
잘못된 부분이 있다면 언제든지 알려주시면 감사하겠습니다 !
NOTION 정리
https://repeated-canvas-49b.notion.site/CNN-4b6279ec256d4b22a27ce0c85c6e65b5
CNN
Convolution Neural Network
repeated-canvas-49b.notion.site
CNN (Convolution Neural Network)
CNN은 DNN의 한계인 차원의 저주(curse of dimensionality)를 해결하기 위해 이미지의 공간 정보를 유지한 채 학습을 하는 모델입니다.
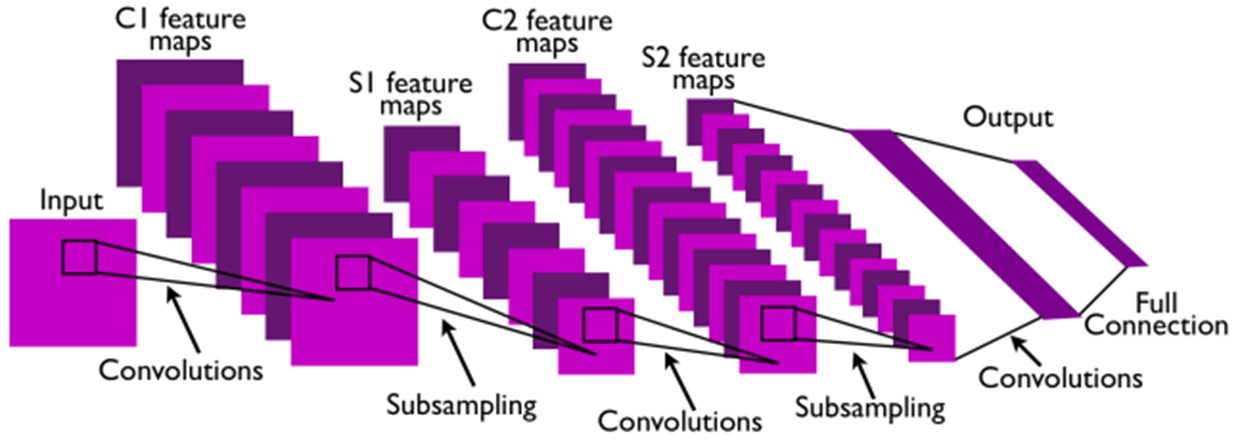
Convolutions와 Subsampling의 중요한 부분은 특징 추출(feature extraction)입니다.
여기서 추출한 특징을 바탕으로 연결한 Fully Connected Layer의 중요한 부분은 Classification(분류) 입니다.
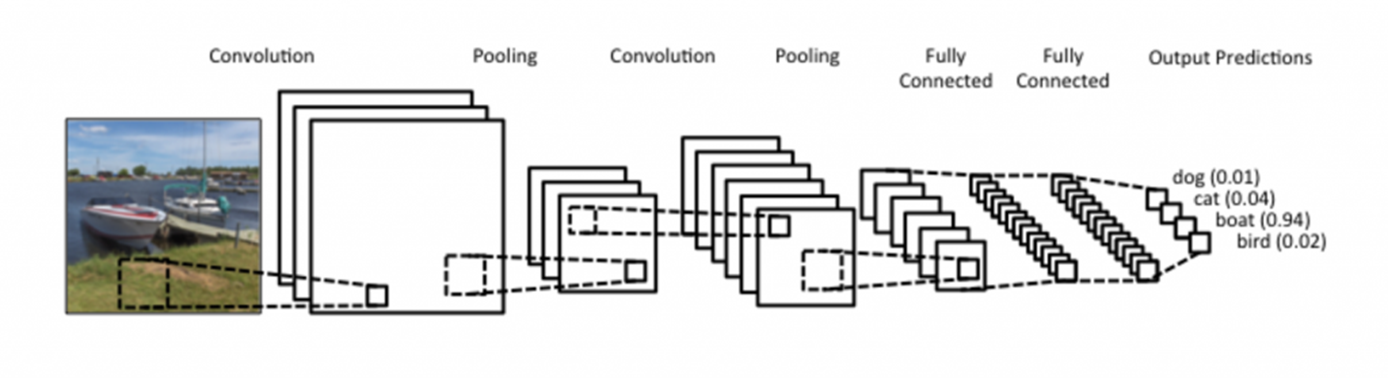
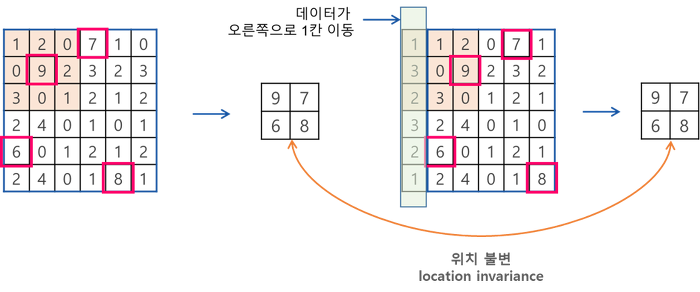
CNN의 장점으로 Local Invariance(국소적으로 비슷하다) 가 있습니다. 그 이유는 Convolution filters가 전체 이미지를 모두 돌아 다니는(sliding) 방법 때문입니다.
Convolution Layer
앞서 설명한 CNN의 핵심 부분으로 Convolution Layer에서 이미지를 Classification(분류) 하는데 필요한 Feature(특징) 정보들을 뽑아냅니다.
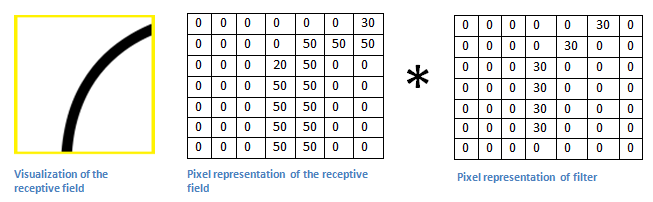
다음은 Convolution Filter가 Convolution을 통해 어떻게 Feature Map을 구성하는지 간단하게 나타낸 것입니다.
