
Attention Is All You Need
해당 글과 그림의 출처는 lllustrated Transformer과 lllustrated Transformer(번역)을 참고하였습니다.
이 글에서는 Attention을 활용한 모델인 Transformer에 대해 다룹니다.
우선 이 모델의 핵심을 정리한다면, multi-head self-attention을 이용해 sequential computation을 줄여 더 많은 부분을 병렬 처리가 가능하게 만들면서 동시에 더 많은 단어들 간 dependency를 모델링 한다는 것입니다.
A High-Level Look

전체적인 흐름을 먼저 살펴보겠습니다. 기계번역 모델은 특정 언어로 된 문장을 입력 받아 다른 언어로 번역한 문장을 출력합니다. 그 모델을 열어 보면, Encoding과 Decoding 부분 그리고 그 사이를 이어주는 연결들을 볼 수 있습니다.
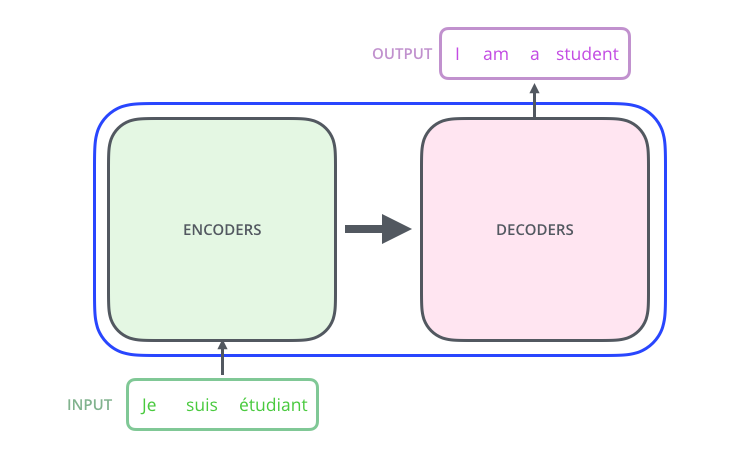
Encoding 부분을 다시 열어 보면, 여러 개의 Encoder를 쌓아 올려 만든 구조입니다. (해당 논문에서는 6개를 쌓았지만, 각자의 환경과 Task에 맞게 얼마든지 변경하여 실험할 수 있습니다.) Decoding 부분은 Ecoding 부분과 동일한 개수만큼의 Decoder를 쌓습니다.
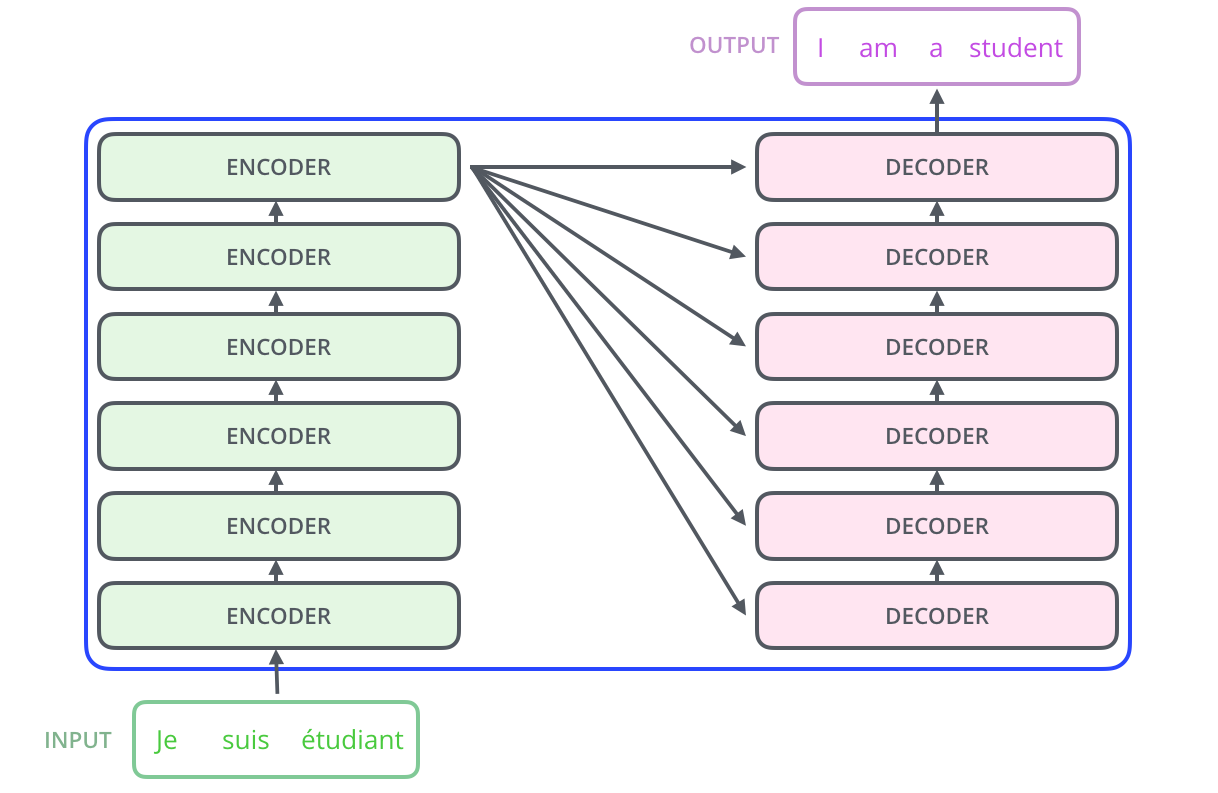
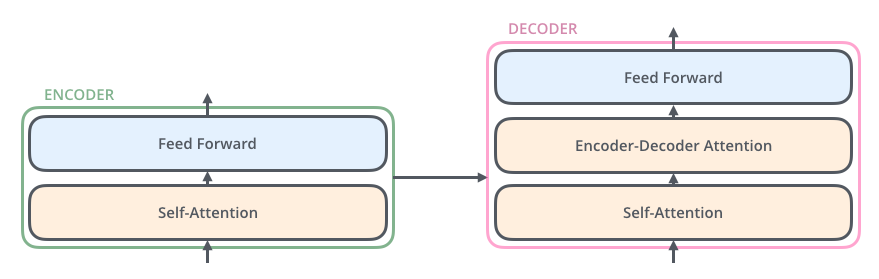
Encoder들은 모두 정확히 똑같은 구조를 가지고 있습니다. (그러나 Encoder간의 weight은 공유하지 않습니다.) 그리고 Encoder 부분을 다시 열어보면, 다음과 같이 두 개의 sub-layer로 구성되어 있습니다.

이 Encoder에 들어온 입력은 가장 먼저 Self-Attention layer를 지나게 됩니다. 이 layer는 Encoder가 하나의 특정한 단어를 encode하기 위해서 입력 내의 모든 단어들과의 관계를 살펴봅니다.
입력이 Self-Attention 층을 통과하여 나온 출력은 다시 Feed-Forward 신경망으로 들어가게 됩니다. 똑같은 Feed-Forward 신경망이 각 위치의 단어마다 독립적으로 적용되어 출력을 만듭니다.
Decoder 또한 Encoder에 있는 두 layer 모두를 가지고 있습니다. 그러나 그 두 층 사이에 seq2seq 모델의 attention과 비슷한 encoder-decoder attention이 포함되어 있습니다. 이것은 Decoder가 입력 문장 중에서 각 타임 스텝에서 가장 관련 있는 부분에 집중할 수 있도록 해줍니다.
