
AlexNet
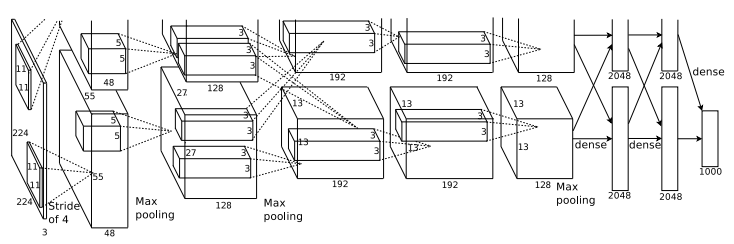
- 8개의 레이어 (5 Convolution Layer, 3 Fully Connected Layer)로 구성
- 해당 논문에서 그림에는 Input Image Size가 224x224x3 으로 나와있지만, 잘못된 표기로 227이 맞습니다.
- ReLU 사용
- Drop out 적용
- Overlapping Pooling
- Local Response Normalization (LRN)
- Data Augmentation
파라미터 계산 방법
\(O\) : Output Size, \(I\) : Input Size, \(S\) : Stride, \(P\) : Padding Size, \(K\) : Num Kernels, \(P_s\) : Pooling Size
Convolution Layer
\(O = \frac{I - K + 2P}{S} + 1\)
Maxpool Layer
\(O = \frac{I - P_s}{s} + 1\)
1 Layer Parameters
Conv1 \(\rightarrow\) ReLU \(\rightarrow\) Maxpool \(\rightarrow\) Local Response Normalization
Conv 1 - \(I\) : 224, \(K\) : 11, \(P\) : None, \(S\) : 4
\(O = \frac{227-11+0}{4} + 1 = 55\)
\(\rightarrow\) 55x55x96
Maxpool - \(I\) : 55, \(P_s\) : 3, \(S\) : 2
\(O = \frac{55-3}{2} + 1 = 27\)
\(\rightarrow\) 27x27x96
2 Layer Parameters
Conv2 \(\rightarrow\) ReLU \(\rightarrow\) Maxpool \(\rightarrow\) Local Response Normalization
Conv 2 - \(I\) : 27, \(K\) : 5, \(P\) : 2, \(S\) : 1
\(O = \frac{27-5+4}{1} + 1 = 27\)
\(\rightarrow\) 27x27x256
Maxpool - \(I\) : 27, \(P_s\) : 3, \(S\) : 2
