
Overfitting & Underfitting
우리가 모델을 학습할 때, 파라미터(parameter)를 수정(update)하여 학습 데이터에 맞는 모델을 만드는 것이 목표입니다.
즉 일반화(Generalization) 성능을 높이는 것을 목표로 합니다.
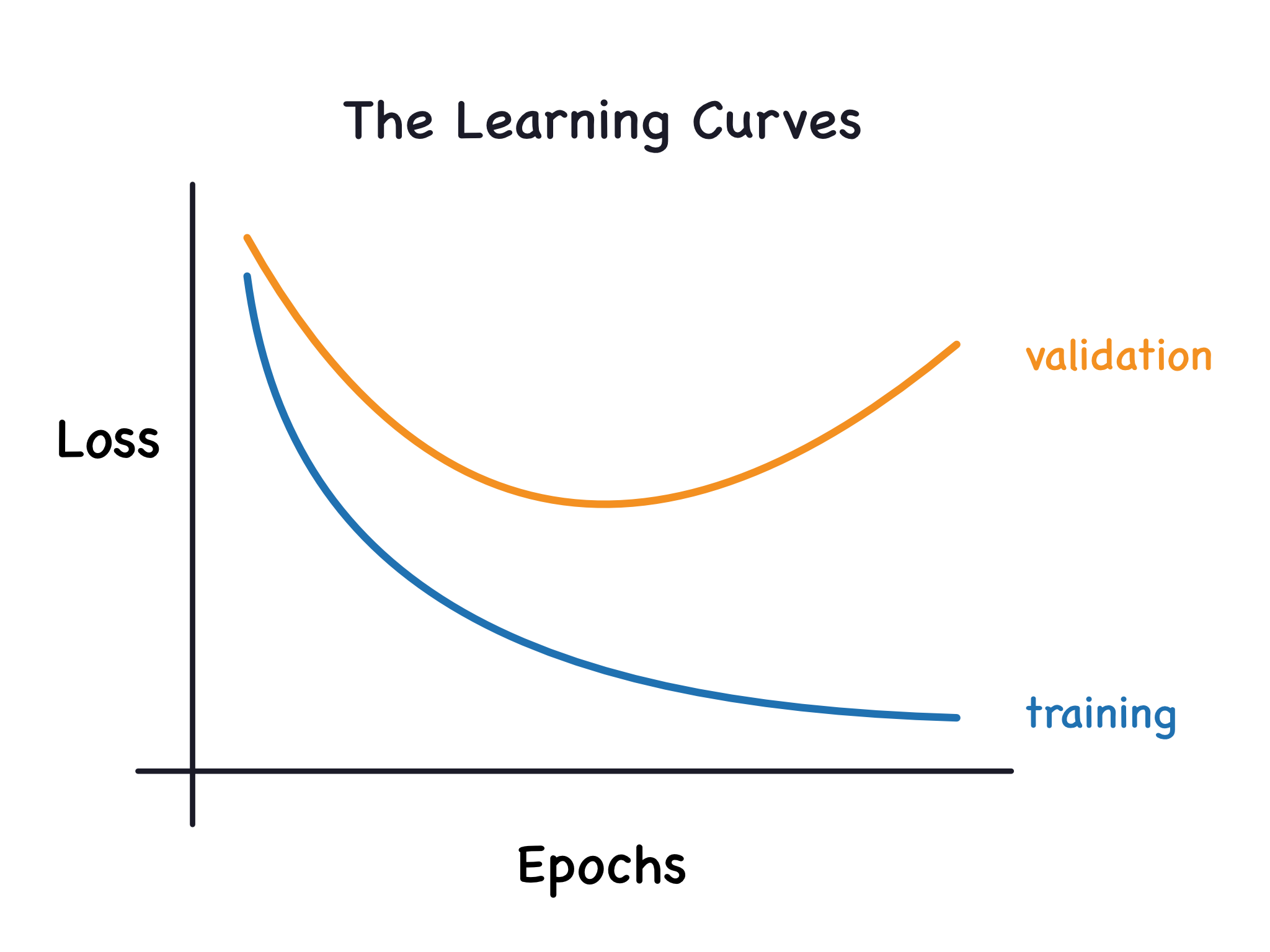
위 그림과 같이 Train Loss는 낮지만 Valid Loss는 커지고 있습니다. 이런 상황을 일반화 성능이 안좋다고 말하며, 당연히 Train Loss 자체가 낮아도 이 일반화 성능이 안좋다고 말합니다.
