
YOLO v1
해당 논문이 발표되기 이전에는 2 stage object detection 방법이 일반적이였습니다. 2 stage object detection은 각각의 stage를 순차적으로 처리하기 때문에 속도가 느리다는 단점이 있었습니다. YOLO v1은 이를 통합한 1 stage object detection 방법을 제안하며 더욱 빠른 처리 속도를 제공합니다.
Preview
2 stage object detection
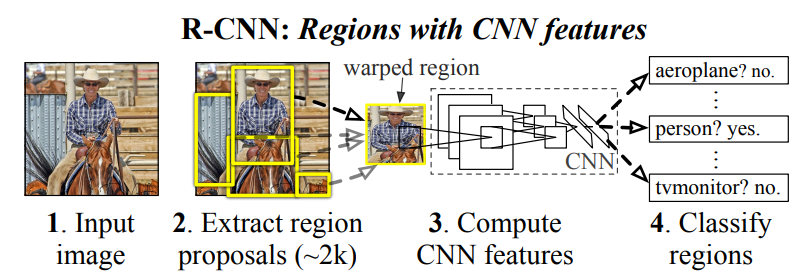
YOLO v1이 나오기 이전 R-CNN과 같은 기존의 object detection 모델은 2 stage로 동작했습니다.
첫 번째로, 입력 이미지를 Region Proposal 과정을 거쳐 "물체가 있을 법한" 위치를 찾아냅니다.
두 번째로, 찾아낸 이미지들을 CNN에 넣어 Feature를 추출한 뒤 어떤 클래스인지를 추론합니다.
이 방식은 Region Proposal 단계와 Feature Extraction 2 단계로 구성되어 있어 2 stage라 불리고, 각각의 단계에서 시간을 소비하기 때문에 필연적으로 속도가 느려질 수 밖에 없습니다.
1stage object detection
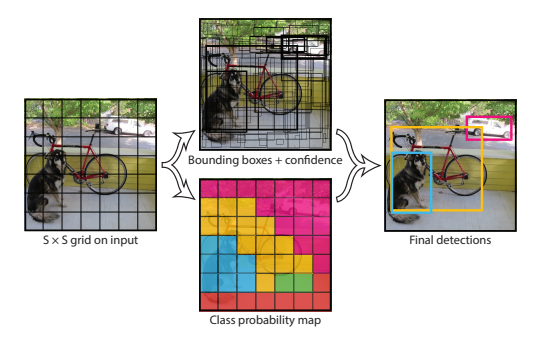
그래서 논문 저자들은 이 2 단계를 통합한 1 stage object detection 방법을 고민했고, 입력 이미지로부터 바로 CNN을 사용하여 Feature를 추출한 뒤 Detection에 필요한 정보를 추론하도록 하여 해결하였습니다. 이를 You Only Look Once, YOLO라 칭하였습니다.
Details

YOLO v1은 region proposals를 사용하지 않고 전체 이미지를 입력으로 사용합니다. 가장 먼저 전체 이미지를 SxS 크기의 Grid로 나눠줍니다. 여기서 객체의 중심이 특정 grid cell에 위치한다면, 해당 grid cell은 그 객체를 detect 하도록 할당(responsible for)됩니다. 이는 곧 나머지 grid cell은 객체를 예측하는데 참여할 수 없음을 의미합니다.
각각의 grid cell은 B개의 bounding box와 해당 bounding box에 대한 confidence score를 예측합니다. 여기서 confidence score는 해당 bounding box에 객체가 포함되어 있는지에 대한 여부와, box가 얼마나 정확하게 ground truth box를 예측했는지를 나타내는 수치입니다. confidence score는 \(Pr(Object) * IoU(pred,truth)\)로 정의합니다.

각각의 bounding box는 box의 좌표 정보(x, y, w, h)와 confidence score를 포함하여 총 5개의 예측값을 가집니다. (x, y)는 gird cell의 경계에 비례한 box의 중심 좌표를 의미합니다. x, y는 grid cell 내에 위치하기에 0~1 사이의 값을 가지지만 객체의 크기가 gride cell의 크기보다 더 클 수 있기 때문에 w, h는 1 이상의 값을 가질 수 있습니다.
