
HDF5
HDF란, 대용량의 데이터를 저장하기 위한 파일 형식으로, 구조화된 배열 데이터를 저장하기에 용이하다.
운영체제의 제약을 거의 받지 않고, 대용량 데이터를 빠르게 저장하고, 쉽게 접근할 수 있게 해주는 고성능 데이터 포맷 형식이다.
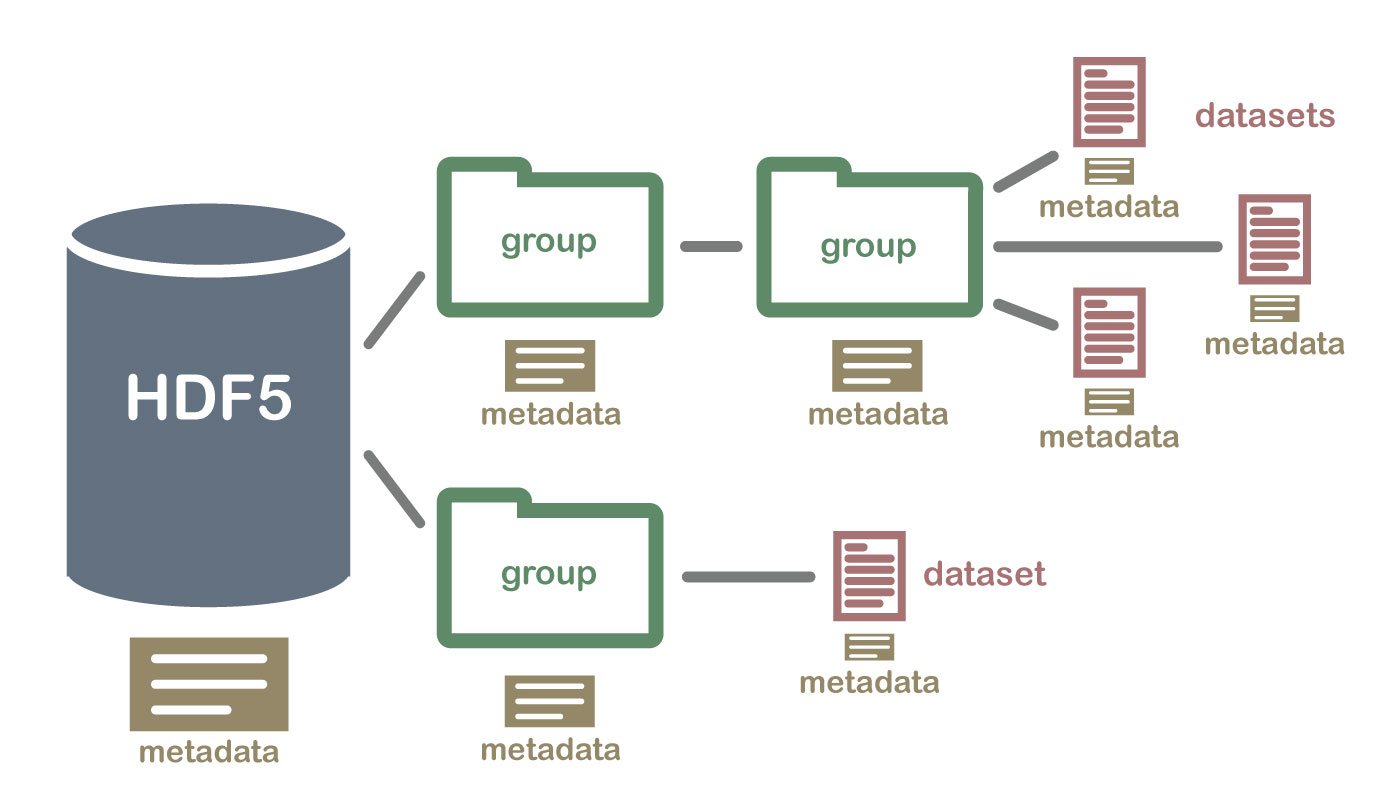
HDF5를 사용하는 이유
- 특정 데이터 subset을 처리하기 위해서 전체 데이터셋을 RAM에 읽지 않아, 아주 효율적으로 데이터를 처리할 수 있다.
