
Rich feature hierarchies for accurate object detection and semantic segmentation
Object detection performance, as measured on the canonical PASCAL VOC dataset, has plateaued in the last few years. The best-performing methods are complex ensemble systems that typically combine multiple low-level image features with high-level context. I
arxiv.org
Abstract
- 본 논문에서는, 이전까지 최고의 성능을 보인 객체 검출 알고리즘보다 30% 이상 개선된 평균 정확도(mAP)를 가진 단순하면서 확장 가능한 탐지 알고리즘을 제안한다.
- 본 논문에서는 두 가지 핵심적인 아이디어를 조합하여 정확한 객체 검출 성능을 얻었다.
1. 물체의 localize와 segment을 정확하게 수행하기 위해, 제안 영역(region proposals)에 CNN을 적용한다.
2. 큰 데이터셋(ILSVRC)으로 사전 학습(pre-trained)을 수행한 후 해당 도메인에 특화된 데이터를 fine-tuning하여 성능을 크게 향상시켰다.
- R-CNN은 region proposals와 CNN을 결합한 방법으로, 이미지 내에서 “객체가 있을만한 위치”를 추측한 후, 해당 위치에 있는 이미지 영역을 잘라내어 CNN에 입력으로 사용한다.
Introduction
- SIFT와 HOG같은 블록 방식의 방향 히스토그램의 한계에 대해 설명합니다. (단순한 특징들에 너무 의존한다.)
- 객체 탐지는 Image Classification과 Image Localization을 필요로 한다.
- Image Localization을 위해 Sliding window detector를 사용한다.
- Sliding window detector란, 이미지를 격자 형태의 작은 조각으로 나누고, 각 조각에서 물체가 존재할 가능성이 있는 영역을 판단한다.
- 따라서 본 논문에서는 Sliding window detector을 사용하는 CNN을 구성하는 방법을 제시한다.
- 하지만 Sliding window detector는 탐색해야 할 격자(Grid)가 매우 많아 비용이 증가하게 되고, 필요 없는 부분(객체를 제외한 배경 등)까지 탐색하기 때문에 비용이 낭비되기까지 한다.
- 따라서 Region Proposals 알고리즘을 사용하여 객체가 있을 법한 영역(region)을 빠르게 찾아냅니다.
- 큰 데이터셋(ILSVRC)로 pre-trained 된 모델을 작은 데이터셋(PASCAL)에서 fine-tuning하여 8% 성능 향상을 보였다.
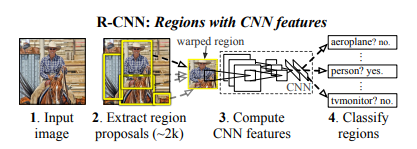
R-CNN System Overview.
1. 입력 이미지를 받아 2000개 정도의 bottom-up region proposal을 추출합니다.
2. 각 region proposal에 대해 warping을 하여 동일한 크기(227*227)의 이미지로 변환한다.
3. 변환한 이미지를 큰 CNN을 사용하여 각 proposal의 feature를 추출하며
4. 추출한 feature를 분류하기 위해 linear SVM을 사용합니다.
5. 분류한 결과를 regressor에 넣어 bounding box를 추출합니다.
Object detection with R-CNN
R-CNN의 Object detection 시스템은 3개의 모듈로 구성됩니다.
1. 범주에 독립적인(category-independent) region proposals을 생성합니다.
2. 고정길이의 특징 벡터(fixed-lenght feature vector)를 추출하기 위해 큰 CNN을 사용합니다.
3. 분류를 위해 linear SVM을 사용합니다.
\(\rightarrow\) category-independent란, Object detection에서 사용되는 region proposal(물체의 후보영역)이 특정 범주(category)와 무관하게 생성된다는 의미입니다. 즉, 객체 검출 시 이미지 내에서 물체를 검출해내는 단계와, 그 물체를 어떤 범주로 분류하는 단계가 분리되어 있다는 의미입니다.
