
torch.nn
PyTorch에서 신경망 모델을 구현하는 데 필요한 여러 가지 클래스와 함수를 제공해주는 모듈입니다.
nn.Linear
선형 변환(Linear Transformation)을 수행하는 클래스입니다.
nn.Linear를 사용하여 tensor의 크기 or 모양을 반환합니다.
# 입력 텐서의 차원은 5이고, 출력 텐서의 차원은 3인 nn.Linear 모듈을 생성합니다.
linear_layer = nn.Linear(5, 3)
# 입력 텐서를 생성합니다.
input_tensor = torch.randn((2, 5))
# nn.Linear 모듈을 통해 입력 텐서를 출력 텐서로 변환합니다.
output_tensor = linear_layer(input_tensor)
print(output_tensor.shape)
# torch.Size([2, 3])참고) nn.Linear와 nn.LazyLinear의 차이
nn.Identity
이 모듈은 입력값을 그대로 출력값으로 반환하는 모듈입니다.
대부분 모델의 아키텍처를 구성할 떄 입력값을 그대로 출력값으로 전달해야하는 경우,
모델의 일부분을 다른 모델로 대체할 떄 입력값과 출력값의 크기를 맞추기위해 사용하는 경우,
모델을 구성할 때 일부 레이어의 연산을 스킵(생략)할 때 사용하는 경우에 이용됩니다.
import torch.nn as nn
import torch
# 입력값 그대로 출력하는 모듈 정의
identity = nn.Identity()
# 입력값을 그대로 출력하는 신경망 구성
model = nn.Sequential(
nn.Linear(3, 64),
nn.ReLU(),
nn.Linear(64, 1),
identity # 입력값 그대로 출력하는 모듈 적용
)
# 예시 입력값 정의
x = torch.randn(2, 3)
# 모델에 입력값을 전달하여 출력값 확인
y = model(x)
print(y)
# tensor([[-0.1491],
# [-0.3779]], grad_fn=<AddmmBackward0>)
nn.Module ★ 중요!
nn.Module 클래스는 모델을 구성할 때 사용하는 핵심으로, 여러 기능들을 한 곳에 모아주는 상자(block) 역할을 합니다.
그래서 nn.Module이라는 상자 안에 nn.Module을 포함할 수도 있습니다.
nn.Module이라는 상자에 기능들을 가득 모아둔 경우를 basic building block,
nn.Module이라는 상자에 basic building block인 nn.Module 가득 모아둔 경우를 딥러닝 모델 이라 칭할 수 있습니다.
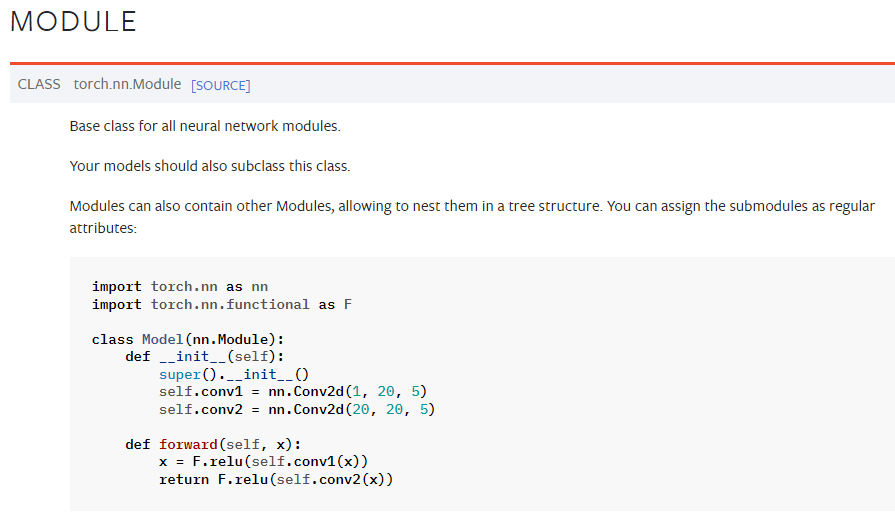
nn.Module 클래스들은 다양한 메서드의 속성을 사용할 수 있습니다.
- __init__ : 블록의 초기화를 담당하는 메서드입니다. 모델의 구조를 정의하고, 모델에 필요한 레이어와 변수들을 초기화 합니다.