- 다른 타입들을 가진 데이터들을 HDF5라는 하나의 파일 안에 저장할 수 있다.
h5py
python에서는 h5py 라이브러리로 HDF5 파일을 쉽게 다룰 수 있다. [docs]
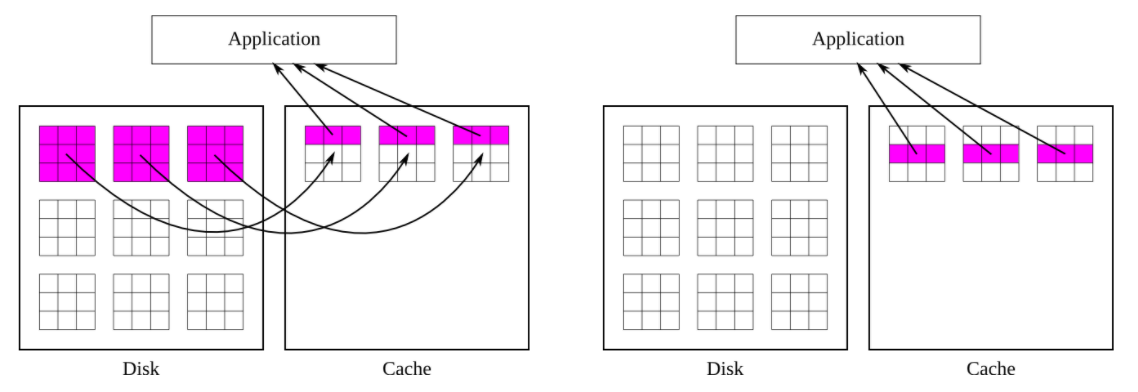
위에서 HDF5를 사용하는 이유에서 설명했듯이, 위 그림의 오른쪽 부분 처럼 HDF5는 임의의 데이터를 참조했을 때, 해당 데이터가 메모리에 올라가 있으면 메모리에서 바로 참조할 수 있습니다.
설치
pip install h5py
생성
import os
import h5py
from glob import glob
from PIL import Image
import matplotlib.pyplot as plt
images_path = '../data/train'
hdf5_file = '../data/train.h5py'
# rdcc ? : https://docs.h5py.org/en/stable/high/file.html?highlight=rdcc#chunk-cache
with h5py.File(hdf5_file, 'w', rdcc_nslots=11213, rdcc_nbytes=1024**3, rdcc_w0=1) as hf:
for idx, image_path in enumerate(glob(os.path.join(images_path, '*'))):
image = Image.open(images)
"""
image 전처리
"""
iset = hf.create_dataset(f'{idx}/image',
data=image,
shape=(image.height, image.width, 3), # Height, Width, Channels
compression='gzip',
compression_opts=9,
chunks=True)
"""
Label도 똑같이 적용 가능
"""
# Check !
with h5py.File(hdf5_file, 'r') as hf:
plt.imshow(hf["0"]["i"])
로드
import h5py
import torch
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self, root_dir, to_tensor=True):
self.root_dir = root_dir
self.file = None
def __getitem__(self, idx):
if self.file is None:
self.file = h5py.File(self.root_dir, 'r')
image = self.file[str(idx)]["i"]
image = torch.Tensor(image)
return image
def __len__(self):
with h5py.File(self.root_dir, 'r') as hf:
return len(hf.keys())
위와 코드와 같이 로드를 비효율적으로 하는 이유 [참고]
TypeError: h5py objects cannot be pickled
hdf5 파일을 load하고 dataset에서 불러올 때 num_workers가 0 이상이면 multiprocessing 부분에서 처리할 때 충돌이 일어나기 때문입니다.