하나의 bounding box는 하나의 객체만을 예측하며, 하나의 grid cell은 하나의 bounding box를 학습에 사용합니다. 예를 들어, 각 grid cell 별로 B개의 bounding box를 예측한다고 할 때, confidence가 가장 높은 1개의 bounding box만 학습에 사용합니다.
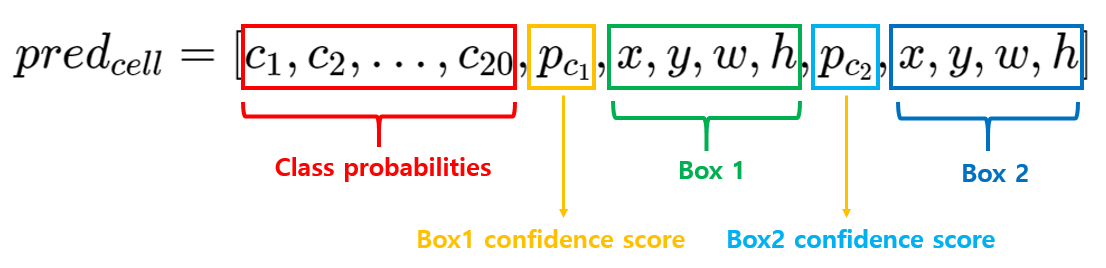
각 gride cell은 C개의 conditional class probabilities인 \(Pr(Class_i|Object)\)를 예측합니다. 이는 특정 grid cell에 객체가 존재한다고 가정했을 때, 특정 class(i)일 확률인 조건부 확률입니다. bounding box 수와 상관없이 하나의 grid cell마다 하나의 조건부 확률을 예측합니다. 중요한 점은 bounding box 별로 class probabilities를 예측하는 것이 아니라, grid cell 별로 예측하는 것 입니다.
해당 논문에서는 S=7, B=2, C=20 으로 설정하였습니다. 즉, 이미지를 7x7 grid로 나누고 각 grid cell은 2개의 bounding box와 해당 box의 confidence score, 그리고 C개의 class probabilities를 예측합니다. 즉 이미지별 예측값의 크기는 7x7x(2x5+20) 입니다.
DarkNet
YOLO v1은 최종 예측값인 7x7x30에 맞는 feature map을 생성하기 위해 DarkNet이라는 독자적인 Convolutional Network를 설계합니다.
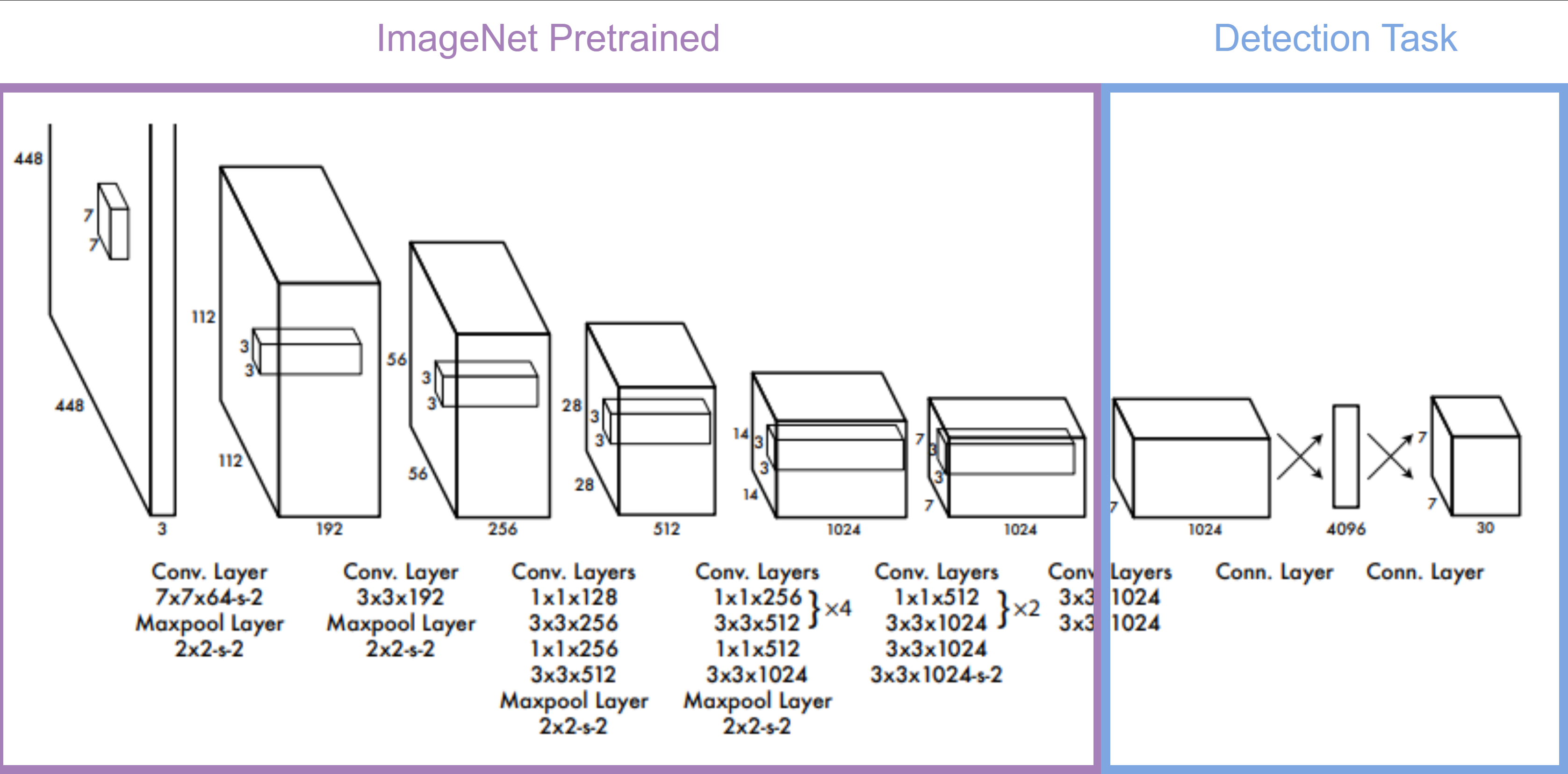
DarkNet의 전체적인 구성은 GoogLeNet을 따랐습니다. 그리고 GoogLeNet으로 ImageNet Calssification을 학습했습니다. 이유는, Object Detection 데이터셋은 양이 적어 ImageNet의 풍부한 Feature를 활용하는 것이 더 유리하기 때문입니다. 이 Pretrained된 모델 뒤에 Conv Layer와 FC Layer를 추가하여 Object Detection 데이터셋을 학습했습니다.