\(O = \frac{27-3}{2} + 1 = 27\)
\(\rightarrow\) 13x13x256
3 Layer Parameters
Conv3 \(\rightarrow\) ReLU \(\rightarrow\) Conv4 \(\rightarrow\) ReLU \(\rightarrow\) Conv5 \(\rightarrow\) ReLU \(\rightarrow\) Maxpool
Conv 3 - \(I\) : 13, \(K\) : 3, \(P\) : 1, \(S\) : 1
\(O = \frac{13-3+2}{1} + 1 = 13\)
\(\rightarrow\) 13x13x384
Conv 4 - \(I\) : 13, \(K\) : 3, \(P\) : 1, \(S\) : 1
\(O = \frac{13-3+2}{1} + 1 = 13\)
\(\rightarrow\) 13x13x384
Conv 5 - \(I\) : 13, \(K\) : 3, \(P\) : 1, \(S\) : 1
\(O = \frac{13-3+2}{1} + 1 = 13\)
\(\rightarrow\) 13x13x256
Maxpool - \(I\) : 13, \(P_s\) : 3, \(S\) : 2
\(O = \frac{13-3}{2} + 1 = 6\)
\(\rightarrow\) 6x6x256
4 Layer Parameters
Fc6 \(\rightarrow\) ReLU \(\rightarrow\) Fc7 \(\rightarrow\) ReLU \(\rightarrow\) Fc8 \(\rightarrow\) ReLU
6x6x256=9216개의 1차원 벡터로 Flatten 후 4096개의 뉴런과 Fully Connected
4096개의 뉴런과 4096개의 뉴련 Fully Connected
4096개의 뉴런과 1000개의 뉴런 Fully Connected
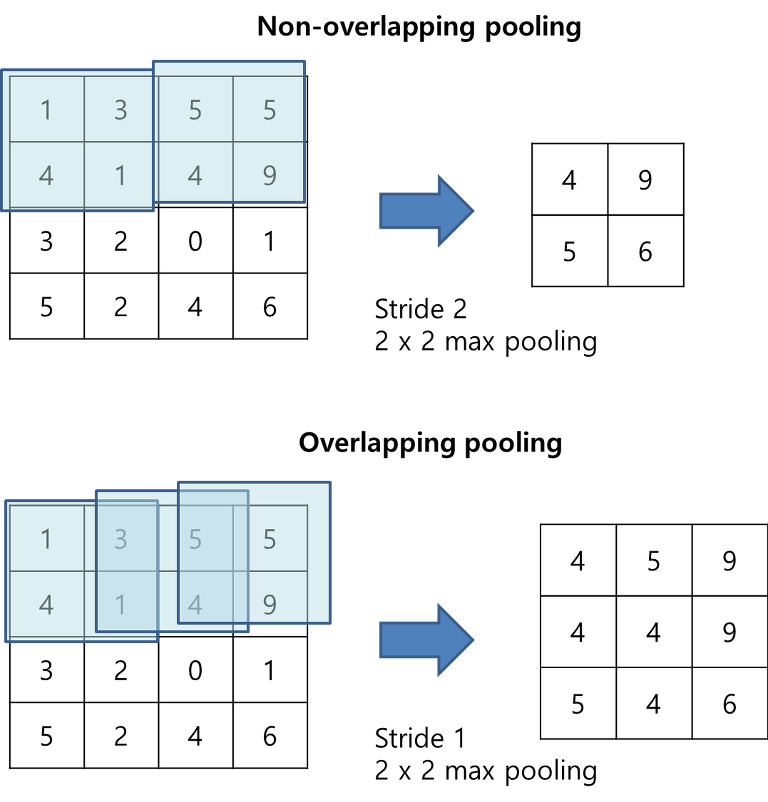
Overlapping Pooling
Local Response Normalisation (LRN)
Batch Normalization이 등정하기 전, 이를 대신해 측면 억제(Lateral inhibition)을 하기 위해 사용.
