
DeConvNet
앞서 설명한 FCN의 한계점으로, 큰 Object의 경우 전체가 아니라 일부분만 정답으로 예측하여 같은 Object여도 다른 Object로 예측하고 작은 Object의 경우 아예 무시하는 문제와 Object의 디테일한 모습이 사라지는 문제를 가지고 있습니다.
논문의 저자는 이러한 문제를 고정된 Receptive Field와 단순한 Deconvolution(Transposed Convolution) 때문이라 하였고 이를 DeconvNet을 통해 해결하였습니다.


Architecture
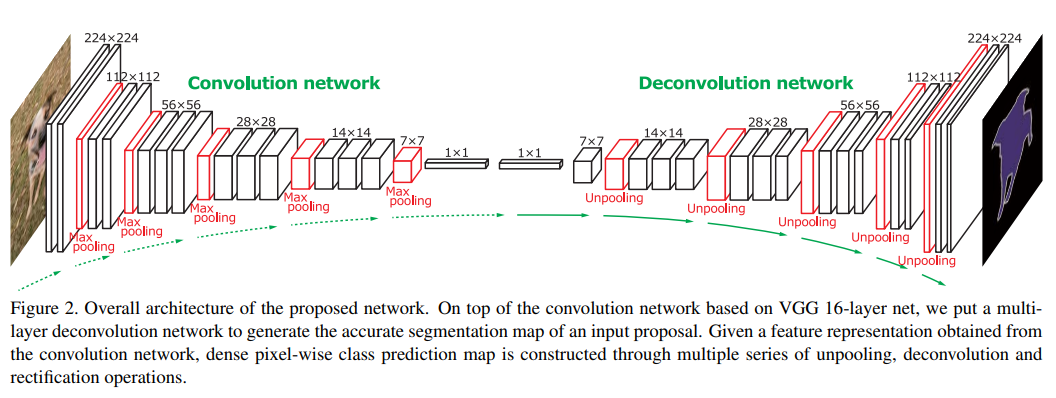
DeconvNet의 구조는 크게 Convolution Network(Encoder)와 Deconvolution Network(Decoder) 부분으로 구성되어 있으며, 대칭적인 특징을 가지고 있습니다. Encoder는 VGG16에서 마지막 Classification Layer를 제거한 형태를 가집니다.

Encoder는 Conv과 Max Pooling 연산을 수행하며 하나의 Conv은 Convolution \(\rightarrow\) BatchNorm \(\rightarrow\) ReLU 구조를 가집니다.
Decoder의 Deconv과 Un Pooling 연산을 수행하며 하나의 Deconv은 Transposed Convolution \(\rightarrow\) BatchNorm \(\rightarrow\) ReLU 구조를 가지고 있습니다.
Un Pooling
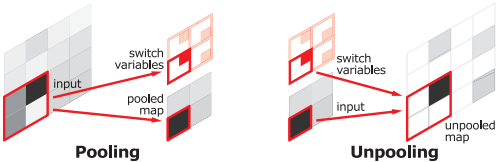
Pooling(Max Pooling)시 노이즈를 제거하는 장점이 있지만, 그 과정에서 많은 정보를 소실한다는 단점을 가지고 있습니다.
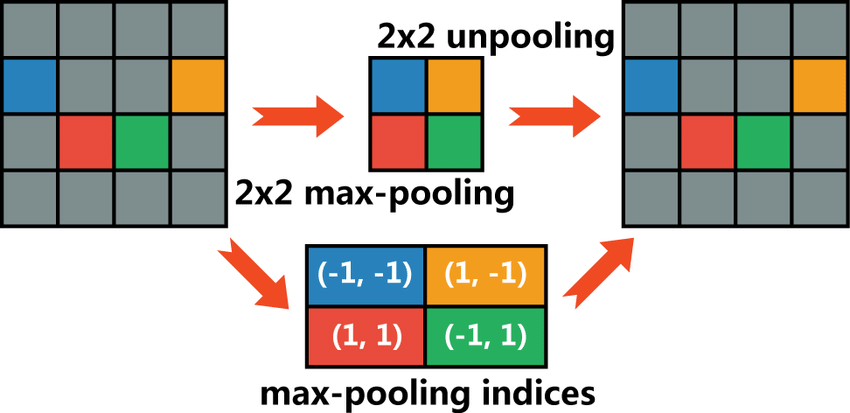
이런 단점을 극복하기 위해, Pooling 시 지워진 경계의 위치 정보를 저장 했다가 Un Pooling 시 이를 사용하여 원본 이미지로 복원합니다. 이는 학습이 필요 없기 때문에 빠른 속도로 처리할 수 있다는 단점이 있지만, 그만큼 메모리도 사용하는 Trade-off 관계를 가집니다.