이렇게 추가된 Layer의 파라미터는 모두 Random Initialization 해주었고, 더 작은 물체도 찾을 수 있도록 Resolution을 224x224에서 448x448로 확대하여 학습했습니다.
Loss Function

YOLO v1은 regression 시 주로 사용되는 SSE(Sum of Squared Error)를 사용합니다.
Localization Loss
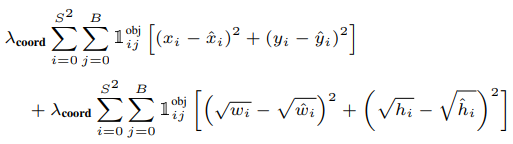
x, y, w, h 의 예측값에 대해 매칭되는 Ground Truth 값들과 같아지도록 구성되어 있습니다.
\(\lambda_{coord}\)는 Localization에 대한 가중치 입니다. 최종 Loss는 Localization Loss와 Confidence Loss, Classification Loss의 합으로 구성될 것입니다. 이렇게 되면 Localization Loss와 Classification Loss는 동등한 중요도를 가지게 됩니다. 하지만 우리가 풀려고 하는 문제는 Object Detection 문제이기 때문에 Localization Loss에 더 큰 가중치를 줘야 합니다. 따라서 YOLO v1에서는 \(\lambda_{coord}\)의 값을 5로 설정하여 Localization Loss의 비율을 더 크게 설정했습니다.
각 feature 마다 두 개의 bounding box를 예측하는데, 두 개의 box는 위치가 겹칠 가능성이 매우 높습니다. 따라서 𝟙 \(^{obj}_{i,j}\)는 이 두 개의 box 중 IoU가 더 큰 box에만 Loss를 할당해주는 역할을 합니다. 이를 resposible 하다고 표현하고 수식으로는 𝟙 \(^{obj}_{i,j}\) 으로 표현합니다.