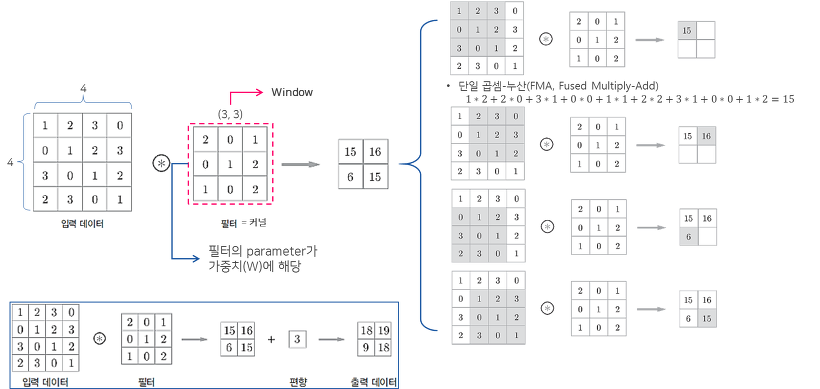
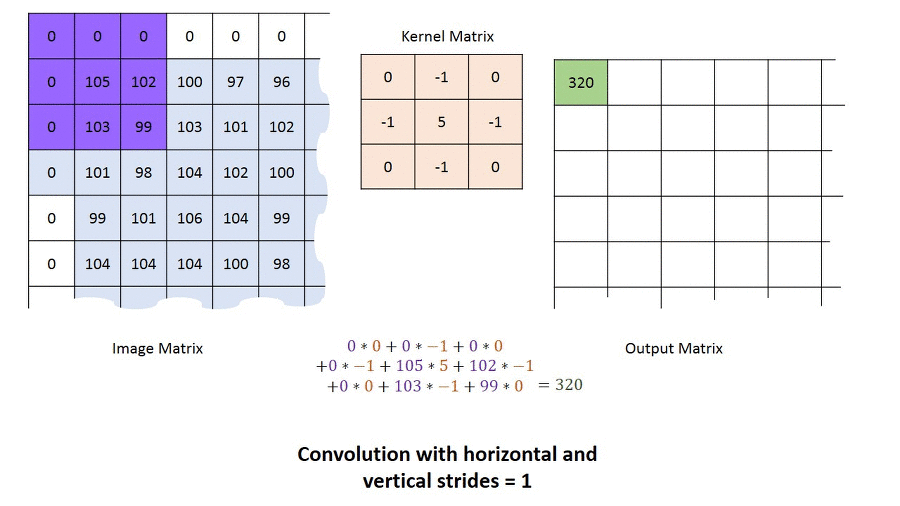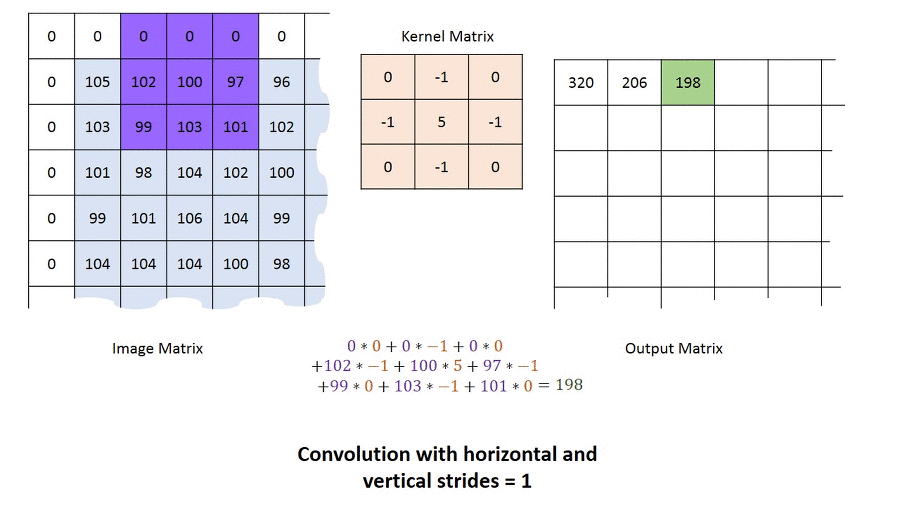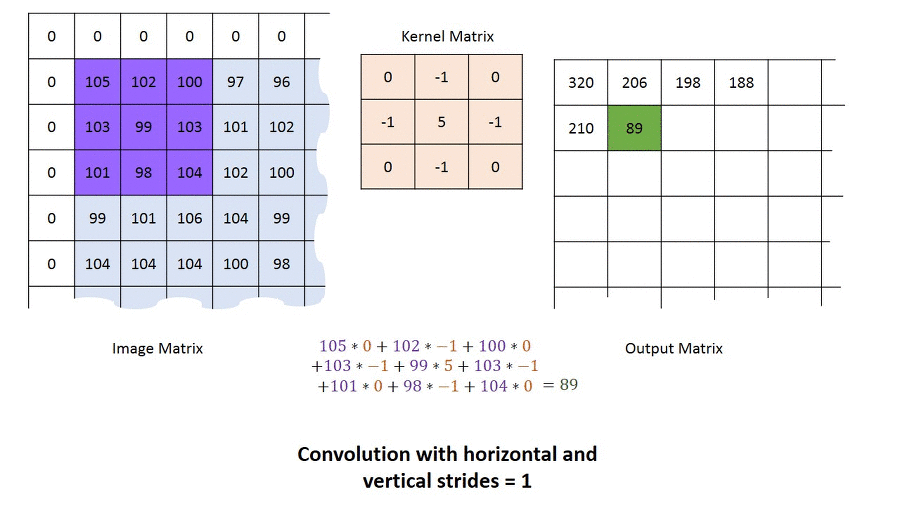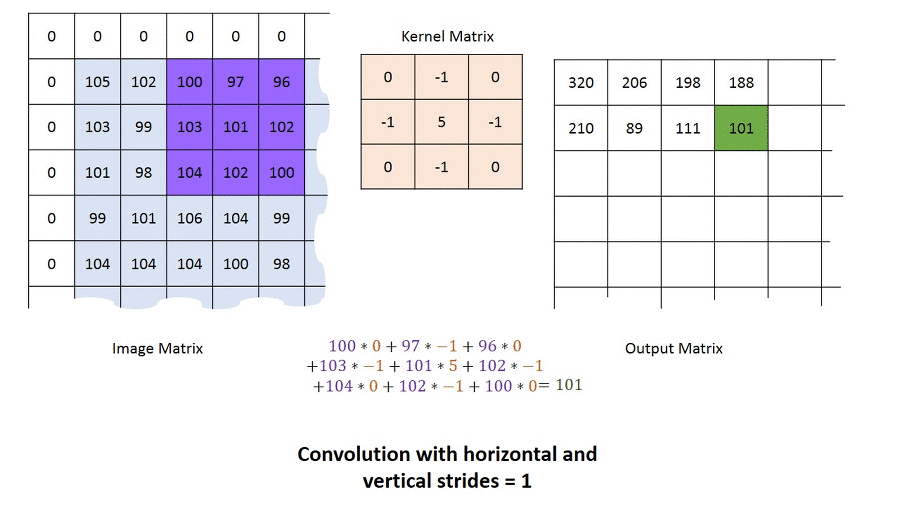
1. Convolution Filter(=Kernel=Window)를 일정한 간격으로 Stride(이동) 하며 Image에 적용 후 Filter에서 대응하는 원소끼리 곱한 후 그 총합을 구합니다. ( \(h\)는 커널의 크기, \(u\)는 커널, \(z\)는 입력, \(s\)는 출력 )
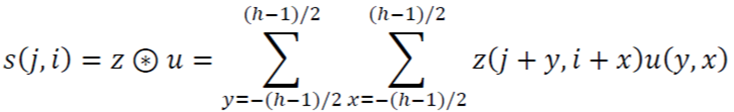
2. 이러한 Filter가 전체 이미지를 순회하고 나면 전체 이미지에서 해당 Filter와 유사한 모양을 가진 부분에 대한 Feature(특징) 을 얻을 수 있습니다.