여기까지가 Transformer의 큰 구조와 흐름이며, 다음으로 입력으로 들어온 문장이 출력이 될때까지 어떤 벡터 연산이 이루어지는지를 확인하는 목적으로 모델을 살펴봅니다.
벡터(Vector)들을 기준으로 그림 그려보기
먼저 입력 단어들을 embedding 알고리즘을 이요해 벡터로 바꾸는 것 부터 해야 합니다.

각 단어들은 크기 512의 벡터 하나로 embedding 되지만, 우선 위와 같은 간단한 박스로 나타내겠습니다.
이 embedding은 가장 밑단의 Encoder에서만 수행합니다. 이렇게 되면 가장 밑에 있는 Encoder의 경우는 Word embedding이 될 것이고, 다른 Encoder들은 바로 전의 Encoder의 출력을 받습니다.(이 embedding 벡터의 사이즈는 hypterparameter로 마음대로 정할 수 있으며, 대부분 데이터 셋에서 가장 긴 문장의 길이를 둡니다.)
이렇게 입력 문장의 단어들을 embedding 한 후에, 각 단어에 해당하는 벡터들은 Encoder 내의 두 개의 sub-layer로 들어가게 됩니다.
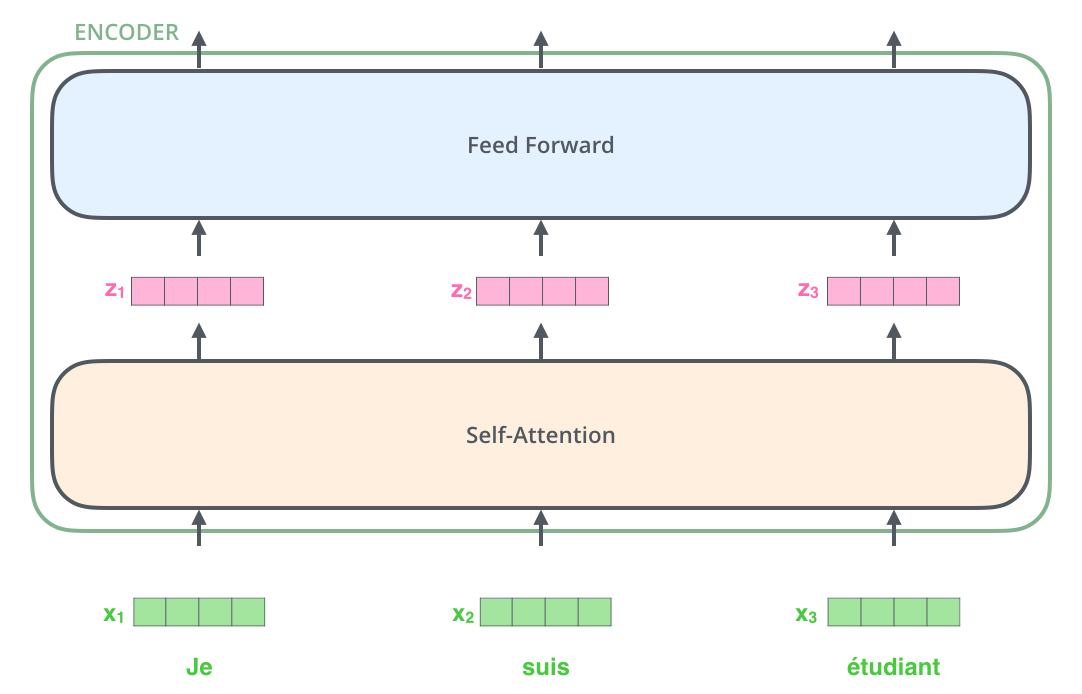
여기서 Transformer의 핵심 특성 중 하나인 각 위치의 단어가 인코더 내에서 자신만의 경로를 통해 흐른다는 것을 볼 수 있습니다. Self-Attention 층에서 이 위치에 따른 경로들 사이에 모두 dependency가 있습니다. 반면에 Feed-Froward 층은 이러한 dependency가 없기 때문에 다양한 경로들은 병렬처리가 될 수 있습니다.
Encoding
Encoder는 입력으로 벡터들의 리스트를 받습니다. 이 벡터의 리스트를 먼저 Self-Attention layer에, 그 다음으로 Feed-Forward 신경망에 통과시키고 그 결과물을 그 다음 Encoder에 전달합니다.
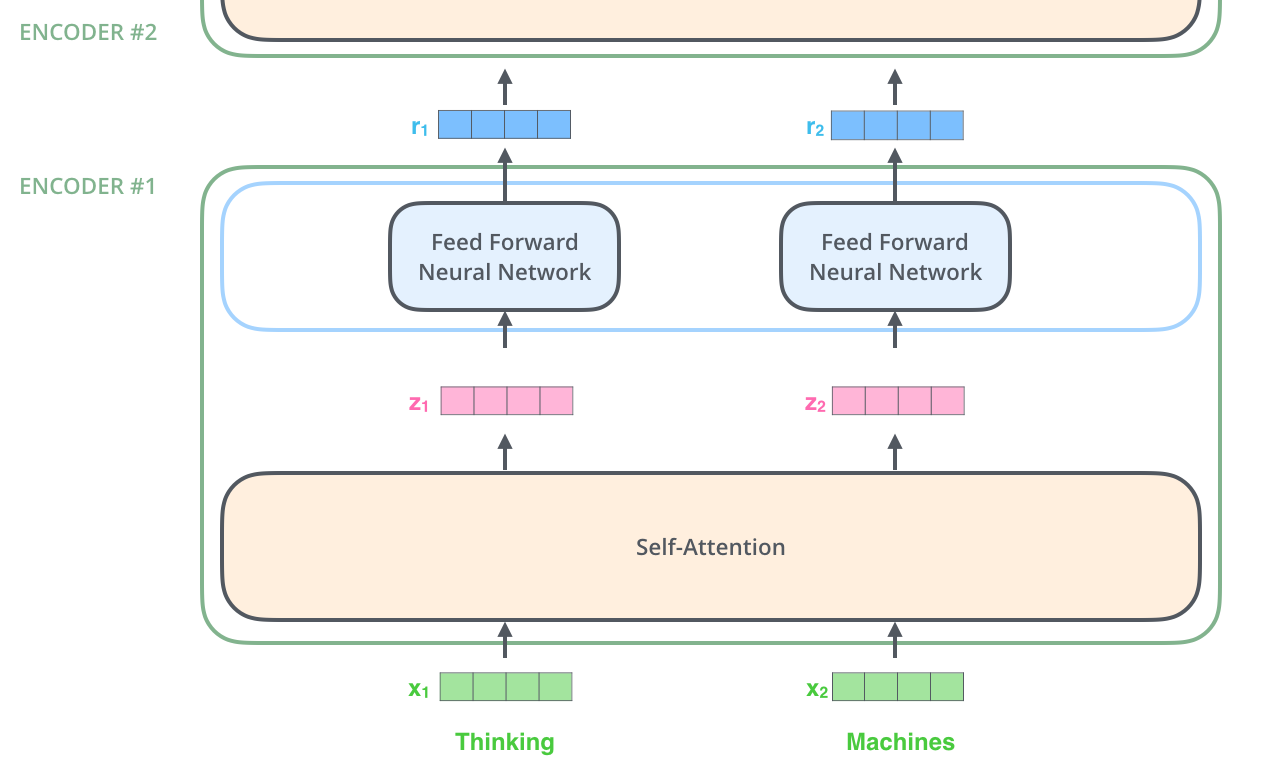
여기서 각 위치의 단어들은 각각 다른 Self-Encoding 과정을 거칩니다. 그 다음으로는 모두 같은 과정인 Feed-Forward 신경망을 거칩니다.