이를 사용한 이유는 ReLU의 사용으로 양수의 값을 그대로 사용하기 때문에 Conv 또는 Pooling 시 매우 높은 Pixel값이 나올 수 있기 떄문에 이를 방지하기 위해 다른 ActivationMap의 같은 위치에 있는 Pixel끼리 정규화 하는 방법
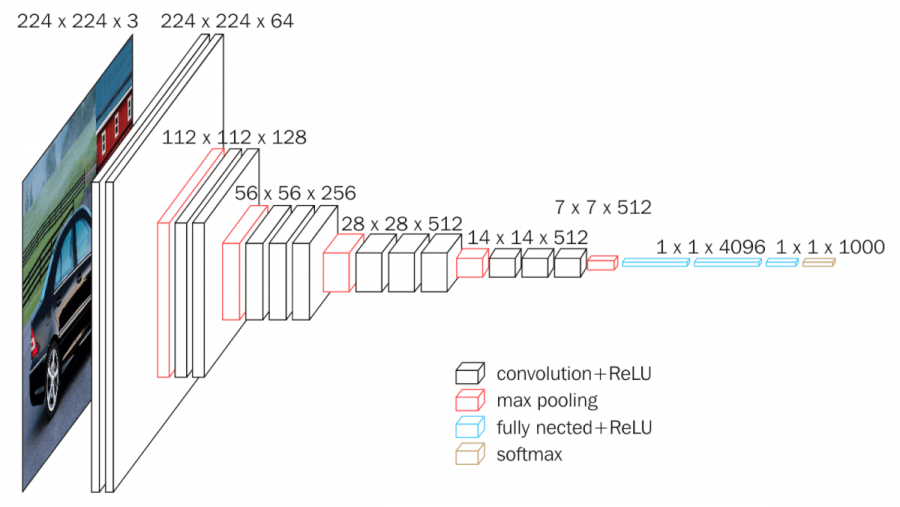
VGG Net
- AlexNet에 비해 많은 Layer를 쌓음 하지만, 기본적인 구조는 AlexNet을 많이 따라감
- 여러 Conv Filter를 통과하다 보면 Receptive Filed는 넓어지게 되어있어서, AlexNet과 다르게 3x3 Conv Filter를 사용함
- 2x2 Max Pooling 사용
- Local Response Normalization (LRN) 미사용
3x3 Conv Filter를 사용하는 이유
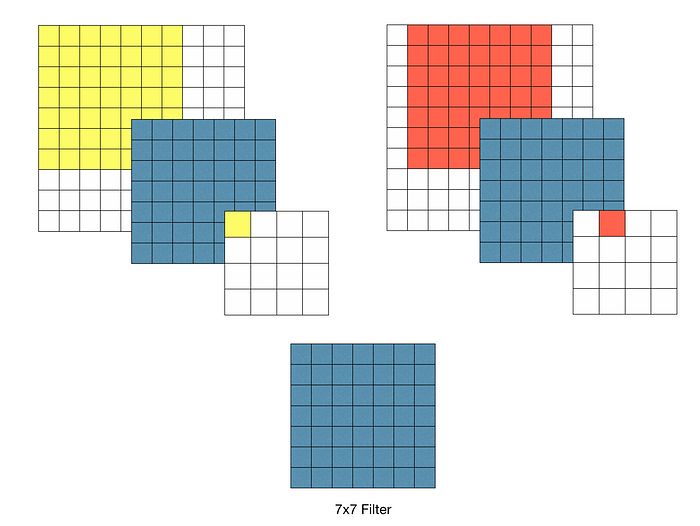
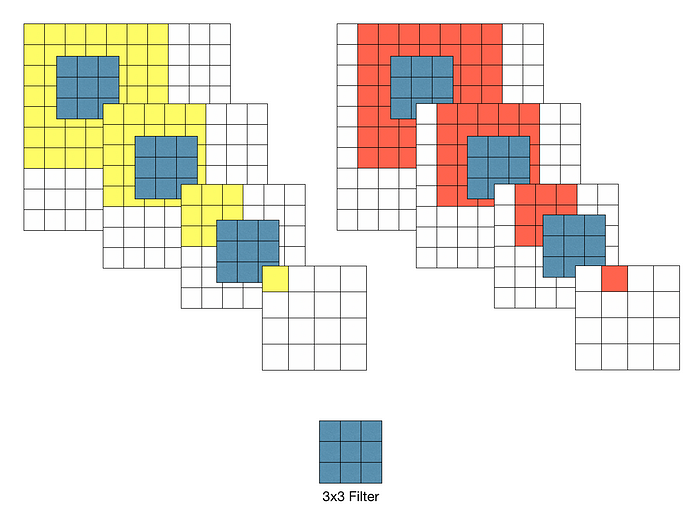
위 그림처럼 여러 층을 사용하게 되면 Recepted Filed는 차이가 없을 뿐더러, 각 Conv 연산은 진행 후 ReLU를 포함한다. 따라서 여러 층을 사용하게 되면 비선형성이 증가하여 모델의 특징을 잘 표현할 수 있게 된다. 또한, 7x7 Filter에 비해 3x3 Filter는 더 적은 파라미터를 사용하여 비용 측면에서도 이점을 가진다.
GoogLe Net
- VGG Net 보다 더 깊은 네트워크, 더 깊지만 파라미터 수는 더 작다.
- 파라미터의 수를 줄이기 위해 Fully Connected Layer를 생략
- Inception Module 사용
- Auxiliary Classifier
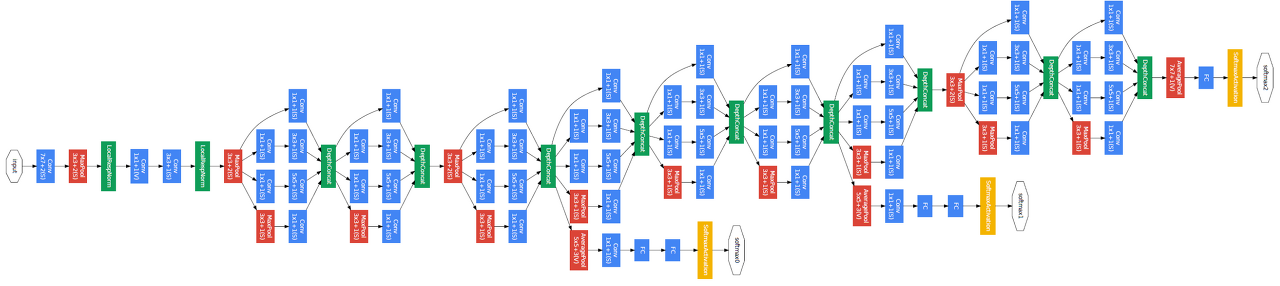
Inception Module
다음 그래프는CS231n 강의노트를 참고하였습니다.
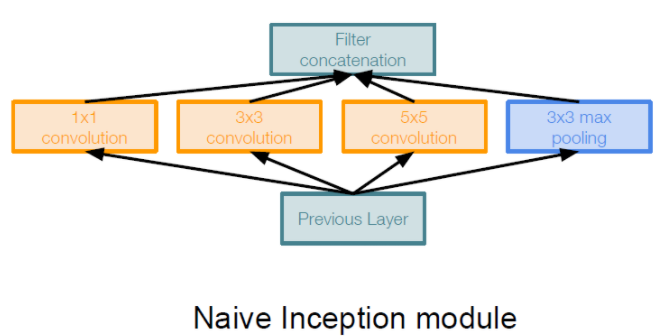
논문 저자가 우선적으로 생각한 방법은 같은 입력을 받는 여러 개의 필터들이 병렬적으로 존재하고, 그 결과를 합치는 방법을 생각했습니다. 하지만 이러한 구조로 만들게 된다면 파라미터의 숫자가 매우 늘어나 오히려 학습에 방해가 됩니다.