Confidence Loss
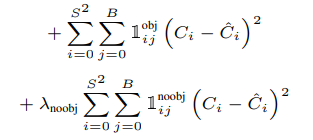
예측한 confidence의 값이 Ground Truth와 계산한 IoU와 같아지도록 구성되어 있습니다.
대부분의 box에는 object가 없을 것 입니다. 따라서 대부분의 confidence는 0이 되도록 학습해야 합니다. 하지만, 이렇게 되면 아주 소수의 object에 해당하는 confidence도 영향을 받아 학습이 안될 수도 있습니다. 따라서 object가 없는 box의 confidence에서 나오는 loss는 적은 가중치를 적용해줘야 합니다. 이에 해당하는 값이 \(\lambda_{noobj}\)입니다. YOLO v1에서는 이 값을 0.5로 세팅하였습니다.
Classification Loss
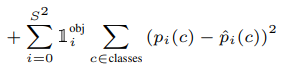
각 확률 값이 해당하는 클래스의 정답 확률값과 같아지도록 구성되어 있습니다.
Inference
학습 과정에서는 각 Feature 마다 2개의 bounding box를 예측하여 Ground Truth와의 IoU가 큰 box만 학습되도록 했습니다. 하지만 추론 과정에서는 2개의 box 중 무엇을 지워야 할 지 모르는 문제가 있습니다.
YOLO v1에서는 일단 2개씩 예측하여 NMS(Non Maximum Suppresion) 방법을 사용하여 겹치는 box를 제거해 줍니다.

1. 위 그림과 같이 각 grid 별로 예측한 수 많은 bounding box 중에서 특정 confidence 값 이하의 bounding box는 모두 제거합니다.
2. 가장 높은 confidence 값을 가진 순으로 box를 정렬합니다.
3. 가장 높은 confidence를 가진 bounding box와 IoU가 겹치는 부분이 IoU Threshold 보다 큰 bounding box는 모두 제거합니다.
4. 남아 있는 bounding box에 대해 3번 step을 반복합니다.
Conclusions
장점
- 빠른 처리속도를 가져 실시간으로 사용하기 적합합니다.
- 기존의 Region Proposal 방식과 달리 이미지 전체의 Feature를 기준으로 판단하기 때문에 문맥을 고려할 수 있습니다.
- 일반화 성능이 뛰어납니다. (다른 데이터셋을 사용하여 학습 시켰을 때의 실험 결과로 확인)
단점
- 기존의 2 stage 방법들 보다 성능이 떨어집니다.
- 모여있거나 겹쳐있는 물체를 검출하는 성능이 떨어집니다. (grid 당 2개의 박스만 검출하도록 설계되었기 때문)
- 작은 박스에 대한 검출 성능이 떨어집니다. (박스 크기에 상관 없이 동일하게 0~1로 Normalization 된 값으로 Localization Loss를 설정했기 때문)
참고
[1] https://arxiv.org/pdf/1506.02640
[2] https://ffighting.net/deep-learning-paper-review/object-detection/yolo-v1/
[3] https://herbwood.tistory.com/13
'Paper Review' 카테고리의 다른 글
| [YOLO v2] YOLO9000: Better, Faster, Stronger (0) | 2024.07.19 |
|---|---|
| [SSD] Single Shot MultiBox Detector (0) | 2024.07.16 |
| [ViT] Vision Transformer, AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (0) | 2024.07.12 |
| [EfficientNet] Rethinking Model Scaling for Convolutional Neural Networks (0) | 2024.07.11 |
| [SENet] Squeeze and Excitation Networks (0) | 2024.07.10 |
YOLO v1
해당 논문이 발표되기 이전에는 2 stage object detection 방법이 일반적이였습니다. 2 stage object detection은 각각의 stage를 순차적으로 처리하기 때문에 속도가 느리다는 단점이 있었습니다. YOLO v1은 이를 통합한 1 stage object detection 방법을 제안하며 더욱 빠른 처리 속도를 제공합니다.
Preview
2 stage object detection
YOLO v1이 나오기 이전 R-CNN과 같은 기존의 object detection 모델은 2 stage로 동작했습니다.
첫 번째로, 입력 이미지를 Region Proposal 과정을 거쳐 "물체가 있을 법한" 위치를 찾아냅니다.
두 번째로, 찾아낸 이미지들을 CNN에 넣어 Feature를 추출한 뒤 어떤 클래스인지를 추론합니다.
