
앞의 포스트에서 Overfitting과 Underfitting에 대해 설명하였습니다.
여기서 Overfitting이 발생하지 않도록 미리 예방하는 기법들이 다양하게 있는데 차례대로 설명하겠습니다.
Regularization(정규화)을 설명하기 앞서, Normalization도 정규화라고 불리기 때문에 개념을 정확히 구분해야 합니다.
Normalization은 데이터의 값을 조정하는 작업이며, Regularization은 모델의 복잡도를 조정하는 작업입니다.
Regularization
Regularization(정규화)은 모델에 제약(penalty)를 주어 복잡도를 줄이는 방법입니다.
모델의 복잡도는 모델이 가지는 파라미터의 수에 비례하며, Regularization은 이 파라미터의 값이 커지는 것을 제한하거나 제거해서 모델의 복잡도를 줄이는 방법으로 구현됩니다.
Regularization의 기본적인 방법은 가중치(weight)에 규제(penalty)를 거는 것 입니다. 이 규제를 거는 방법은 Error에 해당 weight를 더해주는 것입니다. 이러한 방식음 다음 2가지가 있습니다.
L1 Regularization
모델의 가중치(weight) 중에서 작은 값을 0으로 만들어서 모델의 복잡도를 줄입니다. 이를 위해 weight의 절대값을 손실 함수(Cost Function, \(C\))에 추가합니다. 이렇게 하면, 작은 가중치는 0으로 만들어져서 모델의 파라미터 수를 줄이고, 모델의 복잡도를 줄일 수 있습니다. 이때 \(\lambda\)는 상수로 0에 가까울 수록 정규화의 효과는 없어집니다. \(n\)은 데이터의 수
$$ C = C_0 + \frac{\lambda}{n} \sum_w \|w\| $$
$$ w \rightarrow w' = w - \frac{\eta \lambda}{n}sgn(w) - \eta \frac{\partial C_0}{\partial w} $$
L2 Regularization
모델의 가중치(weight) 중에서 큰 값을 작게 만들어서 모델의 복잡도를 줄입니다. 이를 위해 가중치의 제곱을 손실 함수에 추가합니다. 이렇게 하면, 큰 가중치는 작게 만들어져서 모델의 파라미터 수를 줄이고, 모델의 복잡도를 줄일 수 있습니다.
$$ C = C_0 + \frac{\lambda}{2n} \sum_w w^2 $$
$$ w \rightarrow w - \eta \frac{\partial C_0}{\partial w} - \frac{\eta \lambda}{n} w = (1 - \frac{\eta \lambda}{n})w - \eta \frac{\partial C_0}{\partial w} $$
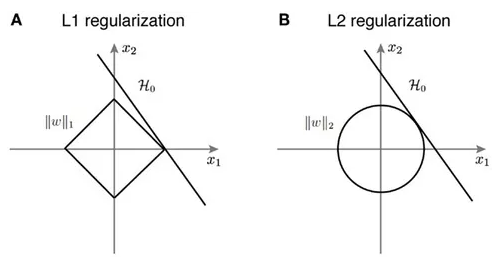
L1은 통상적으로 상수 값을 빼주도록 되어 있기 때문에 특정 weight들은 0으로 수렴하게 되어 몇 개의 중요한 가중치들만 남게 된다. 그러므로 몇 개의 의미 있는 값을 끄집어 내고 싶은 경우에는 L1이 효과적이다. 단, 미분 불가능한 점이 있기 때문에 주의가 필요하다.
Dropout
Dropout은 학습 시에 무작위로 일부 뉴런(노드)을 선택하여 해당 뉴런의 출력을 0으로 만드는 것입니다. 출력이 0이 된다는 의미는 학습에 참여하지 않도록 하는 것이고, 자연스럽게 역전파에서도 제외됩니다.