- forward : 모델의 순전파(forward pass) 연산을 담당하는 메서드입니다. 모델의 입력값을 받아 연산을 수행하고 출력값을 반환합니다.
'nn.Module' 클래스를 상속받은 클래스를 정의할 때, 반드시 'super().__init__'을 호출하여 'nn.Module'의 초기화 메서드를 실행해야 합니다. 또한 'nn.Module'의 하위 클래스에서 정의한 레이어나 다른 모듈들은 모두 'nn.Module' 클래스를 상속받아야 합니다.
다양한 예제




- parameter : torch.Tensor의 하위 클래스로, 모델 파라미터를 나타내는데 사용됩니다. 이는 모델 파라미터로서 자동으로 추적되고, 그레이디언트 및 역전파 알고리즘에 사용됩니다.
import torch
from torch import nn
from torch.nn.parameter import Parameter
class Linear(nn.Module):
def __init__(self, in_features, out_features):
super().__init__()
self.W = Parameter(nn.init.ones_(torch.empty(out_features, in_features)))
self.b = Parameter(nn.init.ones_(torch.empty(out_features)))
def forward(self, x):
output = torch.addmm(self.b, x, self.W.T)
return output
x = torch.Tensor([[1, 2],
[3, 4]])
linear = Linear(2, 3)
output = linear(x)
# tensor([[4., 4., 4.],
# [8., 8., 8.]], grad_fn=<AddmmBackward0>)- buffer : 일반적인 Tensor는 Parameter와 다르게 그레이디언트를 계산하지 않아 값이 업데이트 되지 않고, 모델을 저장할 때 무시됩니다. 하지만 이 Tensor를 저장하고 싶을때 buffer를 사용합니다.
import torch
from torch import nn
from torch.nn.parameter import Parameter
class Model(nn.Module):
def __init__(self):
super().__init__()
self.parameter = Parameter(torch.Tensor([7]))
self.tensor = torch.Tensor([7])
# TODO : torch.Tensor([7])를 buffer이라는 이름으로 buffer에 등록해보세요!
self.register_buffer('buffer', torch.Tensor([7]))
model = Model()
buffer = model.get_buffer('buffer')
print(model.state_dict())
# OrderedDict([('parameter', tensor([7.])), ('buffer', tensor([7.]))])
이를 기반으로 다음 글에 nn.Module에 대해 조금 더 자세히 살펴보도록 하겠습니다.
'ML & DL > PyTorch' 카테고리의 다른 글
| [PyTorch] Dataset & DataLoader (0) | 2023.03.15 |
|---|---|
| [PyTorch] nn.Module (0) | 2023.03.15 |
| [PyTorch] Optimization, 최적화 (0) | 2023.03.13 |
| [PyTorch] Autograd, 자동 미분 (0) | 2023.03.13 |
| [PyTorch] DATASET과 DATALOADER (0) | 2023.03.13 |
torch.nn
PyTorch에서 신경망 모델을 구현하는 데 필요한 여러 가지 클래스와 함수를 제공해주는 모듈입니다.
nn.Linear
선형 변환(Linear Transformation)을 수행하는 클래스입니다.
nn.Linear를 사용하여 tensor의 크기 or 모양을 반환합니다.
# 입력 텐서의 차원은 5이고, 출력 텐서의 차원은 3인 nn.Linear 모듈을 생성합니다.
linear_layer = nn.Linear(5, 3)
# 입력 텐서를 생성합니다.
input_tensor = torch.randn((2, 5))
# nn.Linear 모듈을 통해 입력 텐서를 출력 텐서로 변환합니다.
output_tensor = linear_layer(input_tensor)
print(output_tensor.shape)
# torch.Size([2, 3])
참고) nn.Linear와 nn.LazyLinear의 차이
nn.Identity
이 모듈은 입력값을 그대로 출력값으로 반환하는 모듈입니다.