\(\rightarrow\) 이러한 과정을 통해 “특정 Filter에 부합하는 Feature(특징) 정보를 얻었다.” 라고 말할 수 있습니다.
입력 Image의 채널이 여러 채널일 경우 필터는 각 채널을 순회하며 Convolution을 계산한 후, 각 채널의 Feature Map을 합산하여 최종 Feature Map 으로 반환합니다.

\(\rightarrow\) 하나의 Convolution Layer에 크기가 같은 여러 개의 Filter를 적용할 수 있습니다. 이 경우 Feature Map에 Filter 개수만큼 채널이 만들어집니다.
1. First Convolution Layer
CNN에서 물체의 윤곽을 알아내기 위해 제일 처음 하는 작업은 Edge Filter 입니다.
Convolution Filter는 모든 Layer에서 같은 크기로 고정되어 있습니다. 그렇기 때문에 Input Image 크기는 Convolution Filter 크기에 비해 상대적으로 크기 때문에 Filter가 이미지를 구분할 수 있는 부분이 선과 같은 단순한 정보(edge)입니다.
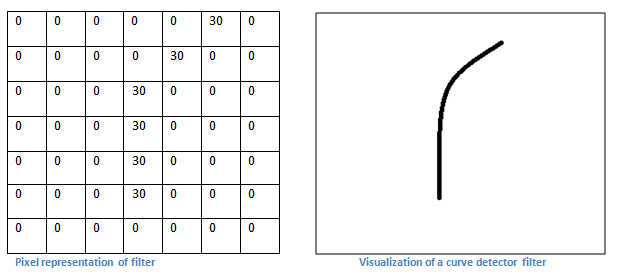
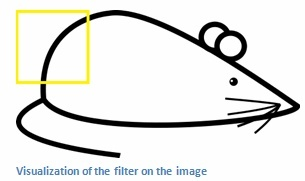
결과적으로 우리가 n개의 Filter를 사용하면 Convolution Layer 에서는 n개의 결과 값들이 나오게 되는데 이를 Feature Map 이라고 부릅니다.
처음에는 Convolution Filter 역시 초기 값 설정을 통해 Random 으로 분포하게 되지만 학습을 통해서 완성된 Edge Filter로 만들어지게 됩니다.

2. Padding
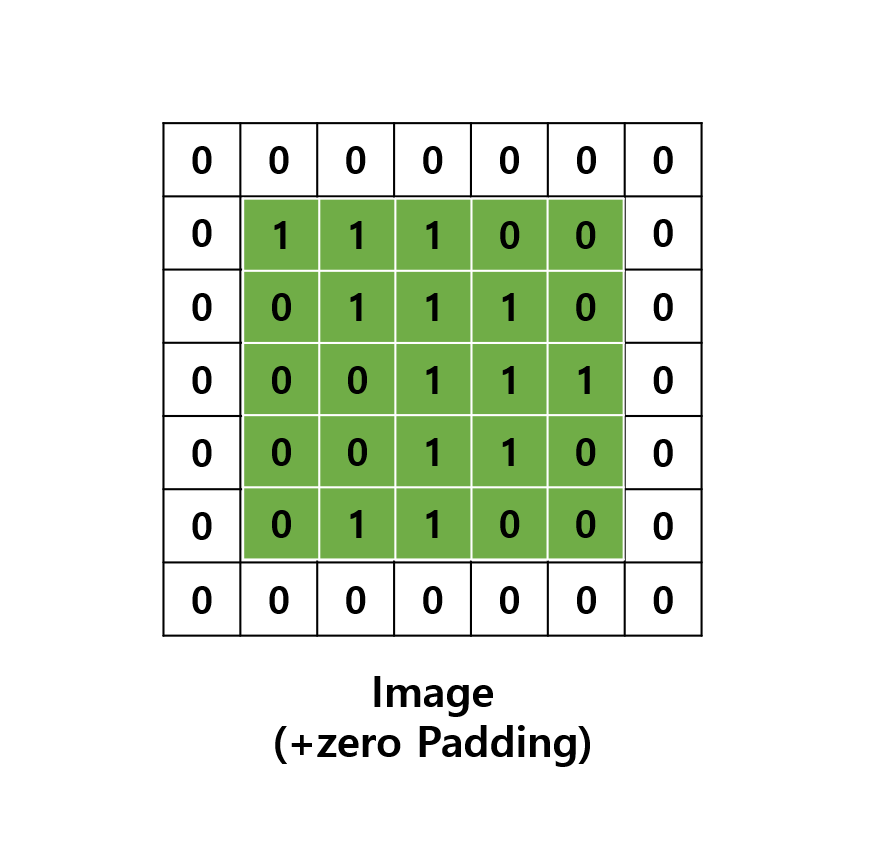
Padding(패딩)은 주로 출력 크기가 줄어드는 것을 방지하기 위해 사용됩니다.
예를 들어 다음과 같이 (5, 5)의 Image에 (3, 3)의 필터를 적용하면 출력은 (3, 3)이 되어 입력보다 2만큼 줄어들게 됩니다.
