
GAN History
[paper]

GAN (Generative Adversarial Nets)은 위와 같이 진짜와 동일해 보이는 이미지(노란색 박스)를 생성하는 모델입니다.
2014년 arXive 논문 발표 이후, 다음 그림과 같이 후속 연구들이 계속해서 이어지고 있는 것을 확인할 수 있습니다.
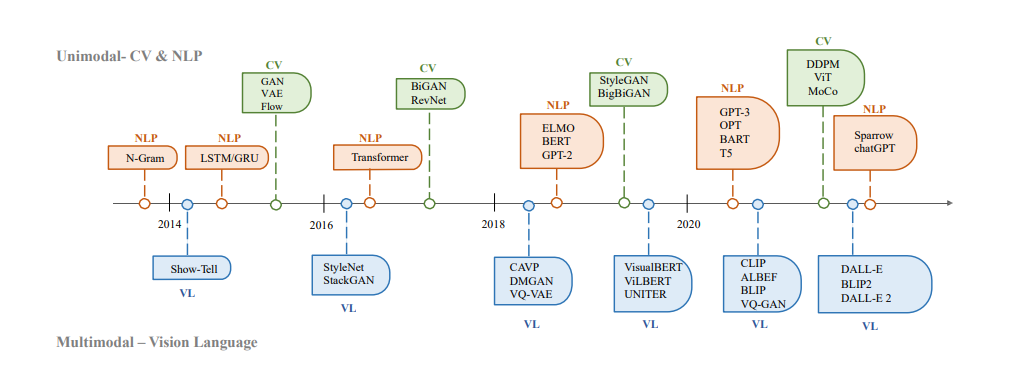
이 포스트에선 GAN부터 시작하여 다양하게 발전한 GAN들을 하나씩 간단하게 살펴보기 위해 작성합니다.
Original GAN
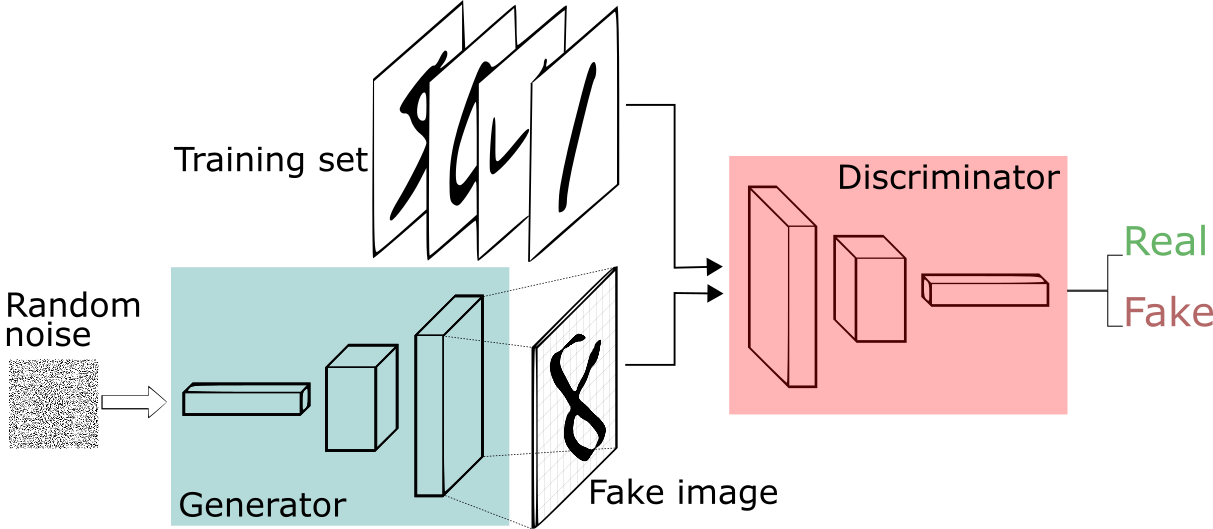
GAN은 서로 다른 두 개의 모델 Generator(생성기)와 Discriminator(판별기)를 적대적으로(Adversarial) 학습시키며 실제 데이터와 비슷한 데이터를 생성합니다.