Region Proposal
- Selective Search (R-CNN에서 사용하는 방법)
이미지를 각각 다른 색상, 텍스처, 경계 등의 기준으로 분할합니다. 이 분할 작업은
1. Pixel 간의 유사성을 기반으로 작업(계산)하며
2. 서로 겹치지 않는 영역으로 분할된 Pixel의 영역을 넓혀 세그먼트를 생성합니다.
3. 이 세그먼트영역 내에서 물체의 후보 영역을 선택합니다.

- Edge Boxes
이미지의 경계(Edge) map을 생성하여 이미지의 Bounding Box 영역의 후보군을 생성한 뒤 서로 연결된 영역을 찾아 묶어 Bounding Box로 만듭니다.

Feature extraction
- 각 region proposal(Selective Search로 도출한 영역) 2000개에서 AlextNet(CNN)을 사용하여 4096차원의 특징 벡터(feature vector)를 추출하였습니다.
- 입력 이미지(Input image)는 평균값이 빼진 227*227크기의 RGB 이미지로 전처리합니다.
- 여기에서 AlexNet은 5개의 Convolution Layer와 2개의 Fully Connected Layer로 구성되어 있습니다.
\(\rightarrow\) region proposal로 추출한 영역은 다양한 크기와 비율을 가지므로, 입력 크기에 맞도록 resize 해줘야 합니다. 이 때 고정된 크기로 resize하는 것이 아니라, CNN을 통해고정된 크기의 feature map으로 만드는 것입니다. 왜냐하면, 단순히 고정된 크기로 resize 하는 과정에서 이미지 내부의 정보가 일부 손실될 수 있기 때문입니다. 따라서 고정된 크기의 feature map으로 변환하여 다양한 크기와 비율을 가진 영역들을 입력으로 사용할 수 있게 합니다. 이를 warped region proposals라 칭합니다.
\(\rightarrow\) 입력 이미지에서 평균값을 빼는 이유는 일반적으로 이미지 데이터는 각각의 픽셀이 0~255 값을 가지는데, 이는 매우 큰 값이므로 딥러닝 모델에서 사용하기에는 부적절합니다. 따라서 이미지 데이터에서 각 채널마다 평균값을 빼주는 정규화 과정을 수행합니다. 이를 통해 모델 학습이 더욱 안정적이고 일반화 성능을 향상시킬 수 있습니다.
- AlexNet을 사용한 R-CNN의 좋은 효율성과 정확도에 대해 설명합니다.
Training
- R-CNN에서 사용된 CNN(AlexNet)은 대규모 데이터셋인 ILSVRC2012 classification을 사전 학습(pre-trained)하였습니다.
- 이렇게 학습 된 CNN(AlexNet)을 fine-tuning 하기 위해, 아키텍처는 변경하지 않고 마지막 classifier layer를 배경(backgroudn)를 포함한 (N(클래스 수) + 1(배경) \(\rightarrow\) way) 로 변경합니다.
- CNN을 fine-tuning하는 과정에서 ground-truth와 IoU 값이 0.5 이상인 box와 겹치는 region proposal을 positive로 처리하고 나머지는 negative(배경)으로 처리하여 학습합니다.
IoU (Intersection over Union)
두 개의 바운딩 박스(Bounding Box) 또는 영역(Region)이 겹치는 정도를 측정하는 지표입니다.
\(IoU(A,B) = (A \cap B) / (A \cup B)\)
\((A \cap B)\)은 두 영역이 겹치는 부분을, \(A \cup B)\)은 두 영역의 전체 영역을 나타냅니다.
따라서 IoU는 0과 1사이의 값을 가지며, 값이 1에 가까울수록 두 개의 영역이 매우 유사하거나 동일하다는 것을 의미합니다.
- SGD(확률적 경사하강법)을 사용하여 CNN의 파라미터를 fine-tuning합니다.
- 이러한 fine-turing 방법을 통해 pre-trained 된 CNN(AlexNet)에서 추출한 feature map을 활용하여 Object detection을 위한 SVM Classifier를 학습하는데 사용됩니다.