Self-Attention at a High Level
아까부터 계속 반복해서 말해오던 Self-Attention에 대해 설명하도록 하겠습니다.
"The animal didn’t cross the street because it was too tired" 이 문장을 번역하고 싶은 문장이라고 하겠습니다.
이 문장에서 "it" 이 가리키는 것은 무엇일까요? "street" 일까요 ? "animal" 일까요 ?
사람에게는 이것이 매우 간단한 질문이지만, 신경망은 아닙니다.
여기서 Self-Attention을 이용하여 단어를 처리하면, "it"과 "animal"을 연결할 수 있습니다 !
모델이 입력 문장 내의 각 단어(입력 시퀀스의 각 위치)를 처리할 때, Self-Attention은 입력 문장 내의 다른 위치에 있는 단어들을 보고 거기서 힌트를 받아 현재 타겟 위치의 단어를 더 잘 Encoding 할 수 있습니다.
RNN이 hidden state를 유지하고 업데이트함으로써 현재 처리 중인 단어에 어떻게 과거의 단어들에서 나온 맥락을 연관시키는 것 처럼. 이와 동일하게 Transformer에게는 이 Self-Attention이 현재 처리 중인 단어에 다른 연관 있는 단어들의 맥락을 붙여주는

Self-Attention
다음은 여러 가지 벡터들을 통해서 어떻게 Self-Attention을 계산할 수 있는지 살펴보겠습니다. 그 후 행렬을 이용해서 이것이 실제로 어떻게 구현돼 있는지 확인하겠습니다.
Self-Attention 계산의 가장 첫 단계는 Encoder에 입력된 벡터들(이 경우에는 각 단어의 embedding 벡터)에게서 부터 각 3개의 벡터를 만들어내는 일입니다. 이 3개의 벡터는 각 단어에 대한 Query 벡터, Key 벡터, Value 벡터라 합니다. 이 벡터들은 입력 벡터에 대해서 세 개의 학습 가능한 행렬들을 각각 곱함으로써 만들어 집니다.
여기서 한가지 짚고 넘어갈 것은 이 새로운 벡터들이 기존의 벡터들 보다 더 작은 사이즈를 가진다는 것입니다. 기존의 입력 벡터들은 크기가 512인 반면, 이 Q, K, V 벡터들은 각 크기가 64 입니다. 그러나 이 벡터들이 꼭 이렇게 작아야만 하는 것은 아니며, 이것은 그저 Multi-Head Attention의 계산 복잡도를 일정하게 만들고자 내린 구조적인 선택일 뿐입니다.
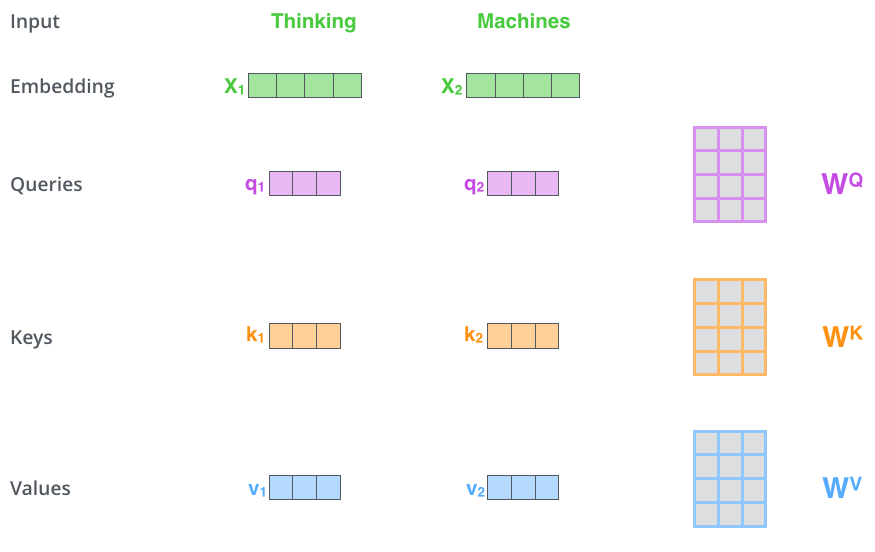
\(X_1\)을 Weight 행렬인 WQ로 곱하는 것은, 현재 단어와 연관된 query 벡터인 \(q_1\)를 생성합니다. 같은 방법으로 입력 문장에 있는 각 단어에 대한 query, key, value 벡터를 만들 수 있습니다.
그렇다면 정확히 이 query, key, value 벡터란 무엇을 의미하는 것일까요 ?
그것은 Attention에 대해서 생각하고 계산하려할 때 도움이 되는 추상적인 개념입니다. 이제 곧 다루게 될 테지만 어떻게 Attention이 실제로 계산되는지를 알면 자연스럽게 이 세 개의 벡터들이 어떤 역할을 하는지 알 수 있게 됩니다.
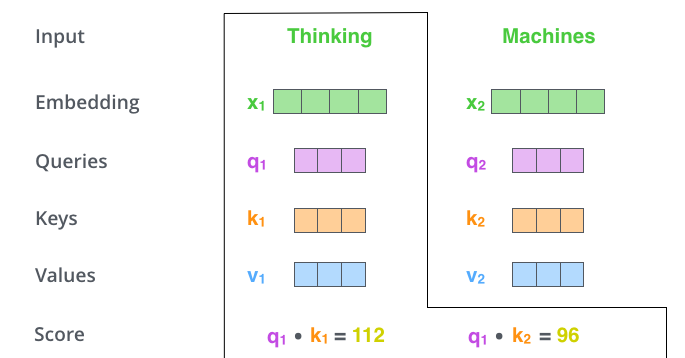
Self-Attention 계산의 두 번째 스텝은 점수를 계산하는 것입니다. 다음 예시의 첫 번째 단어인 "Thinking"에 대해서 Self-Attention을 계산한다고 하겠습니다. 이 "Thinking" 단어와 입력 문장 속의 다른 모든 단어들에 대해서 각각 점수를 계산해야 합니다. 이 점수는 현재 위치의 이 단어를 Encode 할 때 다른 단어들에 대해서 얼마나 집중을 해야 할지를 정합니다.
점수는 현재 단어의 query vector와 점수를 매기려 하는 다른 위치에 있는 단어의 key vector의 내적으로 계산됩니다.
다시 말해, 우리가 #1에 있는 단어에 대해서 Self-Attention을 계산한다 했을 때, 첫 번째 점수는 \(q_1\)과 \(k_1\)의 내적일 것입니다. 그리고 동일하게 두 번째 점수는 \(q_1\)과 \(k_2\)의 내적일 것입니다.
세 번째 단계는 이 점수들을 8로 나누는 것입니다. 이 8이라는 숫자는 key vector의 사이즈인 64의 제곱근(sqrt)라는 식으로 계산이 된 것입니다. 이 나눗셈을 통해 우리는 더 안정적인 gradient를 가지게 됩니다.(Normalize)
네 번째 단계는 8로 나눈 값을 softmax 계산을 통과시켜 모든 점수들을 양수로 만들고 그 합을 1로 만들어 줍니다.