생성기는 실제(Real) 데이터의 분포를 학습하여 비슷한(Fake) 데이터를 생성하는 모델이며, 판별기는 실제 데이터인지 생성된 비슷한 데이터인지를 구별하는 역할을 합니다.
GAN의 목표는 "실제 데이터의 분포"에 가까운 비슷한 데이터를 생성하는 것이며 이를 판별하지 못하는 경계(0을 가짜 1을 진짜로 하였을 때 0.5)를 만드는 것 입니다.
GAN의 학습 과정
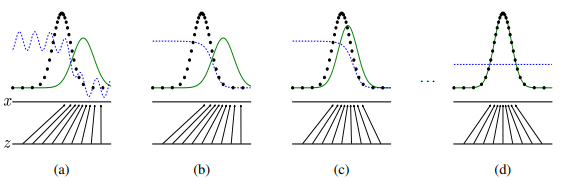
검은 점선 : 실제 데이터의 확률 분포 / 녹색 실선 : 생성기가 만들어낸 데이터의 확률 분포 / 파란 점선 : 판별기의 확률 분포
위 그림처럼 서로 경쟁하면서 학습함으로써, 실제 데이터의 확률 분포와 생성기가 만들어낸 데이터의 확률 분포의 차이가 줄어들어 실제 이미지와 같아지는 원리이다.
따라서 (d)의 단계에서 생성기는 실제 데이터와 매우 흡사하게 이미지를 생성한다는 의미이다.
GAN의 수식
$$ \underset{G}{min} \underset{D}{max} V(D,G) = \mathbb{E}_{x \sim Pdata(x)}[logD(x)] + \mathbb{E}_{z \sim Pz(z)}[log(1-D(G(z)))] $$
G :Generator / D : Discriminator / x : real data 분포 / z : fake data 분포
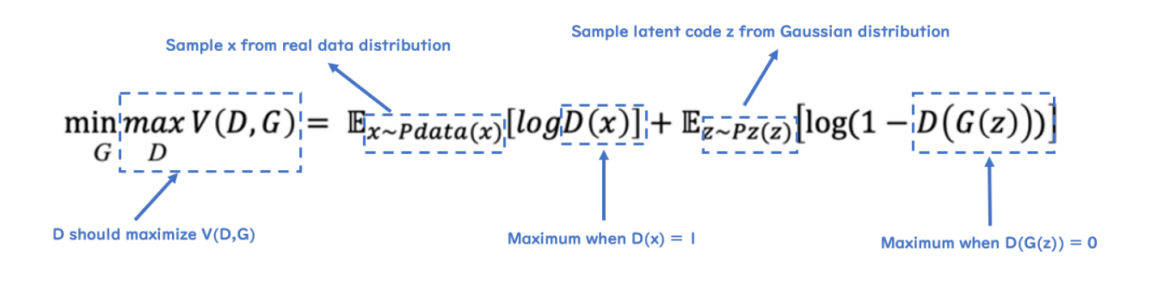
\(V(D,G)\)는 GAN의 Loss 함수, 목적 함수(Object Function)라고 불립니다.
0을 가짜 데이터 1을 실제 데이터라 하였을 때, \(D\)의 목적은 \(D(x)\)를 최대한 1에 가깝게 만들고, \(D(G(z))\)를 최대한 0에 가깝게 만듦으로써 목적 함수를 최대화 하는 것을 목적으로 합니다. 즉, 가짜 데이터에는 0을 출력하고 실제 데이터에는 1을 출력하도록 하는 것이다.