- CNN Classifier 보다 SVM을 사용했을 때 mAP 성능이 4% 정도 향상되었기 때문에 사용합니다.
- SVM Classifier는 이진 분류기(binary-classification)이며, 하나의 클래스와 그 외의 클래스(배경)을 구분하는 역할을 합니다. 즉, 특정 클래스의 객체가 이미지 내에 존재하는지 여부를 판별하는 역할을 합니다.
- 하지만 SVM을 학습할 때, positive와 negative 샘플 모두 포함하는 학습 데이터셋은 매우 크므로 메모리가 부족합니다.
- 이를 해결하기 위해 하드 네거티브 마이닝(hard negative mining) 방법을 사용합니다.
하드 네거티브 마이닝
학습 데이터에서 최상의 SVM 모델을 학습하기 위해 어려운 negative 샘플(오검출된 샘플)에 초점을 맞추는 방식입니다.
먼저 초기 모델을 사용하여 전체 학습 데이터셋을 실행한 후, 오검출된 샘플 중 일부를 추가하여 모델을 다시 학습합니다. 이러한 단계를 반복하여 최종 SVM 모델을 얻습니다.
R-CNN에서 하드 네거티브 마이닝은 모든 이미지에 대해 단일 패스를 수행한 후 mAP가 증가하지 않을 때까지 반복합니다. 이는 모든 샘플을 사용하여 학습하지 않고, 어려운 음성 샘플에 더 집중하여 학습 시간을 줄이는 데 도움이 되며, 수렴에 필요한 반복 횟수를 줄여 성능을 빠르게 할 수 있습니다.

참고 3
'Paper Review' 카테고리의 다른 글
| [FCN] Fully Convolutional Networks for Semantic Segmentation (0) | 2023.03.31 |
|---|---|
| [Transformer] Attention Is All You Need (2) (0) | 2023.03.24 |
| [Transformer] Attention Is All You Need (1) (0) | 2023.03.23 |
| [ResNet] Deep Residual Learning for Image Recongnition (0) | 2022.08.03 |
| [AlexNet] ImageNet Classification with Deep Convolutional Nerual Networks 정리 (0) | 2022.01.28 |
Rich feature hierarchies for accurate object detection and semantic segmentation
Object detection performance, as measured on the canonical PASCAL VOC dataset, has plateaued in the last few years. The best-performing methods are complex ensemble systems that typically combine multiple low-level image features with high-level context. I
arxiv.org
Abstract
- 본 논문에서는, 이전까지 최고의 성능을 보인 객체 검출 알고리즘보다 30% 이상 개선된 평균 정확도(mAP)를 가진 단순하면서 확장 가능한 탐지 알고리즘을 제안한다.
- 본 논문에서는 두 가지 핵심적인 아이디어를 조합하여 정확한 객체 검출 성능을 얻었다.
1. 물체의 localize와 segment을 정확하게 수행하기 위해, 제안 영역(region proposals)에 CNN을 적용한다.
2. 큰 데이터셋(ILSVRC)으로 사전 학습(pre-trained)을 수행한 후 해당 도메인에 특화된 데이터를 fine-tuning하여 성능을 크게 향상시켰다.
- R-CNN은 region proposals와 CNN을 결합한 방법으로, 이미지 내에서 “객체가 있을만한 위치”를 추측한 후, 해당 위치에 있는 이미지 영역을 잘라내어 CNN에 입력으로 사용한다.
Introduction
- SIFT와 HOG같은 블록 방식의 방향 히스토그램의 한계에 대해 설명합니다. (단순한 특징들에 너무 의존한다.)
- 객체 탐지는 Image Classification과 Image Localization을 필요로 한다.
- Image Localization을 위해 Sliding window detector를 사용한다.
- Sliding window detector란, 이미지를 격자 형태의 작은 조각으로 나누고, 각 조각에서 물체가 존재할 가능성이 있는 영역을 판단한다.
- 따라서 본 논문에서는 Sliding window detector을 사용하는 CNN을 구성하는 방법을 제시한다.