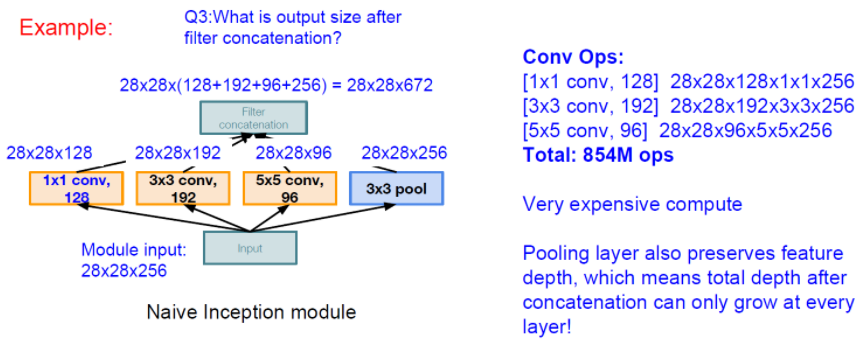
이러한 방법을 해결하기 위해 다음과 같이 1x1 Convolution Layer를 사용합니다.
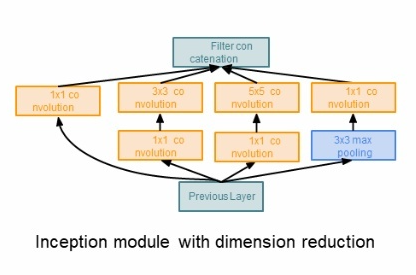
비록 정보의 손실이 존재하지만 결국, 학습을 더 잘하게 됩니다. 파라미터의 개수를 확인해보면,

위 그림과 같이 2배 이상 줄어든 것을 확인할 수 있습니다.
Auxiliary Classifier
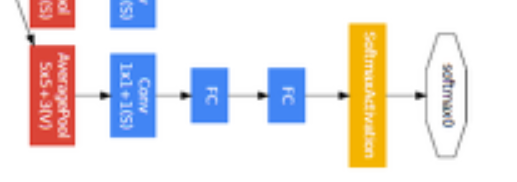
중간 중간에 나오는 다음과 같은 구조이다.
네트워크를 너무 깊게 쌓으면 Backpropagation을 진행하면서 Vanishing Gradient 문제가 흔히 일어난다.
그래서 Gradient를 중간 중간에 넣어주기 위해 도입한 기법이다.
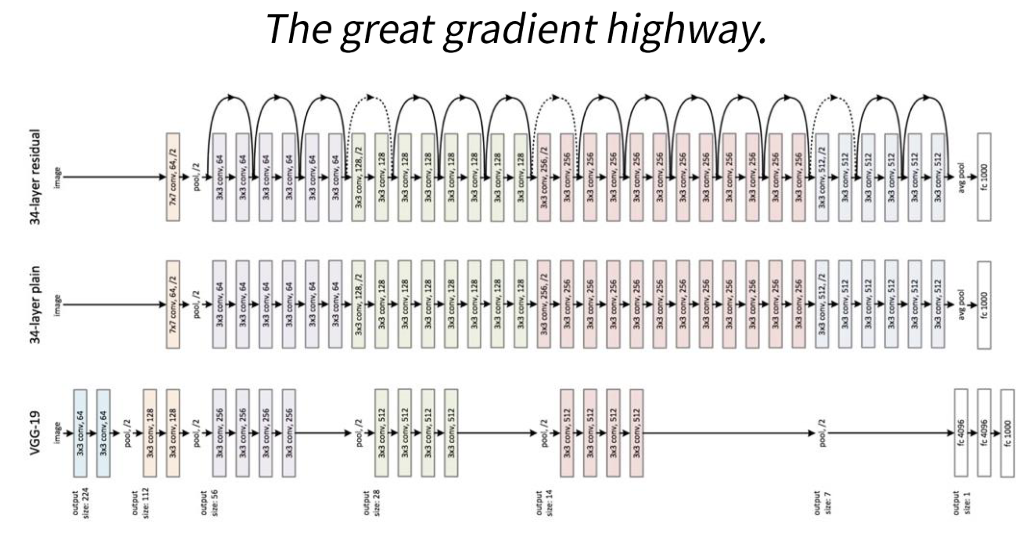
ResNet
- 네트워크가 더욱 깊어져 152개 층으로 구성되어 있습니다.