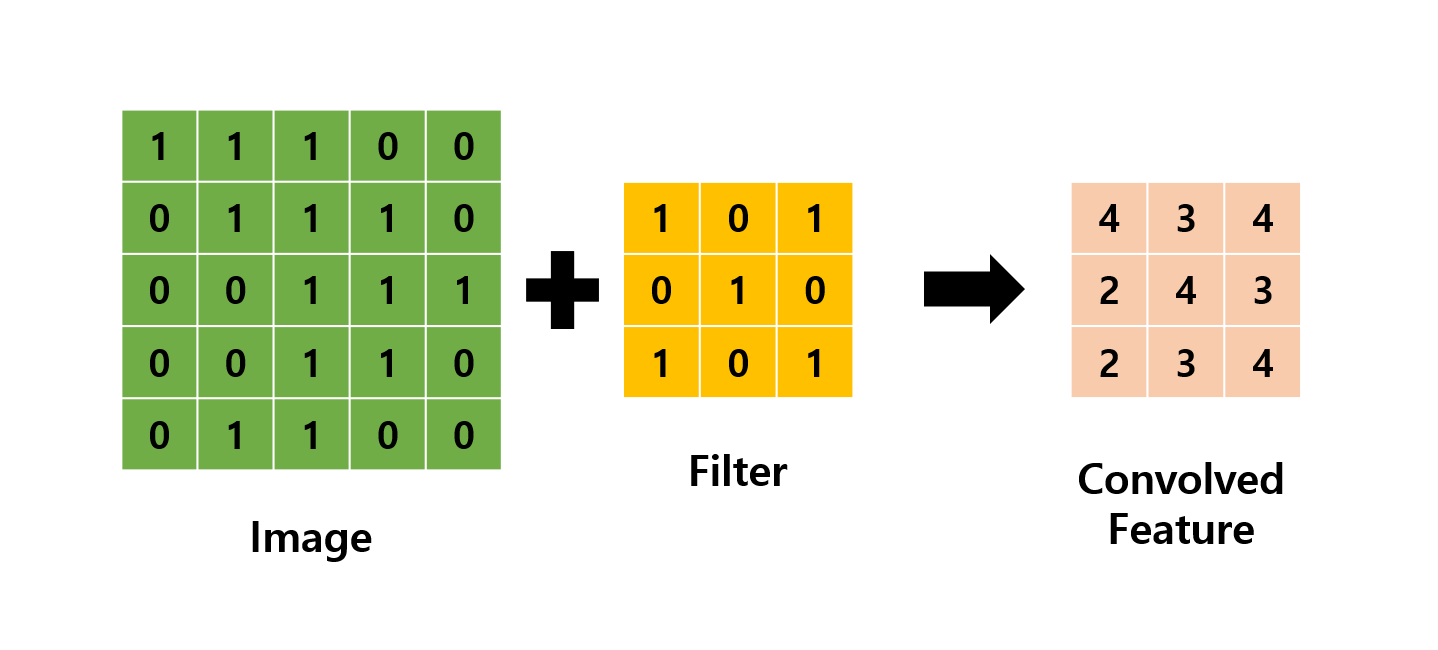
이를 몇 번 되풀이하면 출력 크기가 1이 되어 문제가 될 수 있습니다.
이를 해결하기 위해 Padding은 입력 데이터의 외각에 지정된 픽셀만큼 특정 값(0)을 채워 넣습니다.
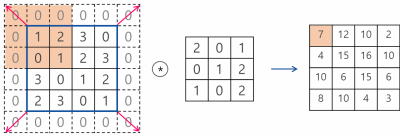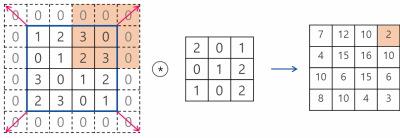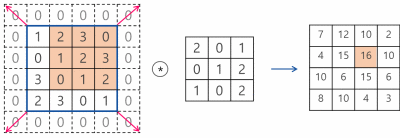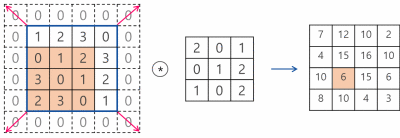
3. 출력 크기 계산
Padding과 Stride를 적용하고, 입력 Image와 Filter의 크기가 주어졌을 때 출력 데이터의 크기를 구하는 식은 다음과 같다.
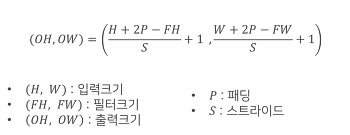

출력 크기가 정수가 아닌 경우에는 에러가 발생할 수 있으니 주의가 필요하다.
Pooling Layer (Subsampling)
이미지의 크기를 계속 유지한 채 Fully Connected Layer로 가게 된다면 연산량이 기하급수적으로 늘어납니다.
이를 방지하기 위해 적당히 크기도 줄이고, 특정 Feature를 강조하기 위해 Convolution Layer(Conv) 사이에 Pooling Layer(Pool)가 사이사이에 배치하고 있습니다.
Max Pooling은 Convolution Filter를 거친 결과로 얻은 각각의 Feature Map에서 특정 영역을 형성하여 해당 영역 내에서 가장 큰 값을 도출하는 것입니다.
최대 풀링 이외에도, 평균 풀링, 가중치 평균 풀링, L2 놈 풀링 등이 있습니다. 이러한 풀링 연산은 잡음뿐 아니라 지나치게 상세한 정보를 포함한 특징 맵에서 요약통계(summary statistic)를 추출함으로써 성능 향상에 기여할 수 있습니다. 게다가 특징 맵이 작아지므로 속도 향상과 메모리 효율에도 기여합니다.
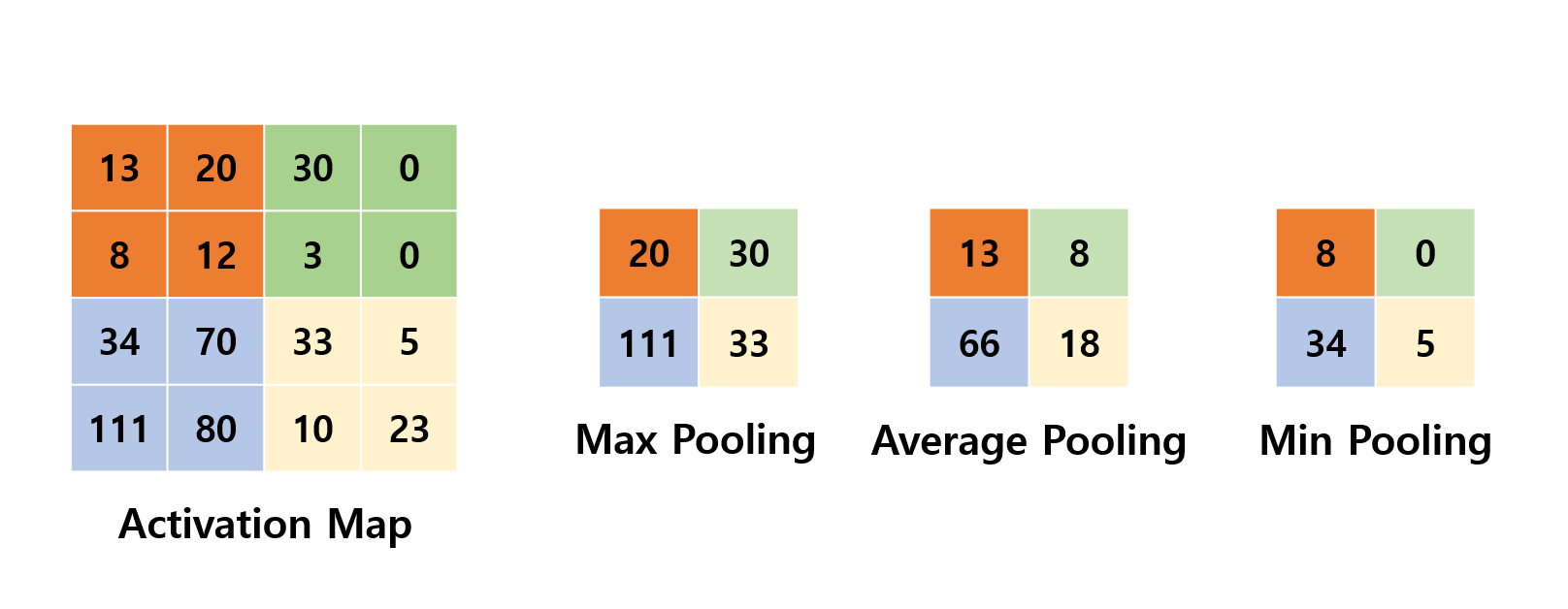

위 그림처럼 Polling 연산을 통해 형태는 유지하면서 기존의 이미지 크기를 작게 만들 수 있습니다.