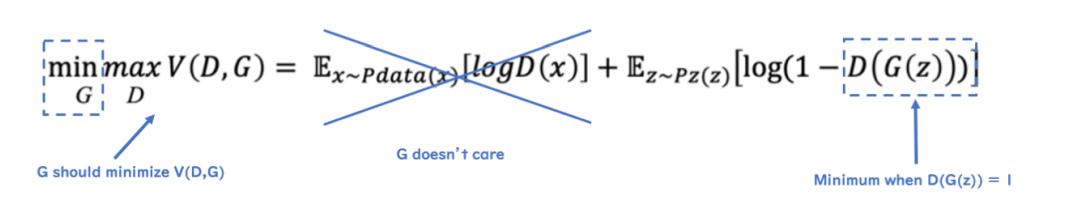
\(G\)는 \(D(G(z))\)를 최대한 1에 가깝게 만들어 목적 함수를 최소화하는 것을 목적으로 합니다. 즉, \(D\)가 가짜 데이터를 1로 분류하도록 속일 수 있는, 최대한 실제와 가까운 가짜 데이터를 만드는 방향으로 학습하는 것 입니다.
하지만, 위 목적 함수를 활용해서 GAN을 학습하면 실제로는 학습이 잘 되지 않는 경우가 있습니다. 이러한 이유는 \(G\)의 성능이 좋지 않을 때, 해당 목적 함수를 따르면 Gradient가 굉장히 작아서 학습이 빠르게 될 수 없기 때문입니다.
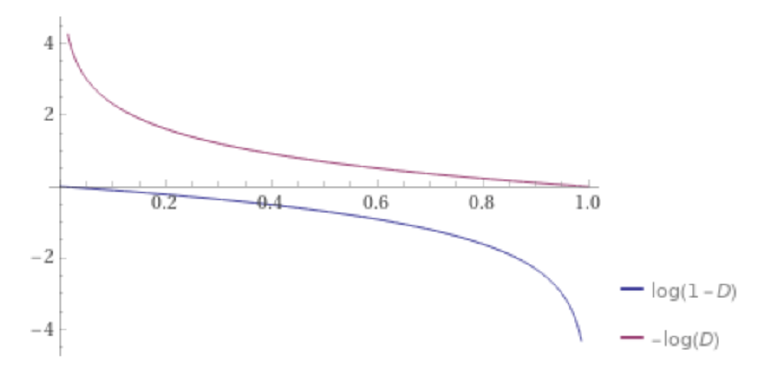
위 그래프에서 \(G\)에 해당하는 부분인 \(log(1-D(G(z)))\)에서 \(D(G(z))\)가 0에 가까울 때, Gradient가 0에 가깝기 때문에 학습이 잘 되지 않을 수 있는 것을 확인할 수 있습니다. 따라서 위의 \(G\) 목적 함수 대신에 \(-log(D(G(z)))\)를 활용합니다.
한계점
Mode-Collapse
: Generator와 Discriminator 중 하나가 너무 학습이 잘 돼서 다른 하나의 학습이 진행되지 않는 것
: 예를 들어, Generator가 하나의 정말 진짜 같은 가짜 데이터를 생성한다면, Discriminator는 이를 항상 구별할 수 없어 학습이 더 이상 진행할 수 없다.

References
[1] https://rython.tistory.com/12
[2] https://roytravel.tistory.com/109
[3] https://process-mining.tistory.com/169
[4] https://www.youtube.com/watch?v=odpjk7_tGY0
'Paper Review' 카테고리의 다른 글
GAN History
[paper]
GAN (Generative Adversarial Nets)은 위와 같이 진짜와 동일해 보이는 이미지(노란색 박스)를 생성하는 모델입니다.
2014년 arXive 논문 발표 이후, 다음 그림과 같이 후속 연구들이 계속해서 이어지고 있는 것을 확인할 수 있습니다.
이 포스트에선 GAN부터 시작하여 다양하게 발전한 GAN들을 하나씩 간단하게 살펴보기 위해 작성합니다.