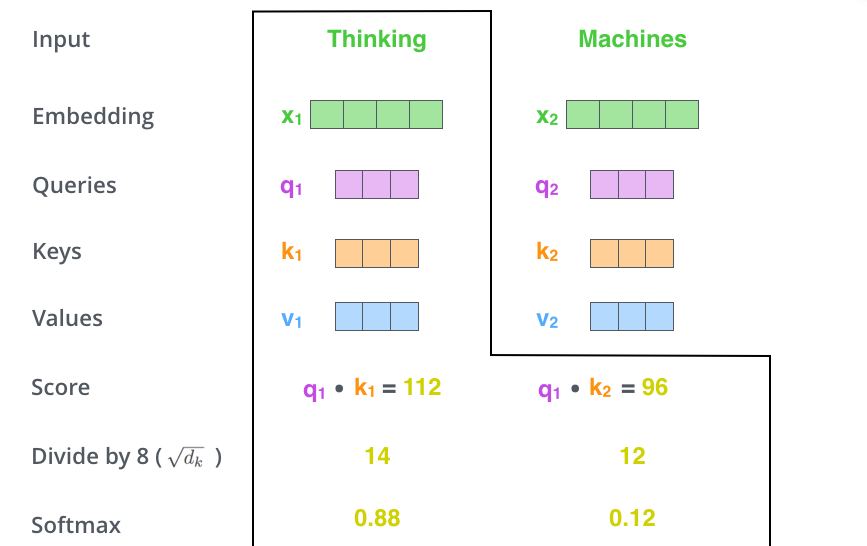
이 softmax 점수는 각 단어가 현재 위치에서 얼마나 표현될지를 결정합니다. 당연하게 현재 위치의 단어가 가장 높은 점수를 가지겠지만, 가끔은 현재 단어에 관련이 있는 다른 단어에 대한 정보가 들어가는 것이 도움이 됩니다.
다섯 번째 단계는 각 vector value들을 softmax 점수와 곱하는 것입니다. 이렇게 하는 이유는, 우리가 집중하길 원하는 단어들의 값은 유지되고, 관련 없는 단어들은 0.0001과 같은 작은 숫자를 곱해 없애버리기 위함입니다.
마지막으로 여섯 번째 단계는 이 점수로 곱해진 weighted value vector(가중치가 적용된 value vector)들을 모두 합하는 것입니다. 이 단계의 출력이 바로 현재 위치에 대한 Self-Attention layer의 출력이 됩니다.
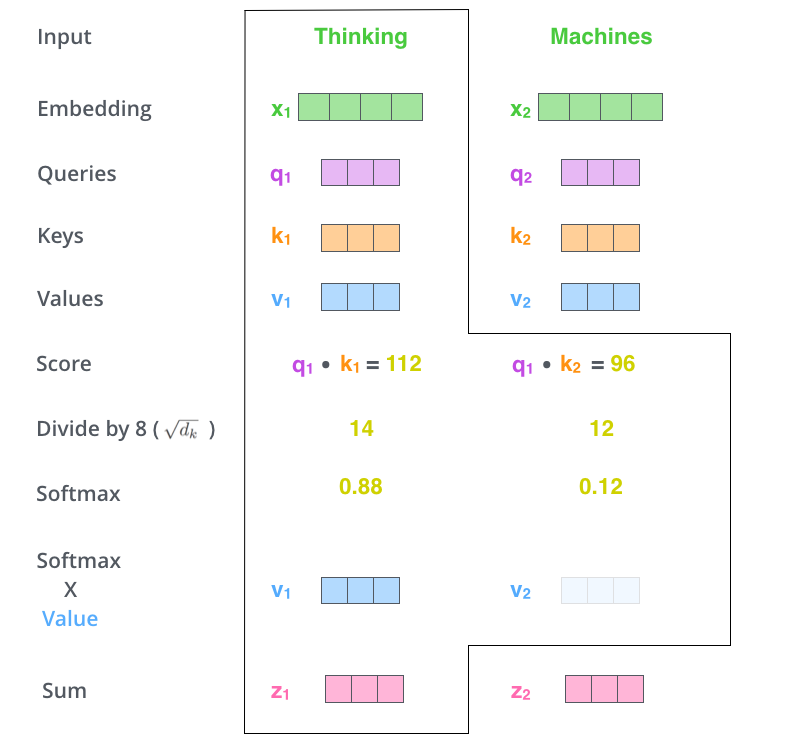
이러한 6단계의 과정들은 실제 구현에서는 빠른 속도를 위해 모든 과정들이 벡터가 아닌 행렬의 형태로 진행됩니다.
Self-Attention의 행렬 계산
가장 먼저 Qeury, Key, Value 행렬들을 계산합니다.
이를 위해 입력 벡터들(embedding 벡터들)을 하나의 행렬 \(X\)로 쌓아 올리고 그것을 학습할 행렬들인 \(WQ\), \(WK\), \(WV\)로 곱합니다.
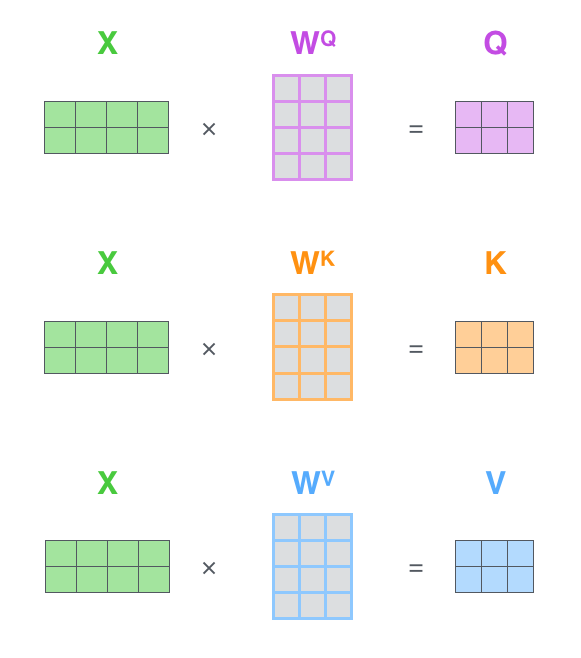
\(X\)의 각 행은 입력 문장의 각 단어의 해당합니다.
여기서 다시 한번 embedding 벡터들 (크기 512, 위 그림에서는 4)과 query/key/value 벡터들(크기 64, 위 그림에서는 3) 간의 크기 차이를 볼 수 있습니다.
마지막으로, 현재 행렬을 이용하고 있으므로 앞서 설명했던 Self-Attention 계산 단계 2부터 6까지를 하나의 식으로 압축이 가능합니다.
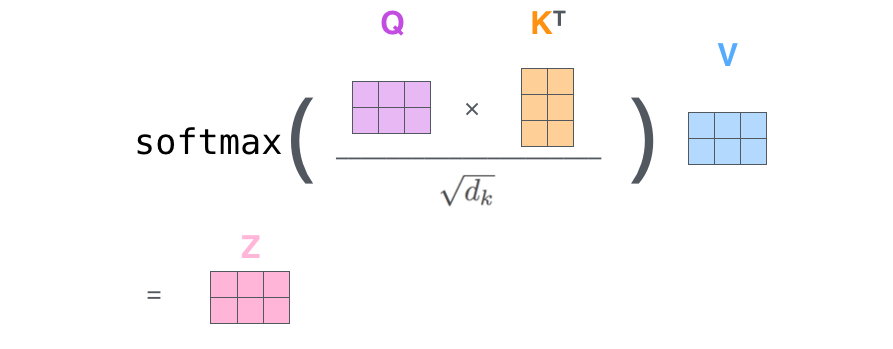
The Beast With Many Heads
본 논문에서는 Self-Attention layer에다 Multi-Headed Attention 이라는 매커니즘을 더해 더욱 이를 개선합니다.