Deconvolution
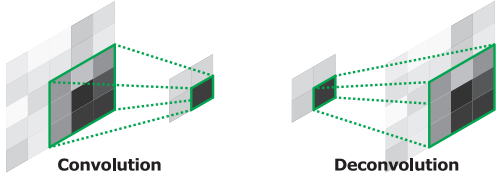
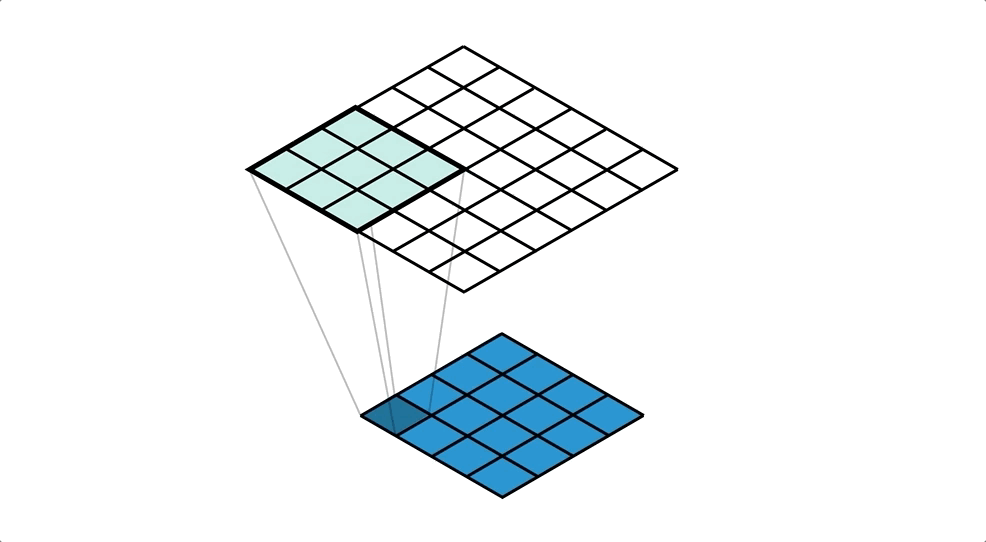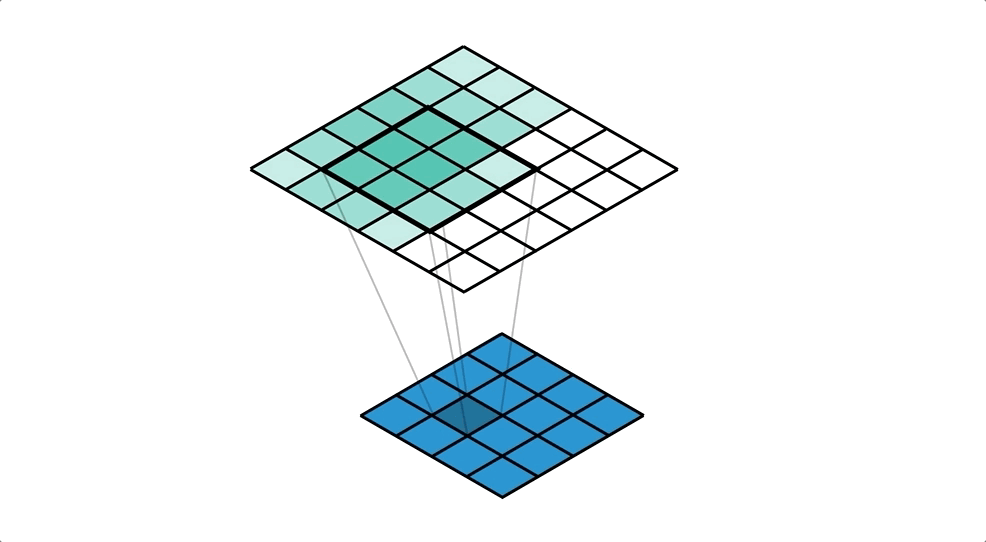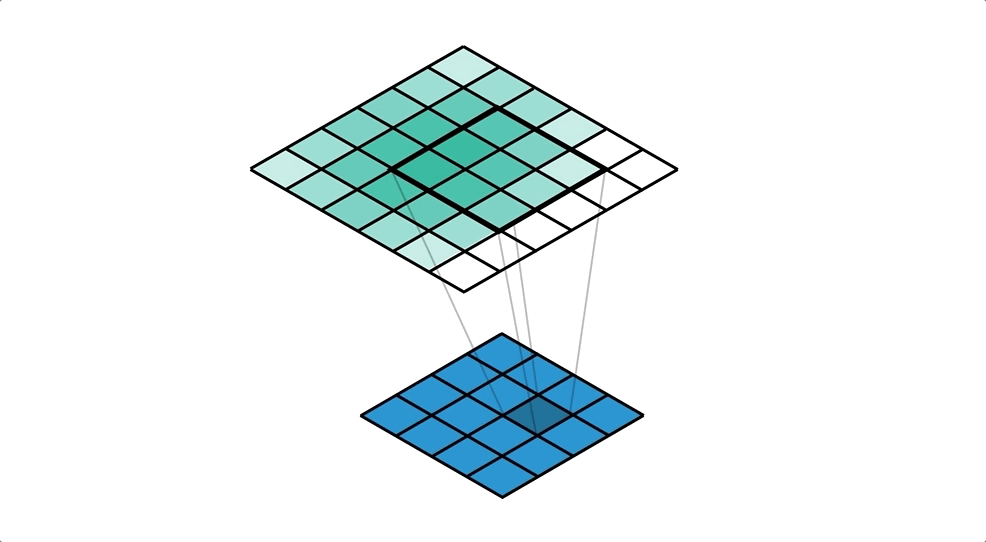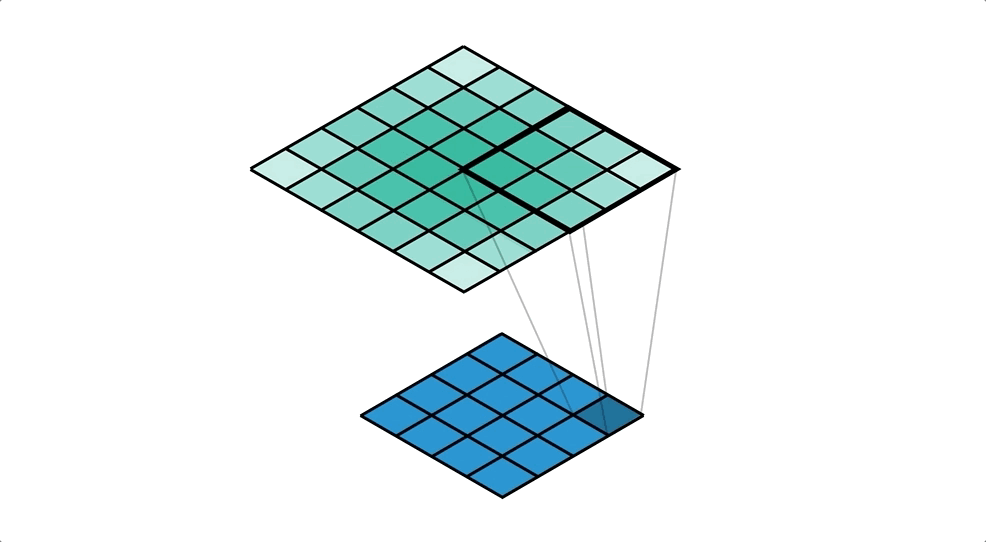
Deconvolution(Transposed Convolution)을 통해 지워진 원본 이미지의 모양을 조금씩 복원합니다. Deconvolution의 낮은 층(Decoder 초반)의 경우 객체의 전반적인 모습을 잡아내고, 깊은 층(Decoder 후반)의 경우 객체의 복잡한 패턴을 잡아냅니다.