대부분 모델의 아키텍처를 구성할 떄 입력값을 그대로 출력값으로 전달해야하는 경우,
모델의 일부분을 다른 모델로 대체할 떄 입력값과 출력값의 크기를 맞추기위해 사용하는 경우,
모델을 구성할 때 일부 레이어의 연산을 스킵(생략)할 때 사용하는 경우에 이용됩니다.
import torch.nn as nn
import torch
# 입력값 그대로 출력하는 모듈 정의
identity = nn.Identity()
# 입력값을 그대로 출력하는 신경망 구성
model = nn.Sequential(
nn.Linear(3, 64),
nn.ReLU(),
nn.Linear(64, 1),
identity # 입력값 그대로 출력하는 모듈 적용
)
# 예시 입력값 정의
x = torch.randn(2, 3)
# 모델에 입력값을 전달하여 출력값 확인
y = model(x)
print(y)
# tensor([[-0.1491],
# [-0.3779]], grad_fn=<AddmmBackward0>)
nn.Module ★ 중요!
nn.Module 클래스는 모델을 구성할 때 사용하는 핵심으로, 여러 기능들을 한 곳에 모아주는 상자(block) 역할을 합니다.
그래서 nn.Module이라는 상자 안에 nn.Module을 포함할 수도 있습니다.
nn.Module이라는 상자에 기능들을 가득 모아둔 경우를 basic building block,
nn.Module이라는 상자에 basic building block인 nn.Module 가득 모아둔 경우를 딥러닝 모델 이라 칭할 수 있습니다.
nn.Module 클래스들은 다양한 메서드의 속성을 사용할 수 있습니다.
- __init__ : 블록의 초기화를 담당하는 메서드입니다. 모델의 구조를 정의하고, 모델에 필요한 레이어와 변수들을 초기화 합니다.
- forward : 모델의 순전파(forward pass) 연산을 담당하는 메서드입니다. 모델의 입력값을 받아 연산을 수행하고 출력값을 반환합니다.
'nn.Module' 클래스를 상속받은 클래스를 정의할 때, 반드시 'super().__init__'을 호출하여 'nn.Module'의 초기화 메서드를 실행해야 합니다. 또한 'nn.Module'의 하위 클래스에서 정의한 레이어나 다른 모듈들은 모두 'nn.Module' 클래스를 상속받아야 합니다.
다양한 예제
- parameter : torch.Tensor의 하위 클래스로, 모델 파라미터를 나타내는데 사용됩니다. 이는 모델 파라미터로서 자동으로 추적되고, 그레이디언트 및 역전파 알고리즘에 사용됩니다.
import torch
from torch import nn
from torch.nn.parameter import Parameter
class Linear(nn.Module):
def __init__(self, in_features, out_features):
super().__init__()
self.W = Parameter(nn.init.ones_(torch.empty(out_features, in_features)))
self.b = Parameter(nn.init.ones_(torch.empty(out_features)))
def forward(self, x):
output = torch.addmm(self.b, x, self.W.T)
return output
x = torch.Tensor([[1, 2],
[3, 4]])
linear = Linear(2, 3)
output = linear(x)
# tensor([[4., 4., 4.],
# [8., 8., 8.]], grad_fn=<AddmmBackward0>)- buffer : 일반적인 Tensor는 Parameter와 다르게 그레이디언트를 계산하지 않아 값이 업데이트 되지 않고, 모델을 저장할 때 무시됩니다. 하지만 이 Tensor를 저장하고 싶을때 buffer를 사용합니다.
import torch
from torch import nn
from torch.nn.parameter import Parameter
class Model(nn.Module):
def __init__(self):
super().__init__()
self.parameter = Parameter(torch.Tensor([7]))
self.tensor = torch.Tensor([7])
# TODO : torch.Tensor([7])를 buffer이라는 이름으로 buffer에 등록해보세요!
self.register_buffer('buffer', torch.Tensor([7]))
model = Model()
buffer = model.get_buffer('buffer')
print(model.state_dict())
# OrderedDict([('parameter', tensor([7.])), ('buffer', tensor([7.]))])
이를 기반으로 다음 글에 nn.Module에 대해 조금 더 자세히 살펴보도록 하겠습니다.
'ML & DL > PyTorch' 카테고리의 다른 글
| [PyTorch] Dataset & DataLoader (0) | 2023.03.15 |
|---|---|
| [PyTorch] nn.Module (0) | 2023.03.15 |
| [PyTorch] Optimization, 최적화 (0) | 2023.03.13 |
| [PyTorch] Autograd, 자동 미분 (0) | 2023.03.13 |
| [PyTorch] DATASET과 DATALOADER (0) | 2023.03.13 |