위 그림처럼 너무 많이 학습 데이터에만 집중하다 보면 훈련 데이터에는 잘 맞지만 새로운 데이터에는 맞지 않은 과적합(Overfitting)이 일어날 수 있습니다.
반대로, 모델이 너무 단순하거나 학습 데이터가 너무 작다면 학습 데이터를 제대로 설명하지 못하는 과소적합(Underfitting)이 일어날 수 있습니다.

Variance & Bias
Variance(분산)이란 데이터가 얼마나 퍼져있는지를 나타내는 지표(척도)입니다. 데이터의 분산이 크다는 것은 데이터가 평균적으로부터 멀리 흩어져 있음을 의미합니다.
Bias(편향)이란 예측값이 목표값(target)으로부터 얼마나 떨어져있는지(차이)를 나타내는 지표(척도)입니다. 모델의 편향이 크다면, 예측 값이 실제 값에서 멀리 떨어져 있을 가능성이 높습니다.
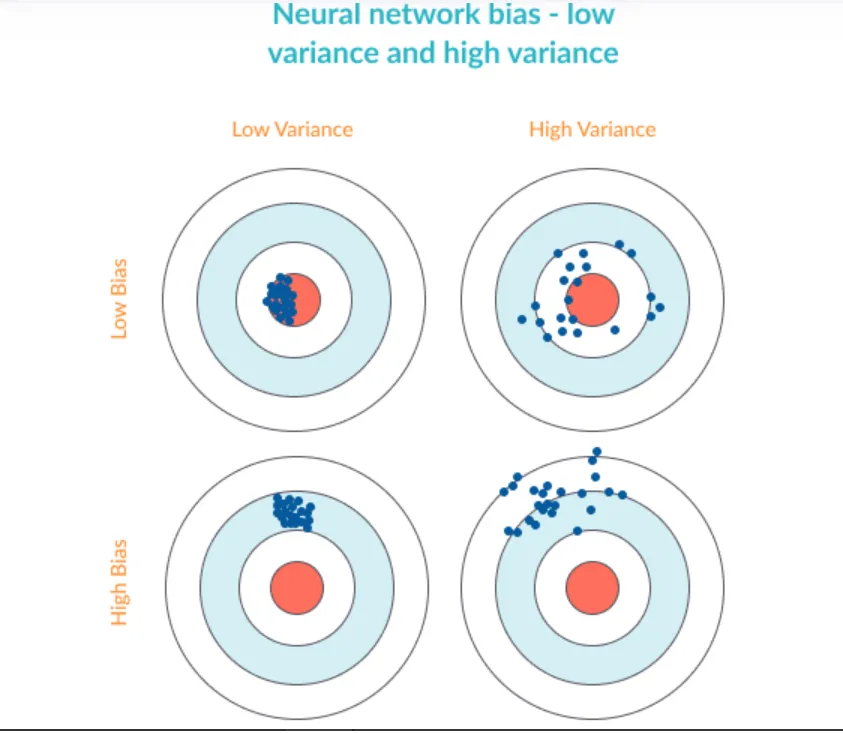
이 분산과 편향은 서로 반비례 관계(Trade-off) 입니다.
모델의 분산이 크다는 것은 모델의 복잡도가 높다는 뜻이고, 이는 학습 데이터에 대한 예측 성능은 높지만, 새로운 데이터에 대한 예측 성능이 낮아질 가능성이 높습니다.(Overfitting)
반면 모델의 편향이 크다는 것은 모델의 복잡도가 낮다는 뜻이고, 학습 데이터에 대한 예측 성능이 낮아지는 것을 의미합니다. 즉, 모델이 학습 데이터에 대한 패턴을 잡아내지 못해서 발생하는 경우가 많습니다.(Underfitting)
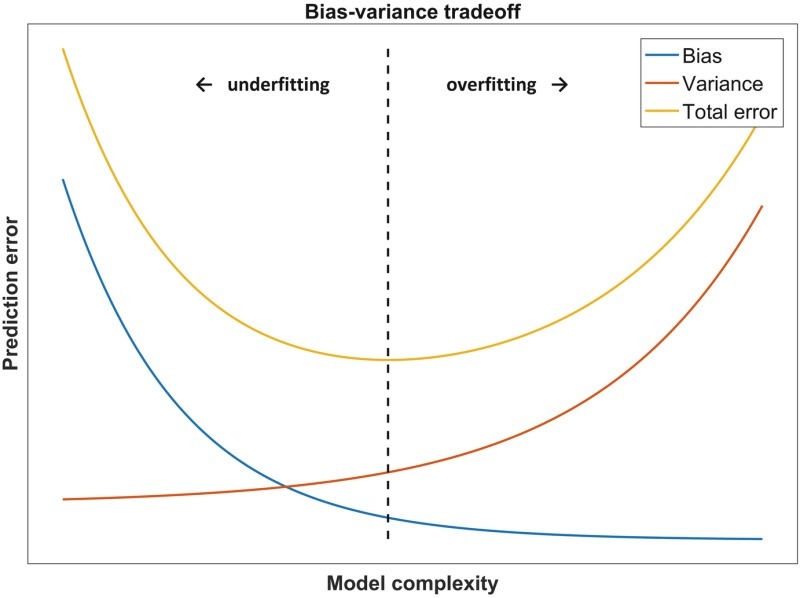
따라서, 적절한 편향과 분산의 Trade off를 유지하는 것이 중요합니다.