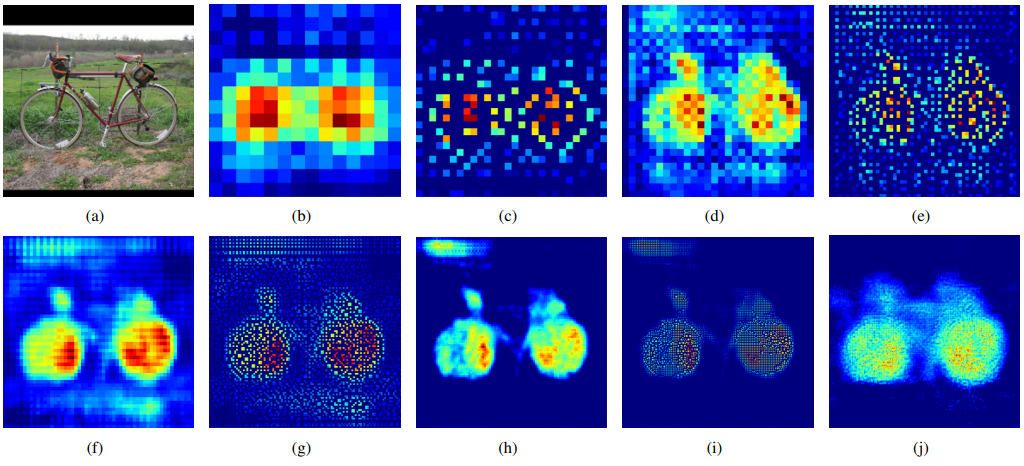
Un Pooling의 경우 위 그림의 (c) (e) (g) (i)로, 객체의 example-specific (자세한 구조)를 잡아내는 것을 확인할 수 있고
Deconvolution의 경우 위 그림의 (b) (d) (f) (h) (j)로, 객체의 class-specific (빈 공간을 채운 자세한 모양)을 잡아내는 것을 확인할 수 있습니다.
구현
class DeconvNet(nn.Module):
def __init__(self, num_classes=len(CLASSES)):
super(DeconvNet, self).__init__()
def CBR(in_channels, out_channels, kernel_size=3, stride=1, padding=1):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
)
def DBR(in_channels, out_channels, kernel_size=3, stride=1, padding=1):
return nn.Sequential(
nn.ConvTranspose2d(in_channels=in_channels, out_channels=out_channels, kernel_size= kernel_size, stride=stride, padding=padding),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
)
# 1 Conv Block : 512 -> 256
self.conv1_1 = CBR(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1)
self.conv1_2 = CBR(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1)
self.conv1_pool = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True, return_indices=True) # return_indices : max pool 하기 전 위치 정보 기억 (Unpooling)
# 2 Conv Block : 256 -> 128
self.conv2_1 = CBR(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1)
self.conv2_2 = CBR(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1)
self.conv2_pool = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True, return_indices=True) # return_indices : max pool 하기 전 위치 정보 기억 (Unpooling)
# 3 Conv Block : 128 -> 64
self.conv3_1 = CBR(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1)
self.conv3_2 = CBR(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1)
self.conv3_3 = CBR(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1)
self.conv3_pool = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True, return_indices=True) # return_indices : max pool 하기 전 위치 정보 기억 (Unpooling)
# 4 Conv Block : 64 -> 32
self.conv4_1 = CBR(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1)
self.conv4_2 = CBR(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
self.conv4_3 = CBR(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
self.conv4_pool = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True, return_indices=True) # return_indices : max pool 하기 전 위치 정보 기억 (Unpooling)
# 5 Conv Block : 32 -> 16
self.conv5_1 = CBR(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
self.conv5_2 = CBR(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
self.conv5_3 = CBR(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
self.conv5_pool = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True, return_indices=True) # return_indices : max pool 하기 전 위치 정보 기억 (Unpooling)
# 6 FC Block : 16 -> 10
self.fc6_1 = CBR(in_channels=512, out_channels=4096, kernel_size=7, stride=1, padding=0)
self.fc6_drop = nn.Dropout2d(0.2)
# 7 FC Block
self.fc7_1 = CBR(in_channels=4096, out_channels=4096, kernel_size=1, stride=1, padding=0)
self.fc7_drop = nn.Dropout2d(0.2)
# 6 Deconv Block : 10 -> 16
self.D_fc6_1 = DBR(in_channels=4096, out_channels=512, kernel_size=7, stride=1, padding=0)
# 5 Deconv Block : 16 -> 32
self.D_conv5_unpool = nn.MaxUnpool2d(kernel_size=2, stride=2)
self.D_conv5_1 = DBR(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