그런데 왜 이런 Down Sampling을 통해 이미지를 작게 만드는 것일까요?
First Convolution Layer에서의 Convolution Filter(3*3)는 이미지의 Edge 정보만 추출합니다.
그 후 Pooling을 통해 이미지의 사이가 줄어들지만 Convolution Filter(3*3)의 크기는 그대로 유지됩니다.
그렇기 때문에 Edge 정보가 아니라 조금 더 abstarct(추상적)한 정보를 볼 수 있는 Convolution Filter를 갖게 됩니다.
즉, Pooling Layer 때문에 CNN은 Layer가 깊으면 깊어질수록 좀 더 abstract feature를 추출할 수 있게 됩니다.
Architecture (구조) > 조금 더 확인 해 볼 것
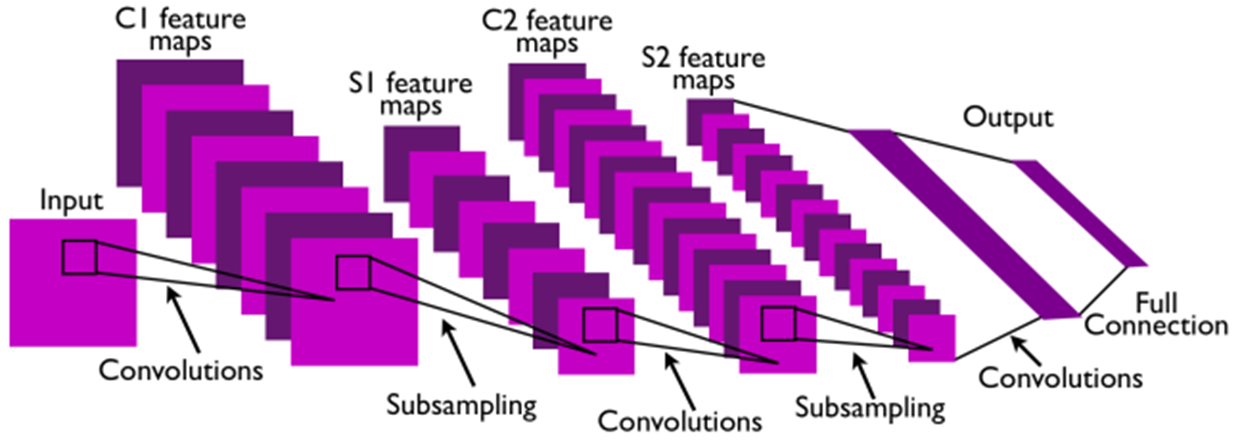
위 그림을 통해 전체적인 구조를 파악해 보겠습니다.
첫 번째 Convolution Layer를 보면 8개의 Convolution Filter를 통해 8개의 C1 Feature Map이 만들어 집니다.
그 후 Pooling(Subsampling)을 통하여 8개의 C1 Feature Map Size가 줄어들어 8개의 S1 Feature Map이 됩니다.
두 번째 Convolution Layer에서는 16개의 Convolution Filter가 사용되었습니다.
(첫 번째 Convolution Layer에서 사용된 Convolution Filter 보다는 좀 더 abstract한 Convolution Filter 모양일 것입니다.)
두 번째 Convolution Filter 하나가 사용될 때에는 이전 Convolution Layer → Pooling Layer를 통해 얻은 8개의 S1 Feature Map에 동시에 적용됩니다.
이렇게 되면 각 S1 Feature Map을 합산한 하나의 C2 Feature Map이 만들어 질 것이고, 합산한 C2 Feature Map에 두 번째 Convolution Layer에 있는 16개의 Convolution Filter들을 적용해서 또 다른 16개의 C2 Feature Map을 만들게 됩니다.
FC Layer
위 과정을 거치면 마지막에는 물체와 유사한 형태들의 Feature Map들이 선별 됩니다.
결국 물체와 유사한 Feature Map을 통해 Classification(분류)를 하게 되는데, 이때 사용되는 개념이 FC Layer 입니다.
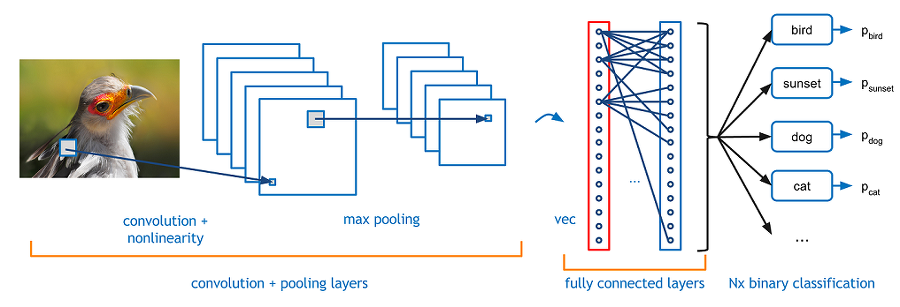
이 구조는 Deep Neural Netwrok 구조와 같습니다.
앞에서 Convolution Filter를 통해 시각 정보를 최대한 보전하여 마지막 Feature Map들을 일렬로 늘린 후, 이들을 DNN과 같이 입력 차원으로 받아 하나의 Hidden Layer를 거쳐 Classification(분류) 문제를 해결합니다.