'ML & DL > 기초 이론' 카테고리의 다른 글
| Probability Model(확률 모형), Random Variable(확률 변수) (0) | 2023.03.22 |
|---|---|
| Regularization: Overfitting을 해결하는 방법들 (0) | 2023.03.21 |
| Gradient Descent & Optimizer(SGD, Momentum, Adagrad, RMSprop, Adam) (0) | 2023.03.20 |
| Neural Network & Linear Neural Networks & Multi Layer Perceptron (0) | 2023.03.20 |
| [CNN] Convolution Neural Network 정리 (0) | 2022.01.27 |
Overfitting & Underfitting
우리가 모델을 학습할 때, 파라미터(parameter)를 수정(update)하여 학습 데이터에 맞는 모델을 만드는 것이 목표입니다.
즉 일반화(Generalization) 성능을 높이는 것을 목표로 합니다.
위 그림과 같이 Train Loss는 낮지만 Valid Loss는 커지고 있습니다. 이런 상황을 일반화 성능이 안좋다고 말하며, 당연히 Train Loss 자체가 낮아도 이 일반화 성능이 안좋다고 말합니다.
위 그림처럼 너무 많이 학습 데이터에만 집중하다 보면 훈련 데이터에는 잘 맞지만 새로운 데이터에는 맞지 않은 과적합(Overfitting)이 일어날 수 있습니다.
반대로, 모델이 너무 단순하거나 학습 데이터가 너무 작다면 학습 데이터를 제대로 설명하지 못하는 과소적합(Underfitting)이 일어날 수 있습니다.
Variance & Bias
Variance(분산)이란 데이터가 얼마나 퍼져있는지를 나타내는 지표(척도)입니다. 데이터의 분산이 크다는 것은 데이터가 평균적으로부터 멀리 흩어져 있음을 의미합니다.
Bias(편향)이란 예측값이 목표값(target)으로부터 얼마나 떨어져있는지(차이)를 나타내는 지표(척도)입니다. 모델의 편향이 크다면, 예측 값이 실제 값에서 멀리 떨어져 있을 가능성이 높습니다.
이 분산과 편향은 서로 반비례 관계(Trade-off) 입니다.
모델의 분산이 크다는 것은 모델의 복잡도가 높다는 뜻이고, 이는 학습 데이터에 대한 예측 성능은 높지만, 새로운 데이터에 대한 예측 성능이 낮아질 가능성이 높습니다.(Overfitting)
반면 모델의 편향이 크다는 것은 모델의 복잡도가 낮다는 뜻이고, 학습 데이터에 대한 예측 성능이 낮아지는 것을 의미합니다. 즉, 모델이 학습 데이터에 대한 패턴을 잡아내지 못해서 발생하는 경우가 많습니다.(Underfitting)
따라서, 적절한 편향과 분산의 Trade off를 유지하는 것이 중요합니다.
'ML & DL > 기초 이론' 카테고리의 다른 글
| Probability Model(확률 모형), Random Variable(확률 변수) (0) | 2023.03.22 |
|---|---|
| Regularization: Overfitting을 해결하는 방법들 (0) | 2023.03.21 |
| Gradient Descent & Optimizer(SGD, Momentum, Adagrad, RMSprop, Adam) (0) | 2023.03.20 |
| Neural Network & Linear Neural Networks & Multi Layer Perceptron (0) | 2023.03.20 |
| [CNN] Convolution Neural Network 정리 (0) | 2022.01.27 |