- 네트워크가 깊다고해서 성능이 좋은것은 아닙니다. (Degradation problem)
- Residual Block 구조를 사용하였다.
- He initialization을 사용하였다.
Degradation Problem
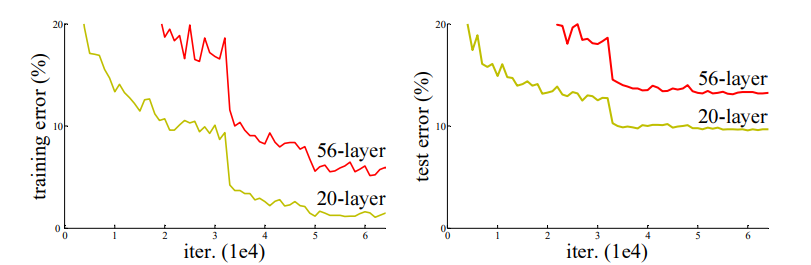
위 그림처럼 층을 많이 쌓는다고 해서 성능이 좋아지는 것이 아니다.
흔히 발생하는 Overfitting 문제가 아니다. (Train, Test error가 모두 낮기 때문에)
이를 해결하기 위해 다음 Residual Block 방법이 고안되었다.
Residual Block
잔여 학습 또는 잔차 학습 이라고 부른다.
Residual Block을 사용하는 이유는 Vanishing or Exploding Gradients 문제를 해결하기 위해서이다.
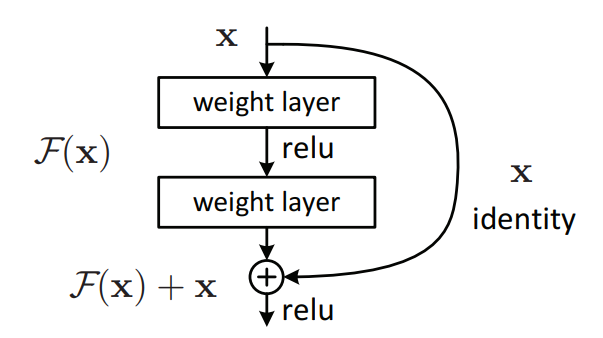
위 그림과 같은 구조로 입력으로 들어온 값(x, Identity) 과 Convolution 연산을 거친 값(F(x))을 더하여 ReLU를 통과한다.
이러한 방식을 Shortcut 또는 Skip Connection이라고도 부른다.
이러한 방식을 사용하는 이유는 연산이 진행되면서 자기 자신의 정보를 잃어버리지 않게(보존) 하기 위해서입니다.
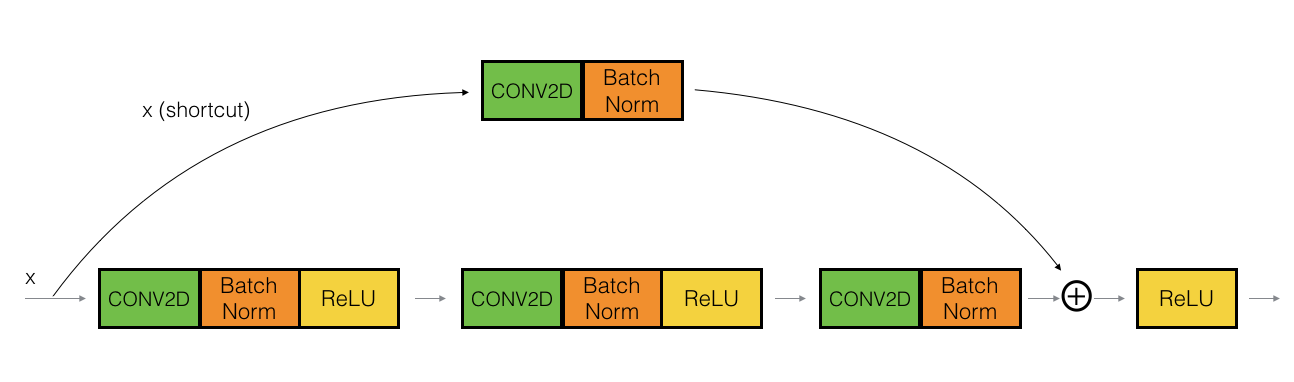
세부 연산은 다음 그림과 같다.