이것은 다음 두 가지 방법으로 Attention layer의 성능을 향상시킵니다.
- 모델이 서로 다른 위치에 집중할 수 있는 능력이 향상됩니다. 예를 들어 위의 예에서 \(z_1\)은 모든 다른 Encoding의 영향을 조금씩 받지만, 사실 이것은 실제 자기 자신에게만 높은 점수를 줘 자신만을 포함해도 됐을 것입니다.
- Attention layer가 여러 개의 "representation 공간"을 가지게 해줍니다. Multi-Headed Attention을 이용함으로써 여러 개의 query/key/value weight 행렬들을 가지게 됩니다.(본 논문에서 제안된 구조는 8개의 Attention Heads를 가지므로 각 Encoder/Decoder 마다 이런 8개의 세트를 가지게 됩니다.) 이 각각의 query/key/value set는 랜덤으로 초기화되어 학습됩니다. 학습이 된 후 각각의 세트는 입력 벡터들에 곱해져 벡터들을 각 목적에 맞게 투영시키게 됩니다. 이러한 세트가 여러개 있다는 것은 각 벡터들을 각각 다른 representation 공간으로 나타낸다는 것을 의미합니다.
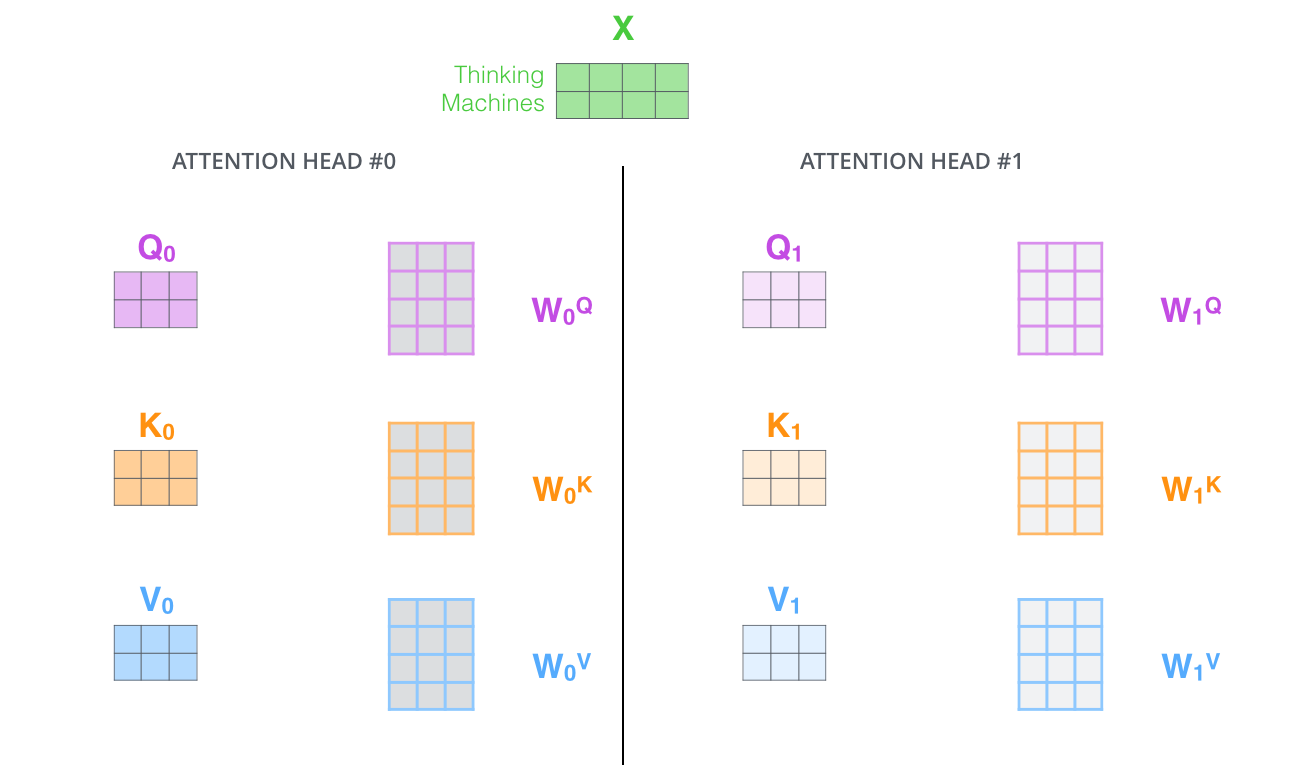
Multi-Headed Attention을 이용하기 위해 각 head 마다 다른 query/key/value weight 행렬들을 모델에 가지게 됩니다.