self.D_conv5_2 = DBR(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
self.D_conv5_3 = DBR(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
# 4 Deconv Block : 32 -> 64
self.D_conv4_unpool = nn.MaxUnpool2d(kernel_size=2, stride=2)
self.D_conv4_1 = DBR(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
self.D_conv4_2 = DBR(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
self.D_conv4_3 = DBR(in_channels=512, out_channels=256, kernel_size=3, stride=1, padding=1)
# 3 Deconv Block : 64 -> 128
self.D_conv3_unpool = nn.MaxUnpool2d(kernel_size=2, stride=2)
self.D_conv3_1 = DBR(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1)
self.D_conv3_2 = DBR(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1)
self.D_conv3_3 = DBR(in_channels=256, out_channels=128, kernel_size=3, stride=1, padding=1)
# 2 Deconv Block : 128 -> 256
self.D_conv2_unpool = nn.MaxUnpool2d(kernel_size=2, stride=2)
self.D_conv2_1 = DBR(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1)
self.D_conv2_2 = DBR(in_channels=128, out_channels=64, kernel_size=3, stride=1, padding=1)
# 1 Deconv Block : 256 -> 512
self.D_conv1_unpool = nn.MaxUnpool2d(kernel_size=2, stride=2)
self.D_conv1_1 = DBR(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1)
self.D_conv1_2 = DBR(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1)
# Score
self.score = nn.Conv2d(64, num_classes, kernel_size=1, stride=1, padding=0)
def forward(self, x):
x = self.conv1_1(x)
x = self.conv1_2(x)
x, conv1_pool_indices = self.conv1_pool(x)
x = self.conv2_1(x)
x = self.conv2_2(x)
x, conv2_pool_indices = self.conv2_pool(x)
x = self.conv3_1(x)
x = self.conv3_2(x)
x = self.conv3_3(x)
x, conv3_pool_indices = self.conv3_pool(x)
x = self.conv4_1(x)
x = self.conv4_2(x)
x = self.conv4_3(x)
x, conv4_pool_indices = self.conv4_pool(x)
x = self.conv5_1(x)
x = self.conv5_2(x)
x = self.conv5_3(x)
x, conv5_pool_indices = self.conv5_pool(x)
x = self.fc6_1(x)
x = self.fc6_drop(x)
x = self.fc7_1(x)
x = self.fc7_drop(x)
x = self.D_fc6_1(x)
x = self.D_conv5_unpool(x, conv5_pool_indices)
x = self.D_conv5_1(x)
x = self.D_conv5_2(x)
x = self.D_conv5_3(x)
x = self.D_conv4_unpool(x, conv4_pool_indices)
x = self.D_conv4_1(x)
x = self.D_conv4_2(x)
x = self.D_conv4_3(x)
x = self.D_conv3_unpool(x, conv3_pool_indices)
x = self.D_conv3_1(x)
x = self.D_conv3_2(x)
x = self.D_conv3_3(x)
x = self.D_conv2_unpool(x, conv2_pool_indices)
x = self.D_conv2_1(x)
x = self.D_conv2_2(x)
x = self.D_conv1_unpool(x, conv1_pool_indices)
x = self.D_conv1_1(x)
x = self.D_conv1_2(x)
x = self.score(x)
return x
참고
'Paper Review' 카테고리의 다른 글
| [GAN] Generative Adversarial Nets (0) | 2024.01.30 |
|---|---|
| [SegNet] A Deep ConvolutionalEncoder-Decoder Architecture for ImageSegmentation (0) | 2023.06.08 |
| [FCN] Fully Convolutional Networks for Semantic Segmentation (0) | 2023.03.31 |
| [Transformer] Attention Is All You Need (2) (0) | 2023.03.24 |
| [Transformer] Attention Is All You Need (1) (0) | 2023.03.23 |
DeConvNet
앞서 설명한 FCN의 한계점으로, 큰 Object의 경우 전체가 아니라 일부분만 정답으로 예측하여 같은 Object여도 다른 Object로 예측하고 작은 Object의 경우 아예 무시하는 문제와 Object의 디테일한 모습이 사라지는 문제를 가지고 있습니다.