- 하지만 Sliding window detector는 탐색해야 할 격자(Grid)가 매우 많아 비용이 증가하게 되고, 필요 없는 부분(객체를 제외한 배경 등)까지 탐색하기 때문에 비용이 낭비되기까지 한다.
- 따라서 Region Proposals 알고리즘을 사용하여 객체가 있을 법한 영역(region)을 빠르게 찾아냅니다.
- 큰 데이터셋(ILSVRC)로 pre-trained 된 모델을 작은 데이터셋(PASCAL)에서 fine-tuning하여 8% 성능 향상을 보였다.
R-CNN System Overview.
1. 입력 이미지를 받아 2000개 정도의 bottom-up region proposal을 추출합니다.
2. 각 region proposal에 대해 warping을 하여 동일한 크기(227*227)의 이미지로 변환한다.
3. 변환한 이미지를 큰 CNN을 사용하여 각 proposal의 feature를 추출하며
4. 추출한 feature를 분류하기 위해 linear SVM을 사용합니다.
5. 분류한 결과를 regressor에 넣어 bounding box를 추출합니다.
Object detection with R-CNN
R-CNN의 Object detection 시스템은 3개의 모듈로 구성됩니다.
1. 범주에 독립적인(category-independent) region proposals을 생성합니다.
2. 고정길이의 특징 벡터(fixed-lenght feature vector)를 추출하기 위해 큰 CNN을 사용합니다.
3. 분류를 위해 linear SVM을 사용합니다.
\(\rightarrow\) category-independent란, Object detection에서 사용되는 region proposal(물체의 후보영역)이 특정 범주(category)와 무관하게 생성된다는 의미입니다. 즉, 객체 검출 시 이미지 내에서 물체를 검출해내는 단계와, 그 물체를 어떤 범주로 분류하는 단계가 분리되어 있다는 의미입니다.
Region Proposal
- Selective Search (R-CNN에서 사용하는 방법)
이미지를 각각 다른 색상, 텍스처, 경계 등의 기준으로 분할합니다. 이 분할 작업은
1. Pixel 간의 유사성을 기반으로 작업(계산)하며
2. 서로 겹치지 않는 영역으로 분할된 Pixel의 영역을 넓혀 세그먼트를 생성합니다.
3. 이 세그먼트영역 내에서 물체의 후보 영역을 선택합니다.
- Edge Boxes
이미지의 경계(Edge) map을 생성하여 이미지의 Bounding Box 영역의 후보군을 생성한 뒤 서로 연결된 영역을 찾아 묶어 Bounding Box로 만듭니다.
Feature extraction
- 각 region proposal(Selective Search로 도출한 영역) 2000개에서 AlextNet(CNN)을 사용하여 4096차원의 특징 벡터(feature vector)를 추출하였습니다.
- 입력 이미지(Input image)는 평균값이 빼진 227*227크기의 RGB 이미지로 전처리합니다.
- 여기에서 AlexNet은 5개의 Convolution Layer와 2개의 Fully Connected Layer로 구성되어 있습니다.
\(\rightarrow\) region proposal로 추출한 영역은 다양한 크기와 비율을 가지므로, 입력 크기에 맞도록 resize 해줘야 합니다. 이 때 고정된 크기로 resize하는 것이 아니라, CNN을 통해고정된 크기의 feature map으로 만드는 것입니다. 왜냐하면, 단순히 고정된 크기로 resize 하는 과정에서 이미지 내부의 정보가 일부 손실될 수 있기 때문입니다. 따라서 고정된 크기의 feature map으로 변환하여 다양한 크기와 비율을 가진 영역들을 입력으로 사용할 수 있게 합니다. 이를 warped region proposals라 칭합니다.
\(\rightarrow\) 입력 이미지에서 평균값을 빼는 이유는 일반적으로 이미지 데이터는 각각의 픽셀이 0~255 값을 가지는데, 이는 매우 큰 값이므로 딥러닝 모델에서 사용하기에는 부적절합니다. 따라서 이미지 데이터에서 각 채널마다 평균값을 빼주는 정규화 과정을 수행합니다. 이를 통해 모델 학습이 더욱 안정적이고 일반화 성능을 향상시킬 수 있습니다.