위에서 설명했던 것처럼 같은 Self-Attention 계산을 8개의 다른 weight 행렬들에 거치게 되면, 8개의 서로 다른 \(Z\)행렬을 가지게 됩니다.
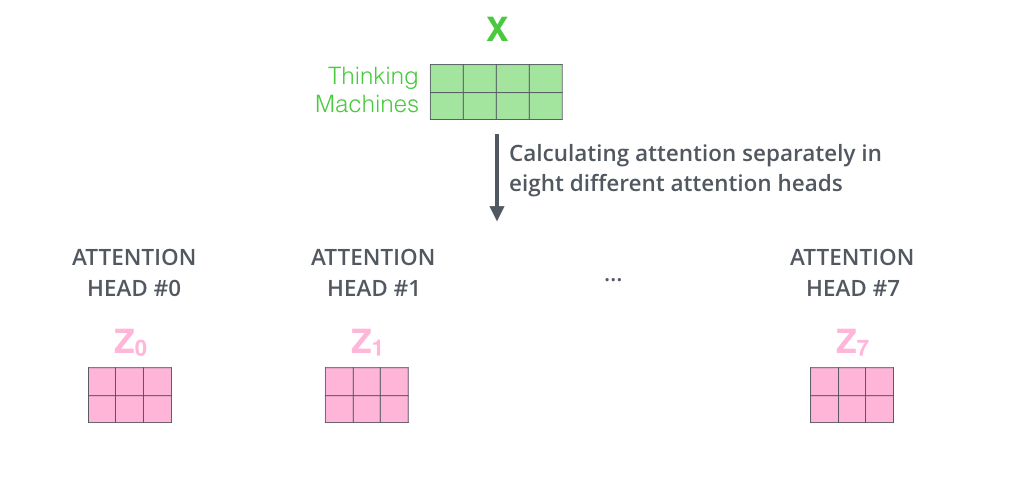
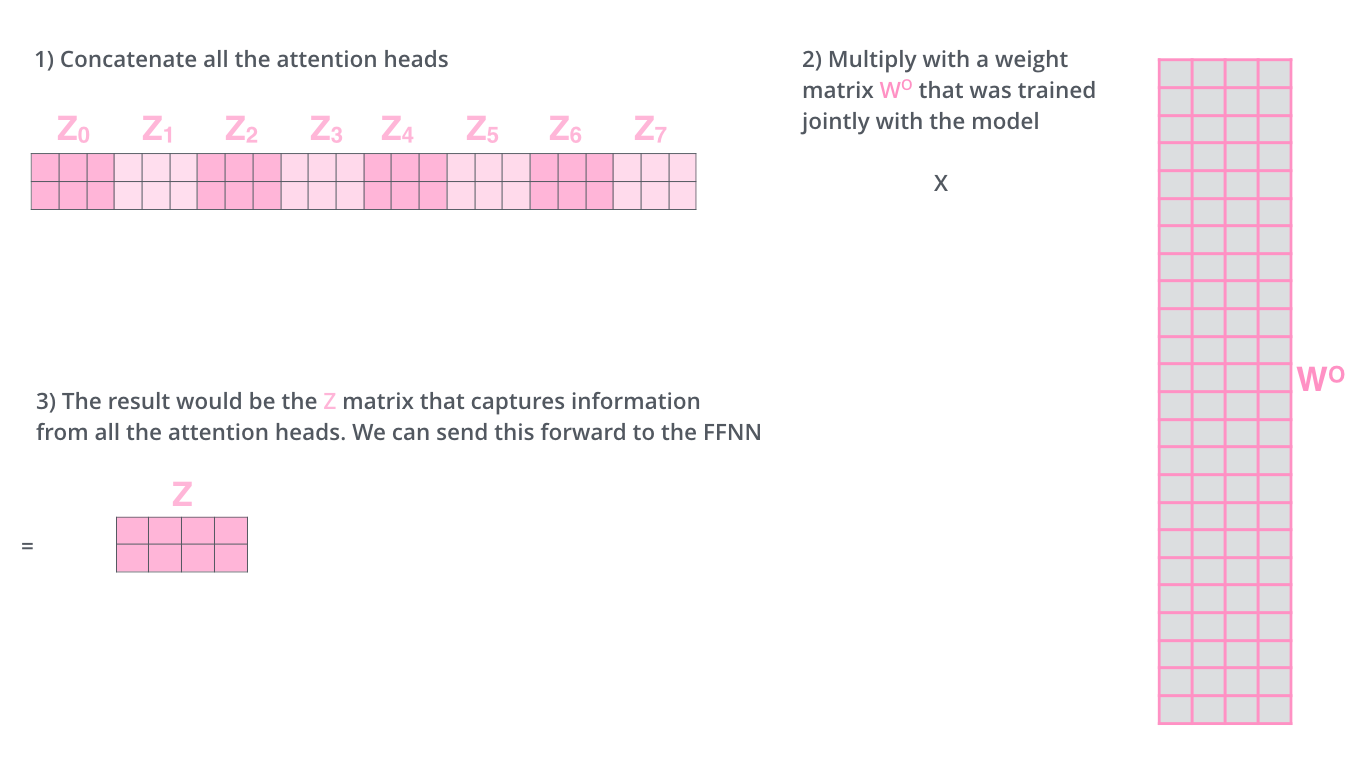
이렇게 8개의 서로 다른 \(Z\) 행렬은 바로 Feed-Forward layer로 보낼 수 없습니다. 왜냐하면, Feed-Forward layer는 한 위치에 대해 오직 한 개의 행렬만을 input으로 받을 수 있기 때문입니다. 그러므로 이 8개의 행렬을 하나의 행렬로 합치는 방법을 사용해야 합니다.
바로 모두 이어 붙여서 하나의 행렬로 만들고, 그 다음 하나의 도 다른 weight 행렬인 \(WO\)를 곱합니다.
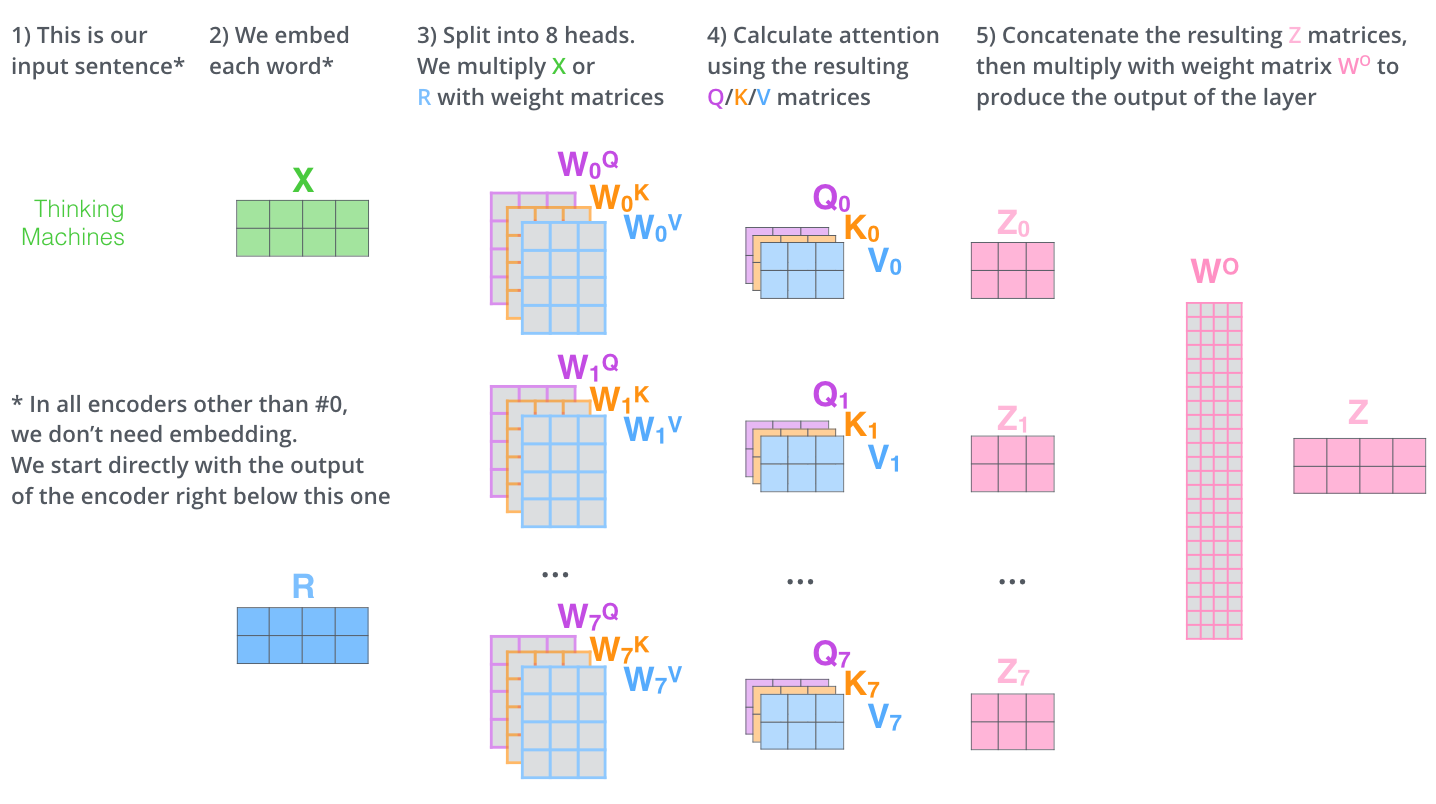
이 과정들이 Multi-Headed Attention입니다. 다음 그림은 이 모든 과정을 하나의 그림으로 표현한 것입니다.
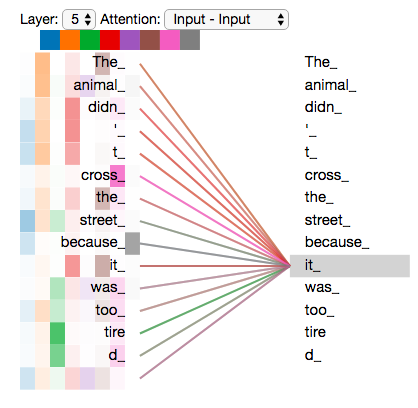
"The animal didn’t cross the street because it was too tired" 이 문장을 Multi-Headed Attention과 함께 보도록 하겠습니다. 그 중에서 특히 "it" 이란 단어를 Encode 할 때 여러 개의 Attention이 각각 어디에 집중하는지를 보겠습니다.