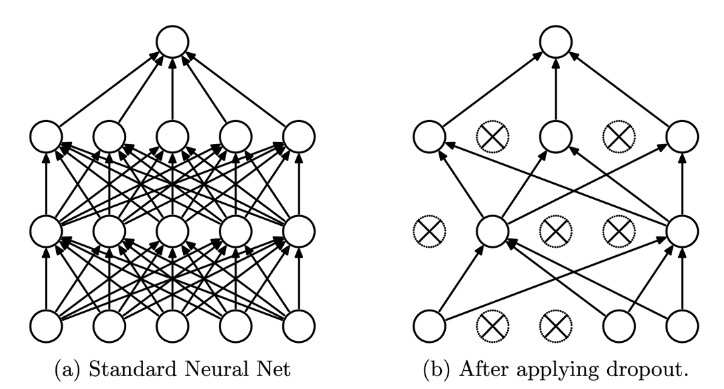
Dropout은 신경망 학습 시에만 사용하고, 예측 시에는 사용하지 않는 것이 일반적입니다. 학습 시에 인공 신경망이 특정 뉴런(노드)에 너무 의존적이게 되는 것을 방지하고, 다른 뉴런(노드)들에 대한 정보를 다양하게 학습하게 됩니다. 이러한 과정을 통해 모델의 일반화 성능을 높일 수 있습니다.
Early Stopping
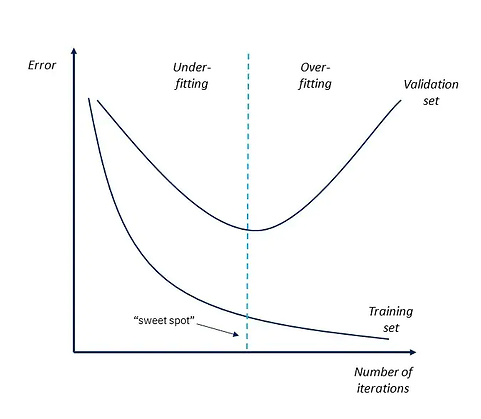
Early stopping은 Overfitting을 방지하기 위해, 학습 중에 모델의 성능을 측정하고 일정 기준에 도달하면 학습을 조기에 중단시키는 것입니다.
Early stopping은 보통 검증 데이터셋의 손실(Loss)을 기준으로 합니다. 모델이 학습하는 동안, 일정 간격으로 검증 데이터셋에서 손실을 계산하고, 이 손실 값이 일정 기간 동안 향상되지 않으면 학습을 종료합니다. 이렇게 하면 모델이 일정 수준 이상 학습된 후 일반화 성능의 차이가 커지기 전에 학습이 종료됩니다.
Batch Normalization
Gradient Descent에서는 gradient를 한 번 업데이트 하기 위해 모든 학습 데이터를 사용합니다.
하지만 이런 방식으로 학습을 하면 대용량의 데이터의 경우, 한 번에 처리하지 못하기 때문에 데이터를 batch 단위로 나눠서 학습을 사용하는 것이 일반적입니다.
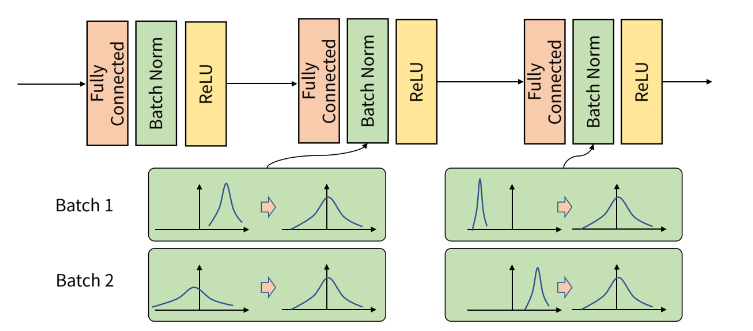
Batch Normalization은 학습 과정에서 각 배치 단위 별로 데이터가 다양한 분포를 가지더라도 각 배치별로 평균과 분산을 이용해 정규화 하는 것을 뜻합니다. 위 그림에서 batch 단위나 layer에 따라서 입력 값의 분포가 모두 다르지만, 정규화를 통하여 분포를 zero mean gaussian 형태로 만들었습니다. 그러면 평균은 0, 표준 편차는 1로 데이터의 분포를 조정할 수 있습니다.