Original GAN
GAN은 서로 다른 두 개의 모델 Generator(생성기)와 Discriminator(판별기)를 적대적으로(Adversarial) 학습시키며 실제 데이터와 비슷한 데이터를 생성합니다.
생성기는 실제(Real) 데이터의 분포를 학습하여 비슷한(Fake) 데이터를 생성하는 모델이며, 판별기는 실제 데이터인지 생성된 비슷한 데이터인지를 구별하는 역할을 합니다.
GAN의 목표는 "실제 데이터의 분포"에 가까운 비슷한 데이터를 생성하는 것이며 이를 판별하지 못하는 경계(0을 가짜 1을 진짜로 하였을 때 0.5)를 만드는 것 입니다.
GAN의 학습 과정
검은 점선 : 실제 데이터의 확률 분포 / 녹색 실선 : 생성기가 만들어낸 데이터의 확률 분포 / 파란 점선 : 판별기의 확률 분포
위 그림처럼 서로 경쟁하면서 학습함으로써, 실제 데이터의 확률 분포와 생성기가 만들어낸 데이터의 확률 분포의 차이가 줄어들어 실제 이미지와 같아지는 원리이다.
따라서 (d)의 단계에서 생성기는 실제 데이터와 매우 흡사하게 이미지를 생성한다는 의미이다.
GAN의 수식
$$ \underset{G}{min} \underset{D}{max} V(D,G) = \mathbb{E}_{x \sim Pdata(x)}[logD(x)] + \mathbb{E}_{z \sim Pz(z)}[log(1-D(G(z)))] $$
G :Generator / D : Discriminator / x : real data 분포 / z : fake data 분포
\(V(D,G)\)는 GAN의 Loss 함수, 목적 함수(Object Function)라고 불립니다.
0을 가짜 데이터 1을 실제 데이터라 하였을 때, \(D\)의 목적은 \(D(x)\)를 최대한 1에 가깝게 만들고, \(D(G(z))\)를 최대한 0에 가깝게 만듦으로써 목적 함수를 최대화 하는 것을 목적으로 합니다. 즉, 가짜 데이터에는 0을 출력하고 실제 데이터에는 1을 출력하도록 하는 것이다.
\(G\)는 \(D(G(z))\)를 최대한 1에 가깝게 만들어 목적 함수를 최소화하는 것을 목적으로 합니다. 즉, \(D\)가 가짜 데이터를 1로 분류하도록 속일 수 있는, 최대한 실제와 가까운 가짜 데이터를 만드는 방향으로 학습하는 것 입니다.
하지만, 위 목적 함수를 활용해서 GAN을 학습하면 실제로는 학습이 잘 되지 않는 경우가 있습니다. 이러한 이유는 \(G\)의 성능이 좋지 않을 때, 해당 목적 함수를 따르면 Gradient가 굉장히 작아서 학습이 빠르게 될 수 없기 때문입니다.
위 그래프에서 \(G\)에 해당하는 부분인 \(log(1-D(G(z)))\)에서 \(D(G(z))\)가 0에 가까울 때, Gradient가 0에 가깝기 때문에 학습이 잘 되지 않을 수 있는 것을 확인할 수 있습니다. 따라서 위의 \(G\) 목적 함수 대신에 \(-log(D(G(z)))\)를 활용합니다.
한계점
Mode-Collapse
: Generator와 Discriminator 중 하나가 너무 학습이 잘 돼서 다른 하나의 학습이 진행되지 않는 것
: 예를 들어, Generator가 하나의 정말 진짜 같은 가짜 데이터를 생성한다면, Discriminator는 이를 항상 구별할 수 없어 학습이 더 이상 진행할 수 없다.
References
[1] https://rython.tistory.com/12
[2] https://roytravel.tistory.com/109
[3] https://process-mining.tistory.com/169
[4] https://www.youtube.com/watch?v=odpjk7_tGY0