) | 2023.03.23 |
| [R-CNN] Rich feature hierarchies for accurate object detection and semantic segmentation 정리 (2) | 2023.03.16 |
| [ResNet] Deep Residual Learning for Image Recongnition (0) | 2022.08.03 |