여기서 주의해야 할 점은 Batch Normalization은 학습 단계와 추론 단계에서 조금 다르게 적용되어야 합니다.
먼저 학습 단계입니다. \(X\)는 입력, \(\gamma\)는 스케일링, \(\beta\)는 bias, \(\mu_{batch}\)는 배치별 평균값, \(\sigma_{batch}\) 배치별 표준편차 입니다.
$$ BN(X) = \gamma(\frac{X - \mu_{batch}}{\sigma_{batch}}) + \beta $$
\(\gamma\)와 \(\beta\)는 선형적으로 출력 값을 변화시키는 변수이기 때문에 역전파 알고리즘으로 학습이 가능합니다. 따라서 활성화 함수의 종류에 맞게 데이터 분포를 변화시킬 수 있다는 장점이 있습니다.
다음은 추론 단계입니다.
$$ BN(X) = \gamma (\frac{X - \mu_{BN}}{\sigma_{BN}}) + \beta $$
여기서 \(\mu_{BN}\)와 \(\sigma_{BN}\)는 학습 과정에서 이동 평균 또는 지수 평균을 통해 계산된 상수입니다.
예를 들어, 이동 평균을 사용하여 최근 \(N\)개의 데이터를 기반으로 (\mu_{BN}\)와 \(\sigma_{BN}\)는 아래와 같습니다.
$$ \mu_{BN} = \frac{1}{N} \sum_i \mu_{batch}^{i} $$
$$ \sigma_{BN} = \frac{1}{N} \sum_i \sigma_{batch}^{i} $$
Batch Normalization의 장점으로, 학습 데이터의 분포가 일정하지 않아, 각 층의 가중치가 업데이트 될 때마다 입력 분포가 바뀌는 현상(Internal Covariate Shift)을 해결하여, 학습 과정이 안정적이고 빠르게 수렴합니다. 또한 모델의 일반화 성능을 높여주기도 합니다.
또한, Batch Normalization은 모델의 복잡도를 증가시키는 효과가 있습니다. 입력 데이터에 대한 스케일링과 시프트가 가능해지므로, 더욱 복잡한 모델을 구현할 수 있습니다. 그러나 Batch Normailzation을 모든 층에 적용하는 것이 항상 좋은 결과를 가져오는 것은 아니기 때문에, 적절한 사용 방법을 고민하고 적용해야 합니다.
'ML & DL > 기초 이론' 카테고리의 다른 글
| Parameter Estimation (모수 추정), 가능도 (Likelihood), MLE (Maximum Likelihood Estimation) (0) | 2023.03.22 |
|---|---|
| Probability Model(확률 모형), Random Variable(확률 변수) (0) | 2023.03.22 |
| Overfitting & Underfitting (0) | 2023.03.21 |
| Gradient Descent & Optimizer(SGD, Momentum, Adagrad, RMSprop, Adam) (0) | 2023.03.20 |
| Neural Network & Linear Neural Networks & Multi Layer Perceptron (0) | 2023.03.20 |
앞의 포스트에서 Overfitting과 Underfitting에 대해 설명하였습니다.
여기서 Overfitting이 발생하지 않도록 미리 예방하는 기법들이 다양하게 있는데 차례대로 설명하겠습니다.
Regularization(정규화)을 설명하기 앞서, Normalization도 정규화라고 불리기 때문에 개념을 정확히 구분해야 합니다.
Normalization은 데이터의 값을 조정하는 작업이며, Regularization은 모델의 복잡도를 조정하는 작업입니다.