논문의 저자는 이러한 문제를 고정된 Receptive Field와 단순한 Deconvolution(Transposed Convolution) 때문이라 하였고 이를 DeconvNet을 통해 해결하였습니다.
Architecture
DeconvNet의 구조는 크게 Convolution Network(Encoder)와 Deconvolution Network(Decoder) 부분으로 구성되어 있으며, 대칭적인 특징을 가지고 있습니다. Encoder는 VGG16에서 마지막 Classification Layer를 제거한 형태를 가집니다.
Encoder는 Conv과 Max Pooling 연산을 수행하며 하나의 Conv은 Convolution →→ BatchNorm →→ ReLU 구조를 가집니다.
Decoder의 Deconv과 Un Pooling 연산을 수행하며 하나의 Deconv은 Transposed Convolution →→ BatchNorm →→ ReLU 구조를 가지고 있습니다.
Un Pooling
Pooling(Max Pooling)시 노이즈를 제거하는 장점이 있지만, 그 과정에서 많은 정보를 소실한다는 단점을 가지고 있습니다.
이런 단점을 극복하기 위해, Pooling 시 지워진 경계의 위치 정보를 저장 했다가 Un Pooling 시 이를 사용하여 원본 이미지로 복원합니다. 이는 학습이 필요 없기 때문에 빠른 속도로 처리할 수 있다는 단점이 있지만, 그만큼 메모리도 사용하는 Trade-off 관계를 가집니다.
Deconvolution
Deconvolution(Transposed Convolution)을 통해 지워진 원본 이미지의 모양을 조금씩 복원합니다. Deconvolution의 낮은 층(Decoder 초반)의 경우 객체의 전반적인 모습을 잡아내고, 깊은 층(Decoder 후반)의 경우 객체의 복잡한 패턴을 잡아냅니다.
Un Pooling의 경우 위 그림의 (c) (e) (g) (i)로, 객체의 example-specific (자세한 구조)를 잡아내는 것을 확인할 수 있고
Deconvolution의 경우 위 그림의 (b) (d) (f) (h) (j)로, 객체의 class-specific (빈 공간을 채운 자세한 모양)을 잡아내는 것을 확인할 수 있습니다.
구현
class DeconvNet(nn.Module):
def __init__(self, num_classes=len(CLASSES)):
super(DeconvNet, self).__init__()
def CBR(in_channels, out_channels, kernel_size=3, stride=1, padding=1):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
)
def DBR(in_channels, out_channels, kernel_size=3, stride=1, padding=1):
return nn.Sequential(
nn.ConvTranspose2d(in_channels=in_channels, out_channels=out_channels, kernel_size= kernel_size, stride=stride, padding=padding),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
)
# 1 Conv Block : 512 -> 256
self.conv1_1 = CBR(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1)
self.conv1_2 = CBR(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1)
self.conv1_pool = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True, return_indices=True) # return_indices : max pool 하기 전 위치 정보 기억 (Unpooling)
# 2 Conv Block : 256 -> 128
self.conv2_1 = CBR(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1)
self.conv2_2 = CBR(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1)
self.conv2_pool = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True, return_indices=True) # return_indices : max pool 하기 전 위치 정보 기억 (Unpooling)
# 3 Conv Block : 128 -> 64
self.conv3_1 = CBR(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1)
self.conv3_2 = CBR(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1)
self.conv3_3 = CBR(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1)
self.conv3_pool = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True, return_indices=True) # return_indices : max pool 하기 전 위치 정보 기억 (Unpooling)
# 4 Conv Block : 64 -> 32
self.conv4_1 = CBR(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1)
self.conv4_2 = CBR(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
self.conv4_3 = CBR(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
self.conv4_pool = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True, return_indices=True) # return_indices : max pool 하기 전 위치 정보 기억 (Unpooling)
# 5 Conv Block : 32 -> 16
self.conv5_1 = CBR(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
self.conv5_2 = CBR(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
self.conv5_3 = CBR(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
self.conv5_pool = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True, return_indices=True) # return_indices : max pool 하기 전 위치 정보 기억 (Unpooling)