다음 그림처럼 입력(x)값과 Convolution 연산을 거친 값(F(x))의 차원이 같지 않을 경우 입력(x) 값에 Convolution 연산을 진행하여 차원을 같게 만들수도 있다.
Bottleneck Architecture
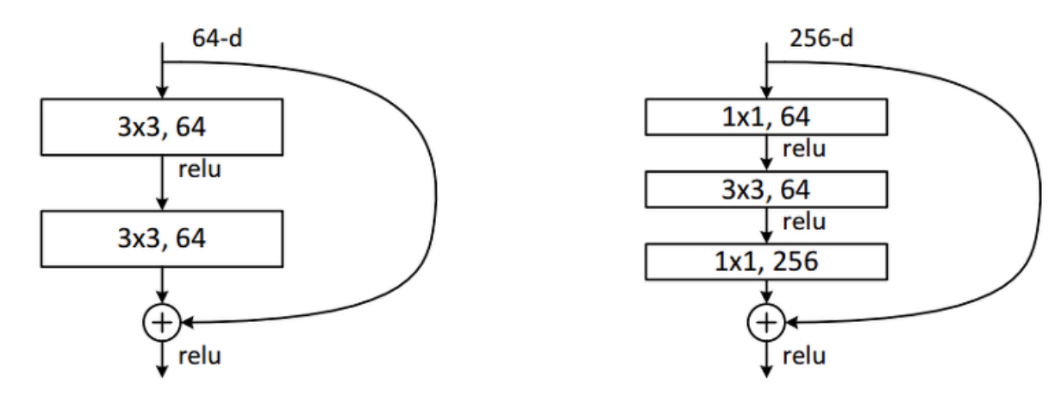
기본적인 Residual 구조에서 조금 변형한 구조이다.
ResNet 50층 이상의 구조에서 사용되며, 1x1 Convolution을 적용하여 구성하였고, Demention의 감소와 확장 효과를 주어 연산 시간 감소의 성능을 얻을 수 있다.
Identity Mapping
ResNet을 약간 개선한 논문으로 Residual 구조가 약간 수정되었다.
기존에는 한 단위의 Feature Map을 추출하고 난 후 Activation Function(ReLU)를 적용하는게 일반적이였는데, 이를 적용하지 않고 그냥 더하는 구조를 가진다.
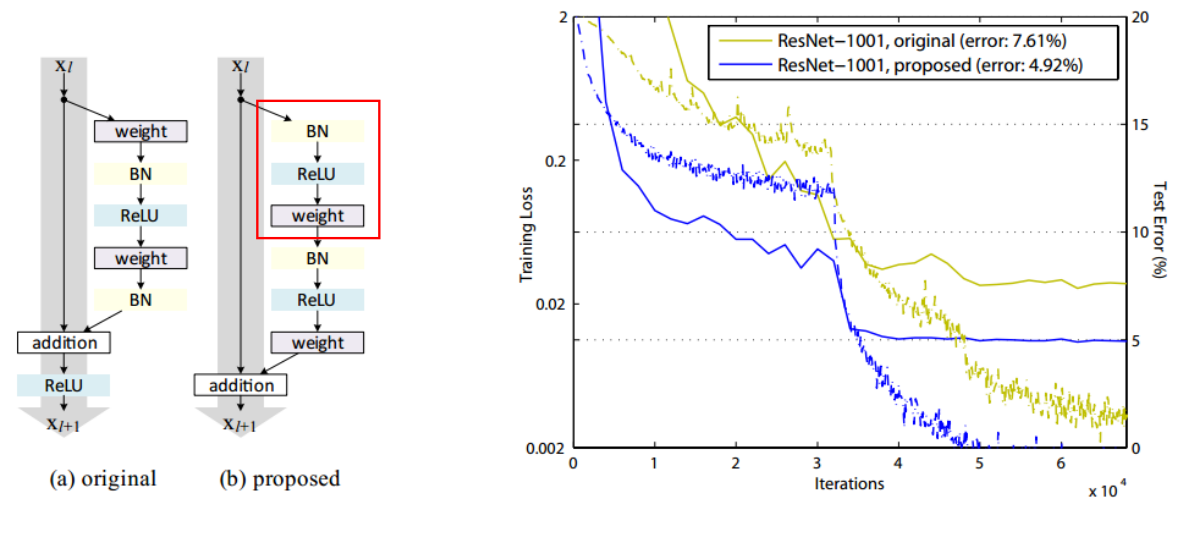
'ML & DL > Deep Learning' 카테고리의 다른 글
| WBF, Ensemble for Object Detection 정리 (0) | 2023.05.19 |
|---|---|
| NMS, Soft-NMS 정리 및 구현 (0) | 2023.05.19 |
| Mixup 정리 및 구현 (0) | 2023.04.27 |
| 1 x 1 Convolution ? (0) | 2023.03.22 |
| Albumentations 사용법 및 예시 (0) | 2022.05.23 |
AlexNet
- 8개의 레이어 (5 Convolution Layer, 3 Fully Connected Layer)로 구성
- 해당 논문에서 그림에는 Input Image Size가 224x224x3 으로 나와있지만, 잘못된 표기로 227이 맞습니다.