Regularization
Regularization(정규화)은 모델에 제약(penalty)를 주어 복잡도를 줄이는 방법입니다.
모델의 복잡도는 모델이 가지는 파라미터의 수에 비례하며, Regularization은 이 파라미터의 값이 커지는 것을 제한하거나 제거해서 모델의 복잡도를 줄이는 방법으로 구현됩니다.
Regularization의 기본적인 방법은 가중치(weight)에 규제(penalty)를 거는 것 입니다. 이 규제를 거는 방법은 Error에 해당 weight를 더해주는 것입니다. 이러한 방식음 다음 2가지가 있습니다.
L1 Regularization
모델의 가중치(weight) 중에서 작은 값을 0으로 만들어서 모델의 복잡도를 줄입니다. 이를 위해 weight의 절대값을 손실 함수(Cost Function, \(C\))에 추가합니다. 이렇게 하면, 작은 가중치는 0으로 만들어져서 모델의 파라미터 수를 줄이고, 모델의 복잡도를 줄일 수 있습니다. 이때 \(\lambda\)는 상수로 0에 가까울 수록 정규화의 효과는 없어집니다. \(n\)은 데이터의 수
$$ C = C_0 + \frac{\lambda}{n} \sum_w \|w\| $$
$$ w \rightarrow w' = w - \frac{\eta \lambda}{n}sgn(w) - \eta \frac{\partial C_0}{\partial w} $$
L2 Regularization
모델의 가중치(weight) 중에서 큰 값을 작게 만들어서 모델의 복잡도를 줄입니다. 이를 위해 가중치의 제곱을 손실 함수에 추가합니다. 이렇게 하면, 큰 가중치는 작게 만들어져서 모델의 파라미터 수를 줄이고, 모델의 복잡도를 줄일 수 있습니다.
$$ C = C_0 + \frac{\lambda}{2n} \sum_w w^2 $$
$$ w \rightarrow w - \eta \frac{\partial C_0}{\partial w} - \frac{\eta \lambda}{n} w = (1 - \frac{\eta \lambda}{n})w - \eta \frac{\partial C_0}{\partial w} $$
L1은 통상적으로 상수 값을 빼주도록 되어 있기 때문에 특정 weight들은 0으로 수렴하게 되어 몇 개의 중요한 가중치들만 남게 된다. 그러므로 몇 개의 의미 있는 값을 끄집어 내고 싶은 경우에는 L1이 효과적이다. 단, 미분 불가능한 점이 있기 때문에 주의가 필요하다.
Dropout
Dropout은 학습 시에 무작위로 일부 뉴런(노드)을 선택하여 해당 뉴런의 출력을 0으로 만드는 것입니다. 출력이 0이 된다는 의미는 학습에 참여하지 않도록 하는 것이고, 자연스럽게 역전파에서도 제외됩니다.
Dropout은 신경망 학습 시에만 사용하고, 예측 시에는 사용하지 않는 것이 일반적입니다. 학습 시에 인공 신경망이 특정 뉴런(노드)에 너무 의존적이게 되는 것을 방지하고, 다른 뉴런(노드)들에 대한 정보를 다양하게 학습하게 됩니다. 이러한 과정을 통해 모델의 일반화 성능을 높일 수 있습니다.
Early Stopping
Early stopping은 Overfitting을 방지하기 위해, 학습 중에 모델의 성능을 측정하고 일정 기준에 도달하면 학습을 조기에 중단시키는 것입니다.
Early stopping은 보통 검증 데이터셋의 손실(Loss)을 기준으로 합니다. 모델이 학습하는 동안, 일정 간격으로 검증 데이터셋에서 손실을 계산하고, 이 손실 값이 일정 기간 동안 향상되지 않으면 학습을 종료합니다. 이렇게 하면 모델이 일정 수준 이상 학습된 후 일반화 성능의 차이가 커지기 전에 학습이 종료됩니다.