# 6 FC Block : 16 -> 10
self.fc6_1 = CBR(in_channels=512, out_channels=4096, kernel_size=7, stride=1, padding=0)
self.fc6_drop = nn.Dropout2d(0.2)
# 7 FC Block
self.fc7_1 = CBR(in_channels=4096, out_channels=4096, kernel_size=1, stride=1, padding=0)
self.fc7_drop = nn.Dropout2d(0.2)
# 6 Deconv Block : 10 -> 16
self.D_fc6_1 = DBR(in_channels=4096, out_channels=512, kernel_size=7, stride=1, padding=0)
# 5 Deconv Block : 16 -> 32
self.D_conv5_unpool = nn.MaxUnpool2d(kernel_size=2, stride=2)
self.D_conv5_1 = DBR(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
self.D_conv5_2 = DBR(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
self.D_conv5_3 = DBR(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
# 4 Deconv Block : 32 -> 64
self.D_conv4_unpool = nn.MaxUnpool2d(kernel_size=2, stride=2)
self.D_conv4_1 = DBR(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
self.D_conv4_2 = DBR(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
self.D_conv4_3 = DBR(in_channels=512, out_channels=256, kernel_size=3, stride=1, padding=1)
# 3 Deconv Block : 64 -> 128
self.D_conv3_unpool = nn.MaxUnpool2d(kernel_size=2, stride=2)
self.D_conv3_1 = DBR(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1)
self.D_conv3_2 = DBR(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1)
self.D_conv3_3 = DBR(in_channels=256, out_channels=128, kernel_size=3, stride=1, padding=1)
# 2 Deconv Block : 128 -> 256
self.D_conv2_unpool = nn.MaxUnpool2d(kernel_size=2, stride=2)
self.D_conv2_1 = DBR(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1)
self.D_conv2_2 = DBR(in_channels=128, out_channels=64, kernel_size=3, stride=1, padding=1)
# 1 Deconv Block : 256 -> 512
self.D_conv1_unpool = nn.MaxUnpool2d(kernel_size=2, stride=2)
self.D_conv1_1 = DBR(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1)
self.D_conv1_2 = DBR(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1)
# Score
self.score = nn.Conv2d(64, num_classes, kernel_size=1, stride=1, padding=0)
def forward(self, x):
x = self.conv1_1(x)
x = self.conv1_2(x)
x, conv1_pool_indices = self.conv1_pool(x)
x = self.conv2_1(x)
x = self.conv2_2(x)
x, conv2_pool_indices = self.conv2_pool(x)
x = self.conv3_1(x)
x = self.conv3_2(x)
x = self.conv3_3(x)
x, conv3_pool_indices = self.conv3_pool(x)
x = self.conv4_1(x)
x = self.conv4_2(x)
x = self.conv4_3(x)
x, conv4_pool_indices = self.conv4_pool(x)
x = self.conv5_1(x)
x = self.conv5_2(x)
x = self.conv5_3(x)
x, conv5_pool_indices = self.conv5_pool(x)
x = self.fc6_1(x)
x = self.fc6_drop(x)
x = self.fc7_1(x)
x = self.fc7_drop(x)
x = self.D_fc6_1(x)
x = self.D_conv5_unpool(x, conv5_pool_indices)
x = self.D_conv5_1(x)
x = self.D_conv5_2(x)
x = self.D_conv5_3(x)
x = self.D_conv4_unpool(x, conv4_pool_indices)
x = self.D_conv4_1(x)
x = self.D_conv4_2(x)
x = self.D_conv4_3(x)
x = self.D_conv3_unpool(x, conv3_pool_indices)
x = self.D_conv3_1(x)
x = self.D_conv3_2(x)
x = self.D_conv3_3(x)
x = self.D_conv2_unpool(x, conv2_pool_indices)
x = self.D_conv2_1(x)
x = self.D_conv2_2(x)
x = self.D_conv1_unpool(x, conv1_pool_indices)
x = self.D_conv1_1(x)
x = self.D_conv1_2(x)
x = self.score(x)
return x
참고
'Paper Review' 카테고리의 다른 글
| [GAN] Generative Adversarial Nets (0) | 2024.01.30 |
|---|---|
| [SegNet] A Deep ConvolutionalEncoder-Decoder Architecture for ImageSegmentation (0) | 2023.06.08 |
| [FCN] Fully Convolutional Networks for Semantic Segmentation (0) | 2023.03.31 |
| [Transformer] Attention Is All You Need (2) (0) | 2023.03.24 |
| [Transformer] Attention Is All You Need (1) (0) | 2023.03.23 |