"it"이란 단어를 encode할 때, 주황색의 Attention Head는 "The animal"에 가장 집중하고 있는 반면, 초록색의 Attention Head는 "tired"라는 단어에 집중하고 있습니다. 모델은 이 두 개의 Attention Head를 이용하여 "animal"과 "tired" 두 단어 모두에 대한 representation을 "it"의 representation에 포함시킬 수 있습니다.
그러나 이 모든 Attention Head들을 하나의 그림으로 표현한다면, Attention의 의미는 해석하기 어려워 집니다.
'Paper Review' 카테고리의 다른 글
Attention Is All You Need
해당 글과 그림의 출처는 lllustrated Transformer과 lllustrated Transformer(번역)을 참고하였습니다.
이 글에서는 Attention을 활용한 모델인 Transformer에 대해 다룹니다.
우선 이 모델의 핵심을 정리한다면, multi-head self-attention을 이용해 sequential computation을 줄여 더 많은 부분을 병렬 처리가 가능하게 만들면서 동시에 더 많은 단어들 간 dependency를 모델링 한다는 것입니다.
A High-Level Look
전체적인 흐름을 먼저 살펴보겠습니다. 기계번역 모델은 특정 언어로 된 문장을 입력 받아 다른 언어로 번역한 문장을 출력합니다. 그 모델을 열어 보면, Encoding과 Decoding 부분 그리고 그 사이를 이어주는 연결들을 볼 수 있습니다.
Encoding 부분을 다시 열어 보면, 여러 개의 Encoder를 쌓아 올려 만든 구조입니다. (해당 논문에서는 6개를 쌓았지만, 각자의 환경과 Task에 맞게 얼마든지 변경하여 실험할 수 있습니다.) Decoding 부분은 Ecoding 부분과 동일한 개수만큼의 Decoder를 쌓습니다.
Encoder들은 모두 정확히 똑같은 구조를 가지고 있습니다. (그러나 Encoder간의 weight은 공유하지 않습니다.) 그리고 Encoder 부분을 다시 열어보면, 다음과 같이 두 개의 sub-layer로 구성되어 있습니다.
이 Encoder에 들어온 입력은 가장 먼저 Self-Attention layer를 지나게 됩니다. 이 layer는 Encoder가 하나의 특정한 단어를 encode하기 위해서 입력 내의 모든 단어들과의 관계를 살펴봅니다.
입력이 Self-Attention 층을 통과하여 나온 출력은 다시 Feed-Forward 신경망으로 들어가게 됩니다. 똑같은 Feed-Forward 신경망이 각 위치의 단어마다 독립적으로 적용되어 출력을 만듭니다.
Decoder 또한 Encoder에 있는 두 layer 모두를 가지고 있습니다. 그러나 그 두 층 사이에 seq2seq 모델의 attention과 비슷한 encoder-decoder attention이 포함되어 있습니다. 이것은 Decoder가 입력 문장 중에서 각 타임 스텝에서 가장 관련 있는 부분에 집중할 수 있도록 해줍니다.
여기까지가 Transformer의 큰 구조와 흐름이며, 다음으로 입력으로 들어온 문장이 출력이 될때까지 어떤 벡터 연산이 이루어지는지를 확인하는 목적으로 모델을 살펴봅니다.
벡터(Vector)들을 기준으로 그림 그려보기
먼저 입력 단어들을 embedding 알고리즘을 이요해 벡터로 바꾸는 것 부터 해야 합니다.
각 단어들은 크기 512의 벡터 하나로 embedding 되지만, 우선 위와 같은 간단한 박스로 나타내겠습니다.
이 embedding은 가장 밑단의 Encoder에서만 수행합니다. 이렇게 되면 가장 밑에 있는 Encoder의 경우는 Word embedding이 될 것이고, 다른 Encoder들은 바로 전의 Encoder의 출력을 받습니다.(이 embedding 벡터의 사이즈는 hypterparameter로 마음대로 정할 수 있으며, 대부분 데이터 셋에서 가장 긴 문장의 길이를 둡니다.)
이렇게 입력 문장의 단어들을 embedding 한 후에, 각 단어에 해당하는 벡터들은 Encoder 내의 두 개의 sub-layer로 들어가게 됩니다.
여기서 Transformer의 핵심 특성 중 하나인 각 위치의 단어가 인코더 내에서 자신만의 경로를 통해 흐른다는 것을 볼 수 있습니다. Self-Attention 층에서 이 위치에 따른 경로들 사이에 모두 dependency가 있습니다. 반면에 Feed-Froward 층은 이러한 dependency가 없기 때문에 다양한 경로들은 병렬처리가 될 수 있습니다.
Encoding
Encoder는 입력으로 벡터들의 리스트를 받습니다. 이 벡터의 리스트를 먼저 Self-Attention layer에, 그 다음으로 Feed-Forward 신경망에 통과시키고 그 결과물을 그 다음 Encoder에 전달합니다.
여기서 각 위치의 단어들은 각각 다른 Self-Encoding 과정을 거칩니다. 그 다음으로는 모두 같은 과정인 Feed-Forward 신경망을 거칩니다.
Self-Attention at a High Level
아까부터 계속 반복해서 말해오던 Self-Attention에 대해 설명하도록 하겠습니다.
"The animal didn’t cross the street because it was too tired" 이 문장을 번역하고 싶은 문장이라고 하겠습니다.
이 문장에서 "it" 이 가리키는 것은 무엇일까요? "street" 일까요 ? "animal" 일까요 ?
사람에게는 이것이 매우 간단한 질문이지만, 신경망은 아닙니다.
여기서 Self-Attention을 이용하여 단어를 처리하면, "it"과 "animal"을 연결할 수 있습니다 !
모델이 입력 문장 내의 각 단어(입력 시퀀스의 각 위치)를 처리할 때, Self-Attention은 입력 문장 내의 다른 위치에 있는 단어들을 보고 거기서 힌트를 받아 현재 타겟 위치의 단어를 더 잘 Encoding 할 수 있습니다.
RNN이 hidden state를 유지하고 업데이트함으로써 현재 처리 중인 단어에 어떻게 과거의 단어들에서 나온 맥락을 연관시키는 것 처럼. 이와 동일하게 Transformer에게는 이 Self-Attention이 현재 처리 중인 단어에 다른 연관 있는 단어들의 맥락을 붙여주는
Self-Attention
다음은 여러 가지 벡터들을 통해서 어떻게 Self-Attention을 계산할 수 있는지 살펴보겠습니다. 그 후 행렬을 이용해서 이것이 실제로 어떻게 구현돼 있는지 확인하겠습니다.
Self-Attention 계산의 가장 첫 단계는 Encoder에 입력된 벡터들(이 경우에는 각 단어의 embedding 벡터)에게서 부터 각 3개의 벡터를 만들어내는 일입니다. 이 3개의 벡터는 각 단어에 대한 Query 벡터, Key 벡터, Value 벡터라 합니다. 이 벡터들은 입력 벡터에 대해서 세 개의 학습 가능한 행렬들을 각각 곱함으로써 만들어 집니다.