Batch Normalization
Gradient Descent에서는 gradient를 한 번 업데이트 하기 위해 모든 학습 데이터를 사용합니다.
하지만 이런 방식으로 학습을 하면 대용량의 데이터의 경우, 한 번에 처리하지 못하기 때문에 데이터를 batch 단위로 나눠서 학습을 사용하는 것이 일반적입니다.
Batch Normalization은 학습 과정에서 각 배치 단위 별로 데이터가 다양한 분포를 가지더라도 각 배치별로 평균과 분산을 이용해 정규화 하는 것을 뜻합니다. 위 그림에서 batch 단위나 layer에 따라서 입력 값의 분포가 모두 다르지만, 정규화를 통하여 분포를 zero mean gaussian 형태로 만들었습니다. 그러면 평균은 0, 표준 편차는 1로 데이터의 분포를 조정할 수 있습니다.
여기서 주의해야 할 점은 Batch Normalization은 학습 단계와 추론 단계에서 조금 다르게 적용되어야 합니다.
먼저 학습 단계입니다. \(X\)는 입력, \(\gamma\)는 스케일링, \(\beta\)는 bias, \(\mu_{batch}\)는 배치별 평균값, \(\sigma_{batch}\) 배치별 표준편차 입니다.
$$ BN(X) = \gamma(\frac{X - \mu_{batch}}{\sigma_{batch}}) + \beta $$
\(\gamma\)와 \(\beta\)는 선형적으로 출력 값을 변화시키는 변수이기 때문에 역전파 알고리즘으로 학습이 가능합니다. 따라서 활성화 함수의 종류에 맞게 데이터 분포를 변화시킬 수 있다는 장점이 있습니다.
다음은 추론 단계입니다.
$$ BN(X) = \gamma (\frac{X - \mu_{BN}}{\sigma_{BN}}) + \beta $$
여기서 \(\mu_{BN}\)와 \(\sigma_{BN}\)는 학습 과정에서 이동 평균 또는 지수 평균을 통해 계산된 상수입니다.
예를 들어, 이동 평균을 사용하여 최근 \(N\)개의 데이터를 기반으로 (\mu_{BN}\)와 \(\sigma_{BN}\)는 아래와 같습니다.
$$ \mu_{BN} = \frac{1}{N} \sum_i \mu_{batch}^{i} $$
$$ \sigma_{BN} = \frac{1}{N} \sum_i \sigma_{batch}^{i} $$
Batch Normalization의 장점으로, 학습 데이터의 분포가 일정하지 않아, 각 층의 가중치가 업데이트 될 때마다 입력 분포가 바뀌는 현상(Internal Covariate Shift)을 해결하여, 학습 과정이 안정적이고 빠르게 수렴합니다. 또한 모델의 일반화 성능을 높여주기도 합니다.
또한, Batch Normalization은 모델의 복잡도를 증가시키는 효과가 있습니다. 입력 데이터에 대한 스케일링과 시프트가 가능해지므로, 더욱 복잡한 모델을 구현할 수 있습니다. 그러나 Batch Normailzation을 모든 층에 적용하는 것이 항상 좋은 결과를 가져오는 것은 아니기 때문에, 적절한 사용 방법을 고민하고 적용해야 합니다.
'ML & DL > 기초 이론' 카테고리의 다른 글
| Parameter Estimation (모수 추정), 가능도 (Likelihood), MLE (Maximum Likelihood Estimation) (0) | 2023.03.22 |
|---|---|
| Probability Model(확률 모형), Random Variable(확률 변수) (0) | 2023.03.22 |
| Overfitting & Underfitting (0) | 2023.03.21 |
| Gradient Descent & Optimizer(SGD, Momentum, Adagrad, RMSprop, Adam) (0) | 2023.03.20 |
| Neural Network & Linear Neural Networks & Multi Layer Perceptron (0) | 2023.03.20 |