Parameters
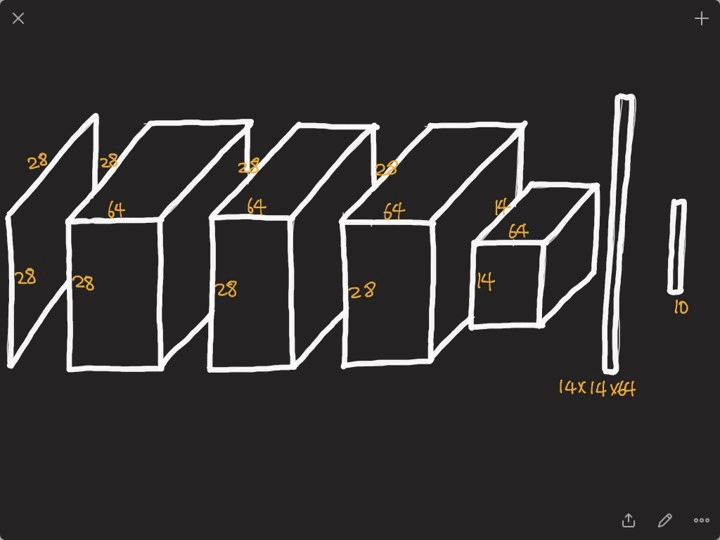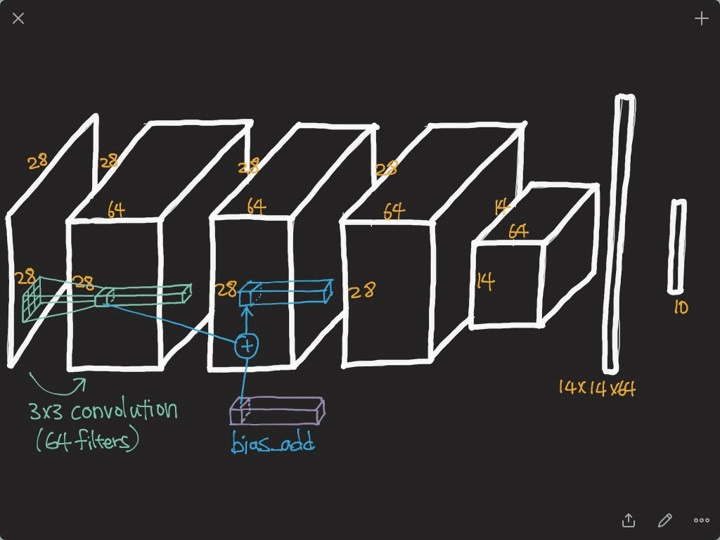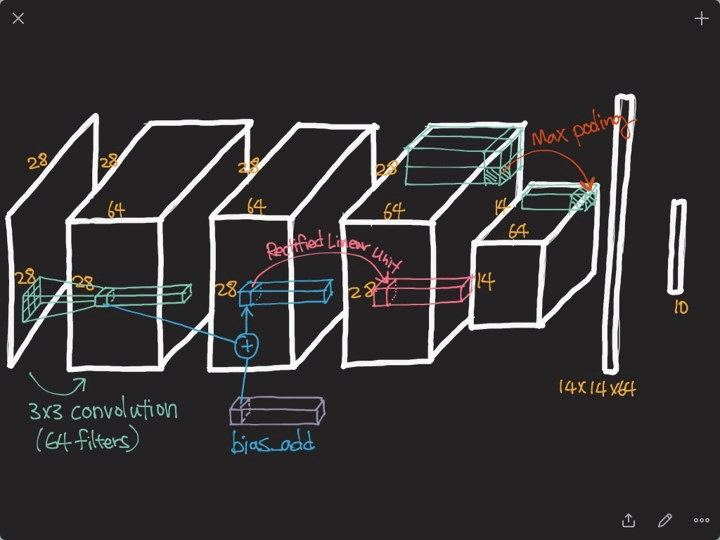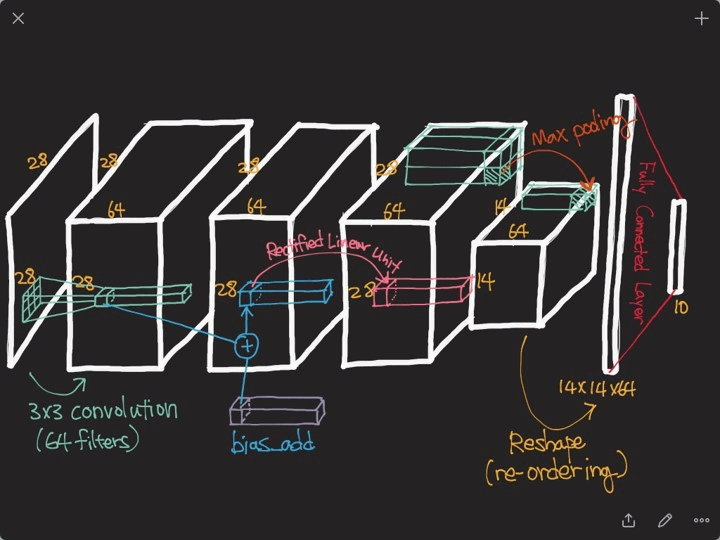

Convolution 연산을 하기 위해서는 파라미터의 수를 계산 하는 방법을 익혀야 합니다.
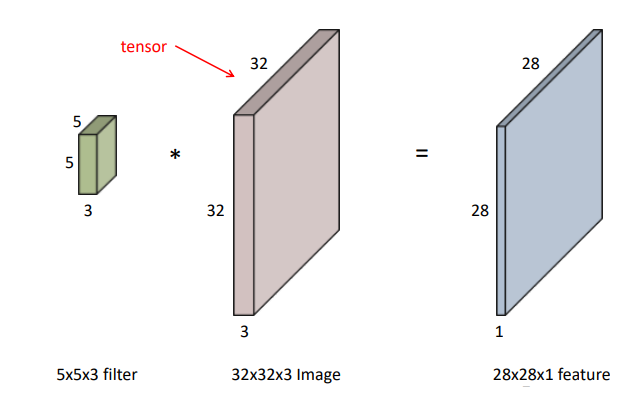
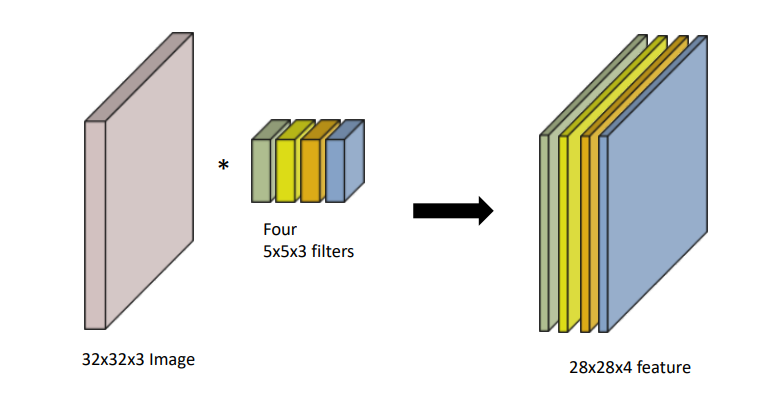
기본적으로 위 그림의 왼쪽처럼 (5 * 5 * 3)의 필터를 (32 * 32 * 3)의 이미지와 Convolution 연산을 하게 되면 (28 * 28 * 1) 피쳐가 나오게 됩니다.