이 방식은 Region Proposal 단계와 Feature Extraction 2 단계로 구성되어 있어 2 stage라 불리고, 각각의 단계에서 시간을 소비하기 때문에 필연적으로 속도가 느려질 수 밖에 없습니다.
1stage object detection
그래서 논문 저자들은 이 2 단계를 통합한 1 stage object detection 방법을 고민했고, 입력 이미지로부터 바로 CNN을 사용하여 Feature를 추출한 뒤 Detection에 필요한 정보를 추론하도록 하여 해결하였습니다. 이를 You Only Look Once, YOLO라 칭하였습니다.
Details
YOLO v1은 region proposals를 사용하지 않고 전체 이미지를 입력으로 사용합니다. 가장 먼저 전체 이미지를 SxS 크기의 Grid로 나눠줍니다. 여기서 객체의 중심이 특정 grid cell에 위치한다면, 해당 grid cell은 그 객체를 detect 하도록 할당(responsible for)됩니다. 이는 곧 나머지 grid cell은 객체를 예측하는데 참여할 수 없음을 의미합니다.
각각의 grid cell은 B개의 bounding box와 해당 bounding box에 대한 confidence score를 예측합니다. 여기서 confidence score는 해당 bounding box에 객체가 포함되어 있는지에 대한 여부와, box가 얼마나 정확하게 ground truth box를 예측했는지를 나타내는 수치입니다. confidence score는 Pr(Object)∗IoU(pred,truth)로 정의합니다.
각각의 bounding box는 box의 좌표 정보(x, y, w, h)와 confidence score를 포함하여 총 5개의 예측값을 가집니다. (x, y)는 gird cell의 경계에 비례한 box의 중심 좌표를 의미합니다. x, y는 grid cell 내에 위치하기에 0~1 사이의 값을 가지지만 객체의 크기가 gride cell의 크기보다 더 클 수 있기 때문에 w, h는 1 이상의 값을 가질 수 있습니다.
하나의 bounding box는 하나의 객체만을 예측하며, 하나의 grid cell은 하나의 bounding box를 학습에 사용합니다. 예를 들어, 각 grid cell 별로 B개의 bounding box를 예측한다고 할 때, confidence가 가장 높은 1개의 bounding box만 학습에 사용합니다.
각 gride cell은 C개의 conditional class probabilities인 Pr(Classi|Object)를 예측합니다. 이는 특정 grid cell에 객체가 존재한다고 가정했을 때, 특정 class(i)일 확률인 조건부 확률입니다. bounding box 수와 상관없이 하나의 grid cell마다 하나의 조건부 확률을 예측합니다. 중요한 점은 bounding box 별로 class probabilities를 예측하는 것이 아니라, grid cell 별로 예측하는 것 입니다.
해당 논문에서는 S=7, B=2, C=20 으로 설정하였습니다. 즉, 이미지를 7x7 grid로 나누고 각 grid cell은 2개의 bounding box와 해당 box의 confidence score, 그리고 C개의 class probabilities를 예측합니다. 즉 이미지별 예측값의 크기는 7x7x(2x5+20) 입니다.
DarkNet
YOLO v1은 최종 예측값인 7x7x30에 맞는 feature map을 생성하기 위해 DarkNet이라는 독자적인 Convolutional Network를 설계합니다.
DarkNet의 전체적인 구성은 GoogLeNet을 따랐습니다. 그리고 GoogLeNet으로 ImageNet Calssification을 학습했습니다. 이유는, Object Detection 데이터셋은 양이 적어 ImageNet의 풍부한 Feature를 활용하는 것이 더 유리하기 때문입니다. 이 Pretrained된 모델 뒤에 Conv Layer와 FC Layer를 추가하여 Object Detection 데이터셋을 학습했습니다.
이렇게 추가된 Layer의 파라미터는 모두 Random Initialization 해주었고, 더 작은 물체도 찾을 수 있도록 Resolution을 224x224에서 448x448로 확대하여 학습했습니다.
Loss Function
YOLO v1은 regression 시 주로 사용되는 SSE(Sum of Squared Error)를 사용합니다.
Localization Loss
x, y, w, h 의 예측값에 대해 매칭되는 Ground Truth 값들과 같아지도록 구성되어 있습니다.