- ReLU 사용
- Drop out 적용
- Overlapping Pooling
- Local Response Normalization (LRN)
- Data Augmentation
파라미터 계산 방법
\(O\) : Output Size, \(I\) : Input Size, \(S\) : Stride, \(P\) : Padding Size, \(K\) : Num Kernels, \(P_s\) : Pooling Size
Convolution Layer
\(O = \frac{I - K + 2P}{S} + 1\)
Maxpool Layer
\(O = \frac{I - P_s}{s} + 1\)
1 Layer Parameters
Conv1 \(\rightarrow\) ReLU \(\rightarrow\) Maxpool \(\rightarrow\) Local Response Normalization
Conv 1 - \(I\) : 224, \(K\) : 11, \(P\) : None, \(S\) : 4
\(O = \frac{227-11+0}{4} + 1 = 55\)
\(\rightarrow\) 55x55x96
Maxpool - \(I\) : 55, \(P_s\) : 3, \(S\) : 2
\(O = \frac{55-3}{2} + 1 = 27\)
\(\rightarrow\) 27x27x96
2 Layer Parameters
Conv2 \(\rightarrow\) ReLU \(\rightarrow\) Maxpool \(\rightarrow\) Local Response Normalization
Conv 2 - \(I\) : 27, \(K\) : 5, \(P\) : 2, \(S\) : 1
\(O = \frac{27-5+4}{1} + 1 = 27\)
\(\rightarrow\) 27x27x256
Maxpool - \(I\) : 27, \(P_s\) : 3, \(S\) : 2
\(O = \frac{27-3}{2} + 1 = 27\)
\(\rightarrow\) 13x13x256
3 Layer Parameters
Conv3 \(\rightarrow\) ReLU \(\rightarrow\) Conv4 \(\rightarrow\) ReLU \(\rightarrow\) Conv5 \(\rightarrow\) ReLU \(\rightarrow\) Maxpool
Conv 3 - \(I\) : 13, \(K\) : 3, \(P\) : 1, \(S\) : 1
\(O = \frac{13-3+2}{1} + 1 = 13\)
\(\rightarrow\) 13x13x384
Conv 4 - \(I\) : 13, \(K\) : 3, \(P\) : 1, \(S\) : 1
\(O = \frac{13-3+2}{1} + 1 = 13\)
\(\rightarrow\) 13x13x384
Conv 5 - \(I\) : 13, \(K\) : 3, \(P\) : 1, \(S\) : 1
\(O = \frac{13-3+2}{1} + 1 = 13\)
\(\rightarrow\) 13x13x256
Maxpool - \(I\) : 13, \(P_s\) : 3, \(S\) : 2
\(O = \frac{13-3}{2} + 1 = 6\)
\(\rightarrow\) 6x6x256
4 Layer Parameters
Fc6 \(\rightarrow\) ReLU \(\rightarrow\) Fc7 \(\rightarrow\) ReLU \(\rightarrow\) Fc8 \(\rightarrow\) ReLU
6x6x256=9216개의 1차원 벡터로 Flatten 후 4096개의 뉴런과 Fully Connected
4096개의 뉴런과 4096개의 뉴련 Fully Connected
4096개의 뉴런과 1000개의 뉴런 Fully Connected
Overlapping Pooling
Local Response Normalisation (LRN)
Batch Normalization이 등정하기 전, 이를 대신해 측면 억제(Lateral inhibition)을 하기 위해 사용.