- AlexNet을 사용한 R-CNN의 좋은 효율성과 정확도에 대해 설명합니다.
Training
- R-CNN에서 사용된 CNN(AlexNet)은 대규모 데이터셋인 ILSVRC2012 classification을 사전 학습(pre-trained)하였습니다.
- 이렇게 학습 된 CNN(AlexNet)을 fine-tuning 하기 위해, 아키텍처는 변경하지 않고 마지막 classifier layer를 배경(backgroudn)를 포함한 (N(클래스 수) + 1(배경) \(\rightarrow\) way) 로 변경합니다.
- CNN을 fine-tuning하는 과정에서 ground-truth와 IoU 값이 0.5 이상인 box와 겹치는 region proposal을 positive로 처리하고 나머지는 negative(배경)으로 처리하여 학습합니다.
IoU (Intersection over Union)
두 개의 바운딩 박스(Bounding Box) 또는 영역(Region)이 겹치는 정도를 측정하는 지표입니다.
\(IoU(A,B) = (A \cap B) / (A \cup B)\)
\((A \cap B)\)은 두 영역이 겹치는 부분을, \(A \cup B)\)은 두 영역의 전체 영역을 나타냅니다.
따라서 IoU는 0과 1사이의 값을 가지며, 값이 1에 가까울수록 두 개의 영역이 매우 유사하거나 동일하다는 것을 의미합니다.
- SGD(확률적 경사하강법)을 사용하여 CNN의 파라미터를 fine-tuning합니다.
- 이러한 fine-turing 방법을 통해 pre-trained 된 CNN(AlexNet)에서 추출한 feature map을 활용하여 Object detection을 위한 SVM Classifier를 학습하는데 사용됩니다.
- CNN Classifier 보다 SVM을 사용했을 때 mAP 성능이 4% 정도 향상되었기 때문에 사용합니다.
- SVM Classifier는 이진 분류기(binary-classification)이며, 하나의 클래스와 그 외의 클래스(배경)을 구분하는 역할을 합니다. 즉, 특정 클래스의 객체가 이미지 내에 존재하는지 여부를 판별하는 역할을 합니다.
- 하지만 SVM을 학습할 때, positive와 negative 샘플 모두 포함하는 학습 데이터셋은 매우 크므로 메모리가 부족합니다.
- 이를 해결하기 위해 하드 네거티브 마이닝(hard negative mining) 방법을 사용합니다.
하드 네거티브 마이닝
학습 데이터에서 최상의 SVM 모델을 학습하기 위해 어려운 negative 샘플(오검출된 샘플)에 초점을 맞추는 방식입니다.
먼저 초기 모델을 사용하여 전체 학습 데이터셋을 실행한 후, 오검출된 샘플 중 일부를 추가하여 모델을 다시 학습합니다. 이러한 단계를 반복하여 최종 SVM 모델을 얻습니다.
R-CNN에서 하드 네거티브 마이닝은 모든 이미지에 대해 단일 패스를 수행한 후 mAP가 증가하지 않을 때까지 반복합니다. 이는 모든 샘플을 사용하여 학습하지 않고, 어려운 음성 샘플에 더 집중하여 학습 시간을 줄이는 데 도움이 되며, 수렴에 필요한 반복 횟수를 줄여 성능을 빠르게 할 수 있습니다.
참고 3
'Paper Review' 카테고리의 다른 글
| [FCN] Fully Convolutional Networks for Semantic Segmentation (0) | 2023.03.31 |
|---|---|
| [Transformer] Attention Is All You Need (2) (0) | 2023.03.24 |
| [Transformer] Attention Is All You Need (1) (0) | 2023.03.23 |
| [ResNet] Deep Residual Learning for Image Recongnition (0) | 2022.08.03 |
| [AlexNet] ImageNet Classification with Deep Convolutional Nerual Networks 정리 (0) | 2022.01.28 |