λcoord는 Localization에 대한 가중치 입니다. 최종 Loss는 Localization Loss와 Confidence Loss, Classification Loss의 합으로 구성될 것입니다. 이렇게 되면 Localization Loss와 Classification Loss는 동등한 중요도를 가지게 됩니다. 하지만 우리가 풀려고 하는 문제는 Object Detection 문제이기 때문에 Localization Loss에 더 큰 가중치를 줘야 합니다. 따라서 YOLO v1에서는 λcoord의 값을 5로 설정하여 Localization Loss의 비율을 더 크게 설정했습니다.
각 feature 마다 두 개의 bounding box를 예측하는데, 두 개의 box는 위치가 겹칠 가능성이 매우 높습니다. 따라서 𝟙 obji,j는 이 두 개의 box 중 IoU가 더 큰 box에만 Loss를 할당해주는 역할을 합니다. 이를 resposible 하다고 표현하고 수식으로는 𝟙 obji,j 으로 표현합니다.
Confidence Loss
예측한 confidence의 값이 Ground Truth와 계산한 IoU와 같아지도록 구성되어 있습니다.
대부분의 box에는 object가 없을 것 입니다. 따라서 대부분의 confidence는 0이 되도록 학습해야 합니다. 하지만, 이렇게 되면 아주 소수의 object에 해당하는 confidence도 영향을 받아 학습이 안될 수도 있습니다. 따라서 object가 없는 box의 confidence에서 나오는 loss는 적은 가중치를 적용해줘야 합니다. 이에 해당하는 값이 λnoobj입니다. YOLO v1에서는 이 값을 0.5로 세팅하였습니다.
Classification Loss
각 확률 값이 해당하는 클래스의 정답 확률값과 같아지도록 구성되어 있습니다.
Inference
학습 과정에서는 각 Feature 마다 2개의 bounding box를 예측하여 Ground Truth와의 IoU가 큰 box만 학습되도록 했습니다. 하지만 추론 과정에서는 2개의 box 중 무엇을 지워야 할 지 모르는 문제가 있습니다.
YOLO v1에서는 일단 2개씩 예측하여 NMS(Non Maximum Suppresion) 방법을 사용하여 겹치는 box를 제거해 줍니다.
1. 위 그림과 같이 각 grid 별로 예측한 수 많은 bounding box 중에서 특정 confidence 값 이하의 bounding box는 모두 제거합니다.
2. 가장 높은 confidence 값을 가진 순으로 box를 정렬합니다.
3. 가장 높은 confidence를 가진 bounding box와 IoU가 겹치는 부분이 IoU Threshold 보다 큰 bounding box는 모두 제거합니다.
4. 남아 있는 bounding box에 대해 3번 step을 반복합니다.
Conclusions
장점
- 빠른 처리속도를 가져 실시간으로 사용하기 적합합니다.
- 기존의 Region Proposal 방식과 달리 이미지 전체의 Feature를 기준으로 판단하기 때문에 문맥을 고려할 수 있습니다.
- 일반화 성능이 뛰어납니다. (다른 데이터셋을 사용하여 학습 시켰을 때의 실험 결과로 확인)
단점
- 기존의 2 stage 방법들 보다 성능이 떨어집니다.
- 모여있거나 겹쳐있는 물체를 검출하는 성능이 떨어집니다. (grid 당 2개의 박스만 검출하도록 설계되었기 때문)
- 작은 박스에 대한 검출 성능이 떨어집니다. (박스 크기에 상관 없이 동일하게 0~1로 Normalization 된 값으로 Localization Loss를 설정했기 때문)
참고
[1] https://arxiv.org/pdf/1506.02640
[2] https://ffighting.net/deep-learning-paper-review/object-detection/yolo-v1/
[3] https://herbwood.tistory.com/13
'Paper Review' 카테고리의 다른 글
| [YOLO v2] YOLO9000: Better, Faster, Stronger (0) | 2024.07.19 |
|---|---|
| [SSD] Single Shot MultiBox Detector (0) | 2024.07.16 |
| [ViT] Vision Transformer, AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (0) | 2024.07.12 |
| [EfficientNet] Rethinking Model Scaling for Convolutional Neural Networks (0) | 2024.07.11 |
| [SENet] Squeeze and Excitation Networks (0) | 2024.07.10 |