이를 사용한 이유는 ReLU의 사용으로 양수의 값을 그대로 사용하기 때문에 Conv 또는 Pooling 시 매우 높은 Pixel값이 나올 수 있기 떄문에 이를 방지하기 위해 다른 ActivationMap의 같은 위치에 있는 Pixel끼리 정규화 하는 방법
VGG Net
- AlexNet에 비해 많은 Layer를 쌓음 하지만, 기본적인 구조는 AlexNet을 많이 따라감
- 여러 Conv Filter를 통과하다 보면 Receptive Filed는 넓어지게 되어있어서, AlexNet과 다르게 3x3 Conv Filter를 사용함
- 2x2 Max Pooling 사용
- Local Response Normalization (LRN) 미사용
3x3 Conv Filter를 사용하는 이유
위 그림처럼 여러 층을 사용하게 되면 Recepted Filed는 차이가 없을 뿐더러, 각 Conv 연산은 진행 후 ReLU를 포함한다. 따라서 여러 층을 사용하게 되면 비선형성이 증가하여 모델의 특징을 잘 표현할 수 있게 된다. 또한, 7x7 Filter에 비해 3x3 Filter는 더 적은 파라미터를 사용하여 비용 측면에서도 이점을 가진다.
GoogLe Net
- VGG Net 보다 더 깊은 네트워크, 더 깊지만 파라미터 수는 더 작다.
- 파라미터의 수를 줄이기 위해 Fully Connected Layer를 생략
- Inception Module 사용
- Auxiliary Classifier
Inception Module
다음 그래프는CS231n 강의노트를 참고하였습니다.
논문 저자가 우선적으로 생각한 방법은 같은 입력을 받는 여러 개의 필터들이 병렬적으로 존재하고, 그 결과를 합치는 방법을 생각했습니다. 하지만 이러한 구조로 만들게 된다면 파라미터의 숫자가 매우 늘어나 오히려 학습에 방해가 됩니다.
이러한 방법을 해결하기 위해 다음과 같이 1x1 Convolution Layer를 사용합니다.
비록 정보의 손실이 존재하지만 결국, 학습을 더 잘하게 됩니다. 파라미터의 개수를 확인해보면,
위 그림과 같이 2배 이상 줄어든 것을 확인할 수 있습니다.
Auxiliary Classifier
중간 중간에 나오는 다음과 같은 구조이다.
네트워크를 너무 깊게 쌓으면 Backpropagation을 진행하면서 Vanishing Gradient 문제가 흔히 일어난다.
그래서 Gradient를 중간 중간에 넣어주기 위해 도입한 기법이다.
ResNet
- 네트워크가 더욱 깊어져 152개 층으로 구성되어 있습니다.
- 네트워크가 깊다고해서 성능이 좋은것은 아닙니다. (Degradation problem)
- Residual Block 구조를 사용하였다.
- He initialization을 사용하였다.
Degradation Problem
위 그림처럼 층을 많이 쌓는다고 해서 성능이 좋아지는 것이 아니다.
흔히 발생하는 Overfitting 문제가 아니다. (Train, Test error가 모두 낮기 때문에)
이를 해결하기 위해 다음 Residual Block 방법이 고안되었다.
Residual Block
잔여 학습 또는 잔차 학습 이라고 부른다.
Residual Block을 사용하는 이유는 Vanishing or Exploding Gradients 문제를 해결하기 위해서이다.
위 그림과 같은 구조로 입력으로 들어온 값(x, Identity) 과 Convolution 연산을 거친 값(F(x))을 더하여 ReLU를 통과한다.
이러한 방식을 Shortcut 또는 Skip Connection이라고도 부른다.
이러한 방식을 사용하는 이유는 연산이 진행되면서 자기 자신의 정보를 잃어버리지 않게(보존) 하기 위해서입니다.
세부 연산은 다음 그림과 같다.
다음 그림처럼 입력(x)값과 Convolution 연산을 거친 값(F(x))의 차원이 같지 않을 경우 입력(x) 값에 Convolution 연산을 진행하여 차원을 같게 만들수도 있다.
Bottleneck Architecture
기본적인 Residual 구조에서 조금 변형한 구조이다.
ResNet 50층 이상의 구조에서 사용되며, 1x1 Convolution을 적용하여 구성하였고, Demention의 감소와 확장 효과를 주어 연산 시간 감소의 성능을 얻을 수 있다.
Identity Mapping
ResNet을 약간 개선한 논문으로 Residual 구조가 약간 수정되었다.
기존에는 한 단위의 Feature Map을 추출하고 난 후 Activation Function(ReLU)를 적용하는게 일반적이였는데, 이를 적용하지 않고 그냥 더하는 구조를 가진다.
'ML & DL > Deep Learning' 카테고리의 다른 글
| WBF, Ensemble for Object Detection 정리 (0) | 2023.05.19 |
|---|---|
| NMS, Soft-NMS 정리 및 구현 (0) | 2023.05.19 |
| Mixup 정리 및 구현 (0) | 2023.04.27 |
| 1 x 1 Convolution ? (0) | 2023.03.22 |
| Albumentations 사용법 및 예시 (0) | 2022.05.23 |