여기서 한가지 짚고 넘어갈 것은 이 새로운 벡터들이 기존의 벡터들 보다 더 작은 사이즈를 가진다는 것입니다. 기존의 입력 벡터들은 크기가 512인 반면, 이 Q, K, V 벡터들은 각 크기가 64 입니다. 그러나 이 벡터들이 꼭 이렇게 작아야만 하는 것은 아니며, 이것은 그저 Multi-Head Attention의 계산 복잡도를 일정하게 만들고자 내린 구조적인 선택일 뿐입니다.
\(X_1\)을 Weight 행렬인 WQ로 곱하는 것은, 현재 단어와 연관된 query 벡터인 \(q_1\)를 생성합니다. 같은 방법으로 입력 문장에 있는 각 단어에 대한 query, key, value 벡터를 만들 수 있습니다.
그렇다면 정확히 이 query, key, value 벡터란 무엇을 의미하는 것일까요 ?
그것은 Attention에 대해서 생각하고 계산하려할 때 도움이 되는 추상적인 개념입니다. 이제 곧 다루게 될 테지만 어떻게 Attention이 실제로 계산되는지를 알면 자연스럽게 이 세 개의 벡터들이 어떤 역할을 하는지 알 수 있게 됩니다.
Self-Attention 계산의 두 번째 스텝은 점수를 계산하는 것입니다. 다음 예시의 첫 번째 단어인 "Thinking"에 대해서 Self-Attention을 계산한다고 하겠습니다. 이 "Thinking" 단어와 입력 문장 속의 다른 모든 단어들에 대해서 각각 점수를 계산해야 합니다. 이 점수는 현재 위치의 이 단어를 Encode 할 때 다른 단어들에 대해서 얼마나 집중을 해야 할지를 정합니다.
점수는 현재 단어의 query vector와 점수를 매기려 하는 다른 위치에 있는 단어의 key vector의 내적으로 계산됩니다.
다시 말해, 우리가 #1에 있는 단어에 대해서 Self-Attention을 계산한다 했을 때, 첫 번째 점수는 \(q_1\)과 \(k_1\)의 내적일 것입니다. 그리고 동일하게 두 번째 점수는 \(q_1\)과 \(k_2\)의 내적일 것입니다.
세 번째 단계는 이 점수들을 8로 나누는 것입니다. 이 8이라는 숫자는 key vector의 사이즈인 64의 제곱근(sqrt)라는 식으로 계산이 된 것입니다. 이 나눗셈을 통해 우리는 더 안정적인 gradient를 가지게 됩니다.(Normalize)
네 번째 단계는 8로 나눈 값을 softmax 계산을 통과시켜 모든 점수들을 양수로 만들고 그 합을 1로 만들어 줍니다.
이 softmax 점수는 각 단어가 현재 위치에서 얼마나 표현될지를 결정합니다. 당연하게 현재 위치의 단어가 가장 높은 점수를 가지겠지만, 가끔은 현재 단어에 관련이 있는 다른 단어에 대한 정보가 들어가는 것이 도움이 됩니다.
다섯 번째 단계는 각 vector value들을 softmax 점수와 곱하는 것입니다. 이렇게 하는 이유는, 우리가 집중하길 원하는 단어들의 값은 유지되고, 관련 없는 단어들은 0.0001과 같은 작은 숫자를 곱해 없애버리기 위함입니다.
마지막으로 여섯 번째 단계는 이 점수로 곱해진 weighted value vector(가중치가 적용된 value vector)들을 모두 합하는 것입니다. 이 단계의 출력이 바로 현재 위치에 대한 Self-Attention layer의 출력이 됩니다.
이러한 6단계의 과정들은 실제 구현에서는 빠른 속도를 위해 모든 과정들이 벡터가 아닌 행렬의 형태로 진행됩니다.
Self-Attention의 행렬 계산
가장 먼저 Qeury, Key, Value 행렬들을 계산합니다.
이를 위해 입력 벡터들(embedding 벡터들)을 하나의 행렬 \(X\)로 쌓아 올리고 그것을 학습할 행렬들인 \(WQ\), \(WK\), \(WV\)로 곱합니다.
\(X\)의 각 행은 입력 문장의 각 단어의 해당합니다.
여기서 다시 한번 embedding 벡터들 (크기 512, 위 그림에서는 4)과 query/key/value 벡터들(크기 64, 위 그림에서는 3) 간의 크기 차이를 볼 수 있습니다.
마지막으로, 현재 행렬을 이용하고 있으므로 앞서 설명했던 Self-Attention 계산 단계 2부터 6까지를 하나의 식으로 압축이 가능합니다.
The Beast With Many Heads
본 논문에서는 Self-Attention layer에다 Multi-Headed Attention 이라는 매커니즘을 더해 더욱 이를 개선합니다.
이것은 다음 두 가지 방법으로 Attention layer의 성능을 향상시킵니다.
- 모델이 서로 다른 위치에 집중할 수 있는 능력이 향상됩니다. 예를 들어 위의 예에서 \(z_1\)은 모든 다른 Encoding의 영향을 조금씩 받지만, 사실 이것은 실제 자기 자신에게만 높은 점수를 줘 자신만을 포함해도 됐을 것입니다.
- Attention layer가 여러 개의 "representation 공간"을 가지게 해줍니다. Multi-Headed Attention을 이용함으로써 여러 개의 query/key/value weight 행렬들을 가지게 됩니다.(본 논문에서 제안된 구조는 8개의 Attention Heads를 가지므로 각 Encoder/Decoder 마다 이런 8개의 세트를 가지게 됩니다.) 이 각각의 query/key/value set는 랜덤으로 초기화되어 학습됩니다. 학습이 된 후 각각의 세트는 입력 벡터들에 곱해져 벡터들을 각 목적에 맞게 투영시키게 됩니다. 이러한 세트가 여러개 있다는 것은 각 벡터들을 각각 다른 representation 공간으로 나타낸다는 것을 의미합니다.
Multi-Headed Attention을 이용하기 위해 각 head 마다 다른 query/key/value weight 행렬들을 모델에 가지게 됩니다.
위에서 설명했던 것처럼 같은 Self-Attention 계산을 8개의 다른 weight 행렬들에 거치게 되면, 8개의 서로 다른 \(Z\)행렬을 가지게 됩니다.
이렇게 8개의 서로 다른 \(Z\) 행렬은 바로 Feed-Forward layer로 보낼 수 없습니다. 왜냐하면, Feed-Forward layer는 한 위치에 대해 오직 한 개의 행렬만을 input으로 받을 수 있기 때문입니다. 그러므로 이 8개의 행렬을 하나의 행렬로 합치는 방법을 사용해야 합니다.
바로 모두 이어 붙여서 하나의 행렬로 만들고, 그 다음 하나의 도 다른 weight 행렬인 \(WO\)를 곱합니다.
이 과정들이 Multi-Headed Attention입니다. 다음 그림은 이 모든 과정을 하나의 그림으로 표현한 것입니다.
"The animal didn’t cross the street because it was too tired" 이 문장을 Multi-Headed Attention과 함께 보도록 하겠습니다. 그 중에서 특히 "it" 이란 단어를 Encode 할 때 여러 개의 Attention이 각각 어디에 집중하는지를 보겠습니다.
"it"이란 단어를 encode할 때, 주황색의 Attention Head는 "The animal"에 가장 집중하고 있는 반면, 초록색의 Attention Head는 "tired"라는 단어에 집중하고 있습니다. 모델은 이 두 개의 Attention Head를 이용하여 "animal"과 "tired" 두 단어 모두에 대한 representation을 "it"의 representation에 포함시킬 수 있습니다.
그러나 이 모든 Attention Head들을 하나의 그림으로 표현한다면, Attention의 의미는 해석하기 어려워 집니다.