만약 (28 * 28 * 4)의 피쳐를 추출하고 싶다면, (5 * 5 * 3)의 필터를 4개를 사용하여 구할 수 있습니다.
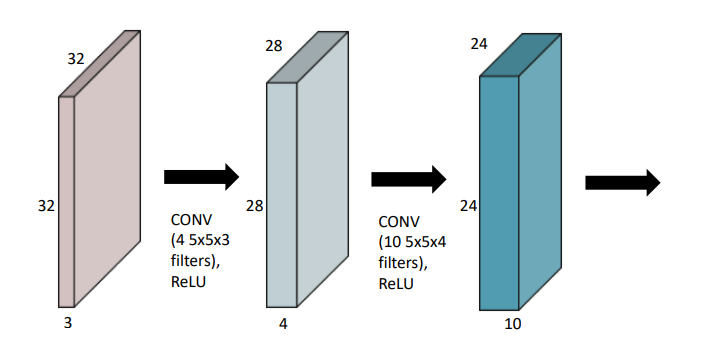
따라서 위 그림의 2번째 블럭을 연산하기 위해 필요한 파라미터 수는 (5 * 5 * 3 * 4), 3번째 블럭을 연산하기 위해 필요한 파라미터 수는 (5 * 5 * 4 * 10)이 됩니다. 이러한 방식을 사용하여 여러 모델의 파라미터 수를 구할 수 있습니다.
참조 사이트
https://excelsior-cjh.tistory.com/79
합성곱신경망(CNN, Convolutional Neural Network)
CNN에 대해 더 자세한 내용은 아래의 링크를 참고하시면 됩니다. 자세한 설명 : 06. 합성곱 신경망 - Convolutional Neural Networks 텐서플로 실습 위주 : [러닝 텐서플로]Chap04 - 합성곱 신경망 CNN 1. Convolu..
excelsior-cjh.tistory.com
https://89douner.tistory.com/57?category=873854
3. CNN(Convolution Neural Network)는 어떤 구조인가요?
안녕하세요~ 이번글에서는 Convolution Neural Network(CNN)의 기본구조에 대해서 알아보도록 할거에요. CNN은 기본적으로 Convolution layer-Pooling layer-FC layer 순서로 진행이 되기 때문에 이에 대해서 차..
89douner.tistory.com
CNN, Convolutional Neural Network 요약
Convolutional Neural Network, CNN을 정리합니다.
taewan.kim
'ML & DL > 기초 이론' 카테고리의 다른 글
| Probability Model(확률 모형), Random Variable(확률 변수) (0) | 2023.03.22 |
|---|---|
| Regularization: Overfitting을 해결하는 방법들 (0) | 2023.03.21 |
| Overfitting & Underfitting (0) | 2023.03.21 |
| Gradient Descent & Optimizer(SGD, Momentum, Adagrad, RMSprop, Adam) (0) | 2023.03.20 |
| Neural Network & Linear Neural Networks & Multi Layer Perceptron (0) | 2023.03.20 |
잘못된 부분이 있다면 언제든지 알려주시면 감사하겠습니다 !
NOTION 정리
https://repeated-canvas-49b.notion.site/CNN-4b6279ec256d4b22a27ce0c85c6e65b5
CNN
Convolution Neural Network
repeated-canvas-49b.notion.site
CNN (Convolution Neural Network)
CNN은 DNN의 한계인 차원의 저주(curse of dimensionality)를 해결하기 위해 이미지의 공간 정보를 유지한 채 학습을 하는 모델입니다.
Convolutions와 Subsampling의 중요한 부분은 특징 추출(feature extraction)입니다.
여기서 추출한 특징을 바탕으로 연결한 Fully Connected Layer의 중요한 부분은 Classification(분류) 입니다.
CNN의 장점으로 Local Invariance(국소적으로 비슷하다) 가 있습니다. 그 이유는 Convolution filters가 전체 이미지를 모두 돌아 다니는(sliding) 방법 때문입니다.
Convolution Layer
앞서 설명한 CNN의 핵심 부분으로 Convolution Layer에서 이미지를 Classification(분류) 하는데 필요한 Feature(특징) 정보들을 뽑아냅니다.
다음은 Convolution Filter가 Convolution을 통해 어떻게 Feature Map을 구성하는지 간단하게 나타낸 것입니다.
1. Convolution Filter(=Kernel=Window)를 일정한 간격으로 Stride(이동) 하며 Image에 적용 후 Filter에서 대응하는 원소끼리 곱한 후 그 총합을 구합니다. ( \(h\)는 커널의 크기, \(u\)는 커널, \(z\)는 입력, \(s\)는 출력 )
2. 이러한 Filter가 전체 이미지를 순회하고 나면 전체 이미지에서 해당 Filter와 유사한 모양을 가진 부분에 대한 Feature(특징) 을 얻을 수 있습니다.
\(\rightarrow\) 이러한 과정을 통해 “특정 Filter에 부합하는 Feature(특징) 정보를 얻었다.” 라고 말할 수 있습니다.
입력 Image의 채널이 여러 채널일 경우 필터는 각 채널을 순회하며 Convolution을 계산한 후, 각 채널의 Feature Map을 합산하여 최종 Feature Map 으로 반환합니다.
\(\rightarrow\) 하나의 Convolution Layer에 크기가 같은 여러 개의 Filter를 적용할 수 있습니다. 이 경우 Feature Map에 Filter 개수만큼 채널이 만들어집니다.
1. First Convolution Layer
CNN에서 물체의 윤곽을 알아내기 위해 제일 처음 하는 작업은 Edge Filter 입니다.
Convolution Filter는 모든 Layer에서 같은 크기로 고정되어 있습니다. 그렇기 때문에 Input Image 크기는 Convolution Filter 크기에 비해 상대적으로 크기 때문에 Filter가 이미지를 구분할 수 있는 부분이 선과 같은 단순한 정보(edge)입니다.
결과적으로 우리가 n개의 Filter를 사용하면 Convolution Layer 에서는 n개의 결과 값들이 나오게 되는데 이를 Feature Map 이라고 부릅니다.
처음에는 Convolution Filter 역시 초기 값 설정을 통해 Random 으로 분포하게 되지만 학습을 통해서 완성된 Edge Filter로 만들어지게 됩니다.
2. Padding
Padding(패딩)은 주로 출력 크기가 줄어드는 것을 방지하기 위해 사용됩니다.
예를 들어 다음과 같이 (5, 5)의 Image에 (3, 3)의 필터를 적용하면 출력은 (3, 3)이 되어 입력보다 2만큼 줄어들게 됩니다.