'ML & DL > Practice' 카테고리의 다른 글
| 간단한 Airflow 환경 구축 (dockerfile) (0) | 2024.12.31 |
|---|---|
| docker-compose로 Airflow 환경 구축 (0) | 2024.12.27 |
| YOLO v8 사용하기 (ultralytics) (0) | 2023.05.20 |
| [MMDetection 2.0] 정리 (0) | 2023.05.16 |
| [MMDetection 3.0] 정리 (0) | 2023.05.12 |
HDF5
HDF란, 대용량의 데이터를 저장하기 위한 파일 형식으로, 구조화된 배열 데이터를 저장하기에 용이하다.
운영체제의 제약을 거의 받지 않고, 대용량 데이터를 빠르게 저장하고, 쉽게 접근할 수 있게 해주는 고성능 데이터 포맷 형식이다.
HDF5를 사용하는 이유
- 특정 데이터 subset을 처리하기 위해서 전체 데이터셋을 RAM에 읽지 않아, 아주 효율적으로 데이터를 처리할 수 있다.
- 다른 타입들을 가진 데이터들을 HDF5라는 하나의 파일 안에 저장할 수 있다.
h5py
python에서는 h5py 라이브러리로 HDF5 파일을 쉽게 다룰 수 있다. [docs]
위에서 HDF5를 사용하는 이유에서 설명했듯이, 위 그림의 오른쪽 부분 처럼 HDF5는 임의의 데이터를 참조했을 때, 해당 데이터가 메모리에 올라가 있으면 메모리에서 바로 참조할 수 있습니다.
설치
pip install h5py
생성
import os
import h5py
from glob import glob
from PIL import Image
import matplotlib.pyplot as plt
images_path = '../data/train'
hdf5_file = '../data/train.h5py'
# rdcc ? : https://docs.h5py.org/en/stable/high/file.html?highlight=rdcc#chunk-cache
with h5py.File(hdf5_file, 'w', rdcc_nslots=11213, rdcc_nbytes=1024**3, rdcc_w0=1) as hf:
for idx, image_path in enumerate(glob(os.path.join(images_path, '*'))):
image = Image.open(images)
"""
image 전처리
"""
iset = hf.create_dataset(f'{idx}/image',
data=image,
shape=(image.height, image.width, 3), # Height, Width, Channels
compression='gzip',
compression_opts=9,
chunks=True)
"""
Label도 똑같이 적용 가능
"""
# Check !
with h5py.File(hdf5_file, 'r') as hf:
plt.imshow(hf["0"]["i"])
로드
import h5py
import torch
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self, root_dir, to_tensor=True):
self.root_dir = root_dir
self.file = None
def __getitem__(self, idx):
if self.file is None:
self.file = h5py.File(self.root_dir, 'r')
image = self.file[str(idx)]["i"]
image = torch.Tensor(image)
return image
def __len__(self):
with h5py.File(self.root_dir, 'r') as hf:
return len(hf.keys())
위와 코드와 같이 로드를 비효율적으로 하는 이유 [참고]
TypeError: h5py objects cannot be pickled
hdf5 파일을 load하고 dataset에서 불러올 때 num_workers가 0 이상이면 multiprocessing 부분에서 처리할 때 충돌이 일어나기 때문입니다.
'ML & DL > Practice' 카테고리의 다른 글
| 간단한 Airflow 환경 구축 (dockerfile) (0) | 2024.12.31 |
|---|---|
| docker-compose로 Airflow 환경 구축 (0) | 2024.12.27 |
| YOLO v8 사용하기 (ultralytics) (0) | 2023.05.20 |
| [MMDetection 2.0] 정리 (0) | 2023.05.16 |
| [MMDetection 3.0] 정리 (0) | 2023.05.12 |