이를 몇 번 되풀이하면 출력 크기가 1이 되어 문제가 될 수 있습니다.
이를 해결하기 위해 Padding은 입력 데이터의 외각에 지정된 픽셀만큼 특정 값(0)을 채워 넣습니다.
3. 출력 크기 계산
Padding과 Stride를 적용하고, 입력 Image와 Filter의 크기가 주어졌을 때 출력 데이터의 크기를 구하는 식은 다음과 같다.
출력 크기가 정수가 아닌 경우에는 에러가 발생할 수 있으니 주의가 필요하다.
Pooling Layer (Subsampling)
이미지의 크기를 계속 유지한 채 Fully Connected Layer로 가게 된다면 연산량이 기하급수적으로 늘어납니다.
이를 방지하기 위해 적당히 크기도 줄이고, 특정 Feature를 강조하기 위해 Convolution Layer(Conv) 사이에 Pooling Layer(Pool)가 사이사이에 배치하고 있습니다.
Max Pooling은 Convolution Filter를 거친 결과로 얻은 각각의 Feature Map에서 특정 영역을 형성하여 해당 영역 내에서 가장 큰 값을 도출하는 것입니다.
최대 풀링 이외에도, 평균 풀링, 가중치 평균 풀링, L2 놈 풀링 등이 있습니다. 이러한 풀링 연산은 잡음뿐 아니라 지나치게 상세한 정보를 포함한 특징 맵에서 요약통계(summary statistic)를 추출함으로써 성능 향상에 기여할 수 있습니다. 게다가 특징 맵이 작아지므로 속도 향상과 메모리 효율에도 기여합니다.
위 그림처럼 Polling 연산을 통해 형태는 유지하면서 기존의 이미지 크기를 작게 만들 수 있습니다.
그런데 왜 이런 Down Sampling을 통해 이미지를 작게 만드는 것일까요?
First Convolution Layer에서의 Convolution Filter(3*3)는 이미지의 Edge 정보만 추출합니다.
그 후 Pooling을 통해 이미지의 사이가 줄어들지만 Convolution Filter(3*3)의 크기는 그대로 유지됩니다.
그렇기 때문에 Edge 정보가 아니라 조금 더 abstarct(추상적)한 정보를 볼 수 있는 Convolution Filter를 갖게 됩니다.
즉, Pooling Layer 때문에 CNN은 Layer가 깊으면 깊어질수록 좀 더 abstract feature를 추출할 수 있게 됩니다.
Architecture (구조) > 조금 더 확인 해 볼 것
위 그림을 통해 전체적인 구조를 파악해 보겠습니다.
첫 번째 Convolution Layer를 보면 8개의 Convolution Filter를 통해 8개의 C1 Feature Map이 만들어 집니다.
그 후 Pooling(Subsampling)을 통하여 8개의 C1 Feature Map Size가 줄어들어 8개의 S1 Feature Map이 됩니다.
두 번째 Convolution Layer에서는 16개의 Convolution Filter가 사용되었습니다.
(첫 번째 Convolution Layer에서 사용된 Convolution Filter 보다는 좀 더 abstract한 Convolution Filter 모양일 것입니다.)
두 번째 Convolution Filter 하나가 사용될 때에는 이전 Convolution Layer → Pooling Layer를 통해 얻은 8개의 S1 Feature Map에 동시에 적용됩니다.
이렇게 되면 각 S1 Feature Map을 합산한 하나의 C2 Feature Map이 만들어 질 것이고, 합산한 C2 Feature Map에 두 번째 Convolution Layer에 있는 16개의 Convolution Filter들을 적용해서 또 다른 16개의 C2 Feature Map을 만들게 됩니다.
FC Layer
위 과정을 거치면 마지막에는 물체와 유사한 형태들의 Feature Map들이 선별 됩니다.
결국 물체와 유사한 Feature Map을 통해 Classification(분류)를 하게 되는데, 이때 사용되는 개념이 FC Layer 입니다.
이 구조는 Deep Neural Netwrok 구조와 같습니다.
앞에서 Convolution Filter를 통해 시각 정보를 최대한 보전하여 마지막 Feature Map들을 일렬로 늘린 후, 이들을 DNN과 같이 입력 차원으로 받아 하나의 Hidden Layer를 거쳐 Classification(분류) 문제를 해결합니다.
Parameters
Convolution 연산을 하기 위해서는 파라미터의 수를 계산 하는 방법을 익혀야 합니다.
기본적으로 위 그림의 왼쪽처럼 (5 * 5 * 3)의 필터를 (32 * 32 * 3)의 이미지와 Convolution 연산을 하게 되면 (28 * 28 * 1) 피쳐가 나오게 됩니다.
만약 (28 * 28 * 4)의 피쳐를 추출하고 싶다면, (5 * 5 * 3)의 필터를 4개를 사용하여 구할 수 있습니다.
따라서 위 그림의 2번째 블럭을 연산하기 위해 필요한 파라미터 수는 (5 * 5 * 3 * 4), 3번째 블럭을 연산하기 위해 필요한 파라미터 수는 (5 * 5 * 4 * 10)이 됩니다. 이러한 방식을 사용하여 여러 모델의 파라미터 수를 구할 수 있습니다.
참조 사이트
https://excelsior-cjh.tistory.com/79
합성곱신경망(CNN, Convolutional Neural Network)
CNN에 대해 더 자세한 내용은 아래의 링크를 참고하시면 됩니다. 자세한 설명 : 06. 합성곱 신경망 - Convolutional Neural Networks 텐서플로 실습 위주 : [러닝 텐서플로]Chap04 - 합성곱 신경망 CNN 1. Convolu..
excelsior-cjh.tistory.com
https://89douner.tistory.com/57?category=873854
3. CNN(Convolution Neural Network)는 어떤 구조인가요?
안녕하세요~ 이번글에서는 Convolution Neural Network(CNN)의 기본구조에 대해서 알아보도록 할거에요. CNN은 기본적으로 Convolution layer-Pooling layer-FC layer 순서로 진행이 되기 때문에 이에 대해서 차..
89douner.tistory.com
CNN, Convolutional Neural Network 요약
Convolutional Neural Network, CNN을 정리합니다.
taewan.kim
'ML & DL > 기초 이론' 카테고리의 다른 글
| Probability Model(확률 모형), Random Variable(확률 변수) (0) | 2023.03.22 |
|---|---|
| Regularization: Overfitting을 해결하는 방법들 (0) | 2023.03.21 |
| Overfitting & Underfitting (0) | 2023.03.21 |
| Gradient Descent & Optimizer(SGD, Momentum, Adagrad, RMSprop, Adam) (0) | 2023.03.20 |
| Neural Network & Linear Neural Networks & Multi Layer Perceptron (0) | 2023.03.20 |